 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-RNN: A Recurrent Language Model for Memory Updates and Sequence Prediction
Jan 19, 2026Large language models are strong sequence predictors, yet standard inference relies on immutable context histories. After making an error at generation step t, the model lacks an updatable memory mechanism that improves predictions for step t+1. We propose LLM-as-RNN, an inference-only framework that turns a frozen LLM into a recurrent predictor by representing its hidden state as natural-language memory. This state, implemented as a structured system-prompt summary, is updated at each timestep via feedback-driven text rewrites, enabling learning without parameter updates. Under a fixed token budget, LLM-as-RNN corrects errors and retains task-relevant patterns, effectively performing online learning through language. We evaluate the method on three sequential benchmarks in healthcare, meteorology, and finance across Llama, Gemma, and GPT model families. LLM-as-RNN significantly outperforms zero-shot, full-history, and MemPrompt baselines, improving predictive accuracy by 6.5% on average, while producing interpretable, human-readable learning traces absent in standard context accumulation.
Importance Weighted Score Matching for Diffusion Samplers with Enhanced Mode Coverage
May 26, 2025Training neural samplers directly from unnormalized densities without access to target distribution samples presents a significant challenge. A critical desideratum in these settings is achieving comprehensive mode coverage, ensuring the sampler captures the full diversity of the target distribution. However, prevailing methods often circumvent the lack of target data by optimizing reverse KL-based objectives. Such objectives inherently exhibit mode-seeking behavior, potentially leading to incomplete representation of the underlying distribution. While alternative approaches strive for better mode coverage, they typically rely on implicit mechanisms like heuristics or iterative refinement. In this work, we propose a principled approach for training diffusion-based samplers by directly targeting an objective analogous to the forward KL divergence, which is conceptually known to encourage mode coverage. We introduce \textit{Importance Weighted Score Matching}, a method that optimizes this desired mode-covering objective by re-weighting the score matching loss using tractable importance sampling estimates, thereby overcoming the absence of target distribution data. We also provide theoretical analysis of the bias and variance for our proposed Monte Carlo estimator and the practical loss function used in our method. Experiments on increasingly complex multi-modal distributions, including 2D Gaussian Mixture Models with up to 120 modes and challenging particle systems with inherent symmetries -- demonstrate that our approach consistently outperforms existing neural samplers across all distributional distance metrics, achieving state-of-the-art results on all benchmarks.
FlexiDrop: Theoretical Insights and Practical Advances in Random Dropout Method on GNNs
May 30, 2024



Graph Neural Networks (GNNs) are powerful tools for handling graph-type data. Recently, GNNs have been widely applied in various domains, but they also face some issues, such as overfitting, over-smoothing and non-robustness. The existing research indicates that random dropout methods are an effective way to address these issues. However, random dropout methods in GNNs still face unresolved problems. Currently, the choice of dropout rate, often determined by heuristic or grid search methods, can increase the generalization error, contradicting the principal aims of dropout. In this paper, we propose a novel random dropout method for GNNs called FlexiDrop. First, we conduct a theoretical analysis of dropout in GNNs using rademacher complexity and demonstrate that the generalization error of traditional random dropout methods is constrained by a function related to the dropout rate. Subsequently, we use this function as a regularizer to unify the dropout rate and empirical loss within a single loss function, optimizing them simultaneously. Therefore, our method enables adaptive adjustment of the dropout rate and theoretically balances the trade-off between model complexity and generalization ability. Furthermore, extensive experimental results on benchmark datasets show that FlexiDrop outperforms traditional random dropout methods in GNNs.
Graph Neural Aggregation-diffusion with Metastability
Mar 29, 2024



Continuous graph neural models based on differential equations have expanded the architecture of graph neural networks (GNNs). Due to the connection between graph diffusion and message passing, diffusion-based models have been widely studied. However, diffusion naturally drives the system towards an equilibrium state, leading to issues like over-smoothing. To this end, we propose GRADE inspired by graph aggregation-diffusion equations, which includes the delicate balance between nonlinear diffusion and aggregation induced by interaction potentials. The node representations obtained through aggregation-diffusion equations exhibit metastability, indicating that features can aggregate into multiple clusters. In addition, the dynamics within these clusters can persist for long time periods, offering the potential to alleviate over-smoothing effects. This nonlinear diffusion in our model generalizes existing diffusion-based models and establishes a connection with classical GNNs. We prove that GRADE achieves competitive performance across various benchmarks and alleviates the over-smoothing issue in GNNs evidenced by the enhanced Dirichlet energy.
Understanding Oversmoothing in Diffusion-Based GNNs From the Perspective of Operator Semigroup Theory
Feb 23, 2024



This paper presents a novel study of the oversmoothing issue in diffusion-based Graph Neural Networks (GNNs). Diverging from extant approaches grounded in random walk analysis or particle systems, we approach this problem through operator semigroup theory. This theoretical framework allows us to rigorously prove that oversmoothing is intrinsically linked to the ergodicity of the diffusion operator. This finding further poses a general and mild ergodicity-breaking condition, encompassing the various specific solutions previously offered, thereby presenting a more universal and theoretically grounded approach to mitigating oversmoothing in diffusion-based GNNs. Additionally, we offer a probabilistic interpretation of our theory, forging a link with prior works and broadening the theoretical horizon. Our experimental results reveal that this ergodicity-breaking term effectively mitigates oversmoothing measured by Dirichlet energy, and simultaneously enhances performance in node classification tasks.
Improved Naive Bayes with Mislabeled Data
Apr 13, 2023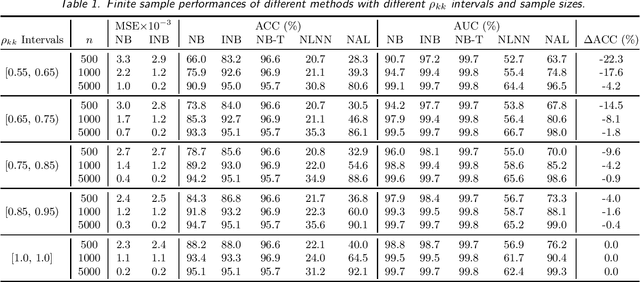
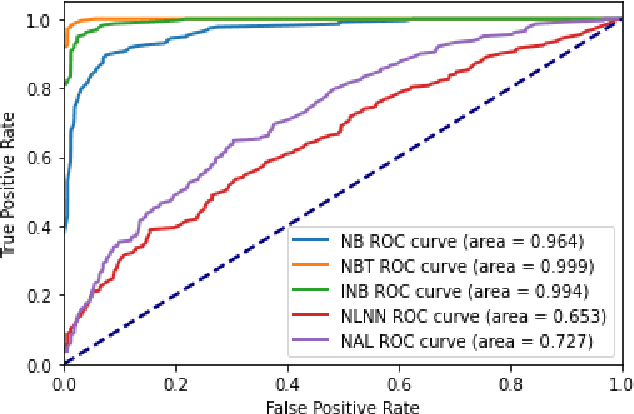

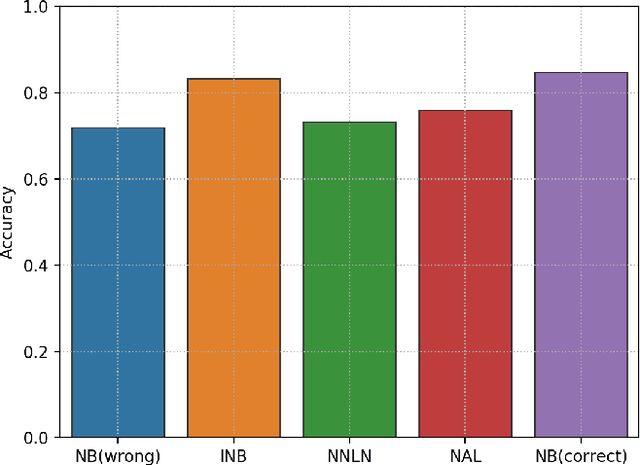
Labeling mistakes are frequently encountered in real-world applications. If not treated well, the labeling mistakes can deteriorate the classification performances of a model seriously. To address this issue, we propose an improved Naive Bayes method for text classification. It is analytically simple and free of subjective judgements on the correct and incorrect labels. By specifying the generating mechanism of incorrect labels, we optimize the corresponding log-likelihood function iteratively by using an EM algorithm. Our simulation and experiment results show that the improved Naive Bayes method greatly improves the performances of the Naive Bayes method with mislabeled data.
Analysis of Graph Neural Networks with Theory of Markov Chains
Nov 12, 2022



In this paper, we provide a theoretical tool for the interpretation and analysis of \emph{graph neural networks} (GNNs). We use Markov chains on graphs to mathematically model the forward propagation processes of GNNs. The graph neural networks are divided into two classes of operator-consistent and operator-inconsistent based on whether the Markov chains are time-homogeneous. Based on this, we study \emph{over-smoothing} which is an important problem in GNN research. We attribute the over-smoothing problem to the convergence of an arbitrary initial distribution to a stationary distribution. We prove the effectiveness of the previous methods for alleviating the over-smoothing problem. Further, we give the conclusion that operator-consistent GNN cannot avoid over-smoothing at an exponential rate in the Markovian sense. For operator-inconsistent GNN, we theoretically give a sufficient condition for avoiding over-smoothing. Based on this condition, we propose a regularization term which can be flexibly added to the training of the neural network. Finally, we design experiments to verify the effectiveness of this condition. Results show that our proposed sufficient condition not only improves the performance but also alleviates the over-smoothing phenomenon.