 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurve-Aware Gaussian Splatting for 3D Parametric Curve Reconstruction
Jun 26, 2025This paper presents an end-to-end framework for reconstructing 3D parametric curves directly from multi-view edge maps. Contrasting with existing two-stage methods that follow a sequential ``edge point cloud reconstruction and parametric curve fitting'' pipeline, our one-stage approach optimizes 3D parametric curves directly from 2D edge maps, eliminating error accumulation caused by the inherent optimization gap between disconnected stages. However, parametric curves inherently lack suitability for rendering-based multi-view optimization, necessitating a complementary representation that preserves their geometric properties while enabling differentiable rendering. We propose a novel bi-directional coupling mechanism between parametric curves and edge-oriented Gaussian components. This tight correspondence formulates a curve-aware Gaussian representation, \textbf{CurveGaussian}, that enables differentiable rendering of 3D curves, allowing direct optimization guided by multi-view evidence. Furthermore, we introduce a dynamically adaptive topology optimization framework during training to refine curve structures through linearization, merging, splitting, and pruning operations. Comprehensive evaluations on the ABC dataset and real-world benchmarks demonstrate our one-stage method's superiority over two-stage alternatives, particularly in producing cleaner and more robust reconstructions. Additionally, by directly optimizing parametric curves, our method significantly reduces the parameter count during training, achieving both higher efficiency and superior performance compared to existing approaches.
Sparse Autoencoders, Again?
Jun 06, 2025



Is there really much more to say about sparse autoencoders (SAEs)? Autoencoders in general, and SAEs in particular, represent deep architectures that are capable of modeling low-dimensional latent structure in data. Such structure could reflect, among other things, correlation patterns in large language model activations, or complex natural image manifolds. And yet despite the wide-ranging applicability, there have been relatively few changes to SAEs beyond the original recipe from decades ago, namely, standard deep encoder/decoder layers trained with a classical/deterministic sparse regularizer applied within the latent space. One possible exception is the variational autoencoder (VAE), which adopts a stochastic encoder module capable of producing sparse representations when applied to manifold data. In this work we formalize underappreciated weaknesses with both canonical SAEs, as well as analogous VAEs applied to similar tasks, and propose a hybrid alternative model that circumvents these prior limitations. In terms of theoretical support, we prove that global minima of our proposed model recover certain forms of structured data spread across a union of manifolds. Meanwhile, empirical evaluations on synthetic and real-world datasets substantiate the efficacy of our approach in accurately estimating underlying manifold dimensions and producing sparser latent representations without compromising reconstruction error. In general, we are able to exceed the performance of equivalent-capacity SAEs and VAEs, as well as recent diffusion models where applicable, within domains such as images and language model activation patterns.
CAD-NeRF: Learning NeRFs from Uncalibrated Few-view Images by CAD Model Retrieval
Nov 05, 2024Reconstructing from multi-view images is a longstanding problem in 3D vision, where neural radiance fields (NeRFs) have shown great potential and get realistic rendered images of novel views. Currently, most NeRF methods either require accurate camera poses or a large number of input images, or even both. Reconstructing NeRF from few-view images without poses is challenging and highly ill-posed. To address this problem, we propose CAD-NeRF, a method reconstructed from less than 10 images without any known poses. Specifically, we build a mini library of several CAD models from ShapeNet and render them from many random views. Given sparse-view input images, we run a model and pose retrieval from the library, to get a model with similar shapes, serving as the density supervision and pose initializations. Here we propose a multi-view pose retrieval method to avoid pose conflicts among views, which is a new and unseen problem in uncalibrated NeRF methods. Then, the geometry of the object is trained by the CAD guidance. The deformation of the density field and camera poses are optimized jointly. Then texture and density are trained and fine-tuned as well. All training phases are in self-supervised manners. Comprehensive evaluations of synthetic and real images show that CAD-NeRF successfully learns accurate densities with a large deformation from retrieved CAD models, showing the generalization abilities.
Relighting Scenes with Object Insertions in Neural Radiance Fields
Jun 21, 2024The insertion of objects into a scene and relighting are commonly utilized applications in augmented reality (AR). Previous methods focused on inserting virtual objects using CAD models or real objects from single-view images, resulting in highly limited AR application scenarios. We propose a novel NeRF-based pipeline for inserting object NeRFs into scene NeRFs, enabling novel view synthesis and realistic relighting, supporting physical interactions like casting shadows onto each other, from two sets of images depicting the object and scene. The lighting environment is in a hybrid representation of Spherical Harmonics and Spherical Gaussians, representing both high- and low-frequency lighting components very well, and supporting non-Lambertian surfaces. Specifically, we leverage the benefits of volume rendering and introduce an innovative approach for efficient shadow rendering by comparing the depth maps between the camera view and the light source view and generating vivid soft shadows. The proposed method achieves realistic relighting effects in extensive experimental evaluations.
A Selective Review on Statistical Methods for Massive Data Computation: Distributed Computing, Subsampling, and Minibatch Techniques
Mar 17, 2024This paper presents a selective review of statistical computation methods for massive data analysis. A huge amount of statistical methods for massive data computation have been rapidly developed in the past decades. In this work, we focus on three categories of statistical computation methods: (1) distributed computing, (2) subsampling methods, and (3) minibatch gradient techniques. The first class of literature is about distributed computing and focuses on the situation, where the dataset size is too huge to be comfortably handled by one single computer. In this case, a distributed computation system with multiple computers has to be utilized. The second class of literature is about subsampling methods and concerns about the situation, where the sample size of dataset is small enough to be placed on one single computer but too large to be easily processed by its memory as a whole. The last class of literature studies those minibatch gradient related optimization techniques, which have been extensively used for optimizing various deep learning models.
Improved Naive Bayes with Mislabeled Data
Apr 13, 2023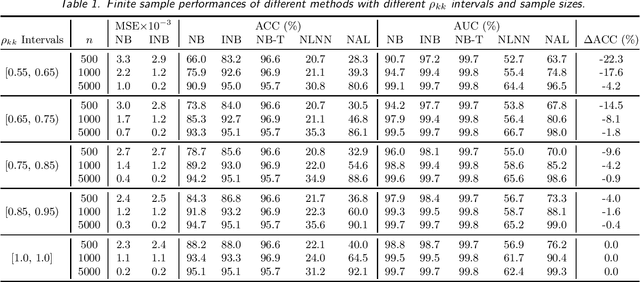
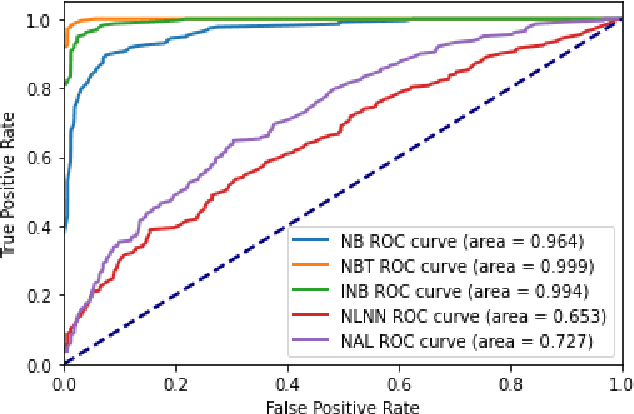

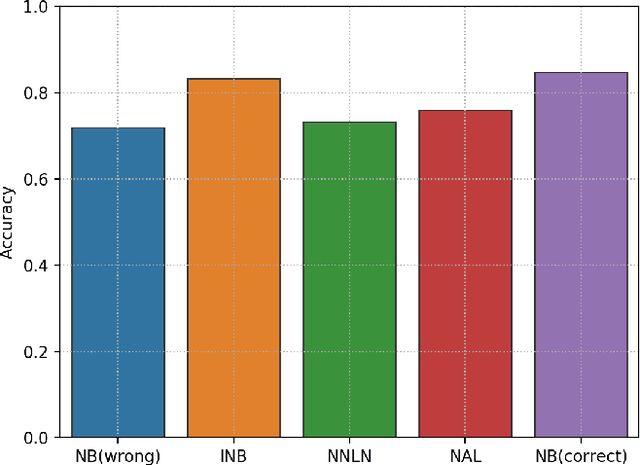
Labeling mistakes are frequently encountered in real-world applications. If not treated well, the labeling mistakes can deteriorate the classification performances of a model seriously. To address this issue, we propose an improved Naive Bayes method for text classification. It is analytically simple and free of subjective judgements on the correct and incorrect labels. By specifying the generating mechanism of incorrect labels, we optimize the corresponding log-likelihood function iteratively by using an EM algorithm. Our simulation and experiment results show that the improved Naive Bayes method greatly improves the performances of the Naive Bayes method with mislabeled data.
CoGANPPIS: Coevolution-enhanced Global Attention Neural Network for Protein-Protein Interaction Site Prediction
Apr 03, 2023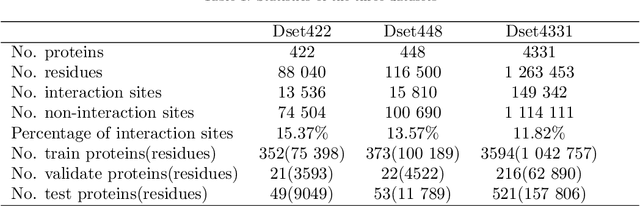
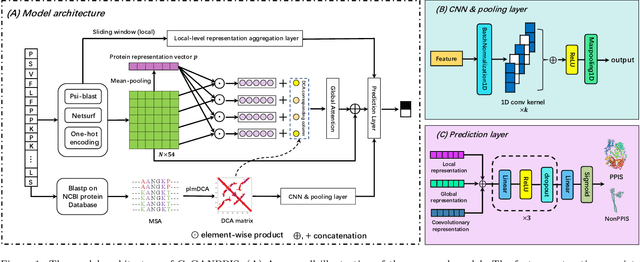
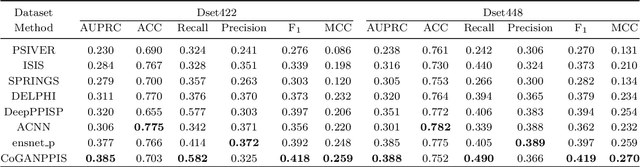
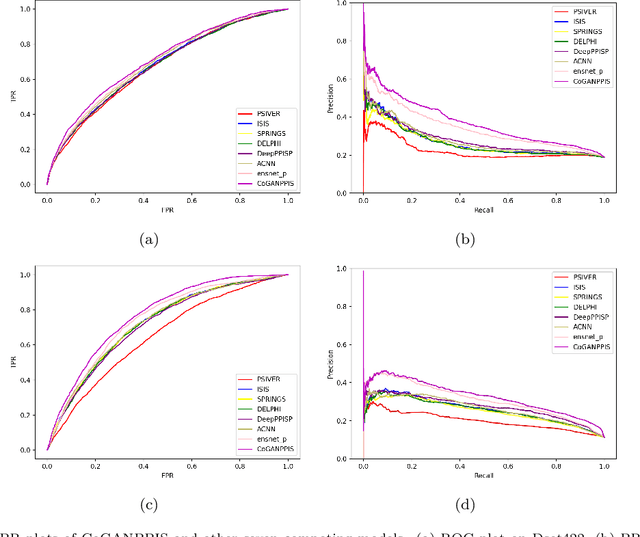
Protein-protein interactions are essential in biochemical processes. Accurate prediction of the protein-protein interaction sites (PPIs) deepens our understanding of biological mechanism and is crucial for new drug design. However, conventional experimental methods for PPIs prediction are costly and time-consuming so that many computational approaches, especially ML-based methods, have been developed recently. Although these approaches have achieved gratifying results, there are still two limitations: (1) Most models have excavated some useful input features, but failed to take coevolutionary features into account, which could provide clues for inter-residue relationships; (2) The attention-based models only allocate attention weights for neighboring residues, instead of doing it globally, neglecting that some residues being far away from the target residues might also matter. We propose a coevolution-enhanced global attention neural network, a sequence-based deep learning model for PPIs prediction, called CoGANPPIS. It utilizes three layers in parallel for feature extraction: (1) Local-level representation aggregation layer, which aggregates the neighboring residues' features; (2) Global-level representation learning layer, which employs a novel coevolution-enhanced global attention mechanism to allocate attention weights to all the residues on the same protein sequences; (3) Coevolutionary information learning layer, which applies CNN & pooling to coevolutionary information to obtain the coevolutionary profile representation. Then, the three outputs are concatenated and passed into several fully connected layers for the final prediction. Application on two benchmark datasets demonstrated a state-of-the-art performance of our model. The source code is publicly available at https://github.com/Slam1423/CoGANPPIS_source_code.
Least Squares Approximation for a Distributed System
Aug 14, 2019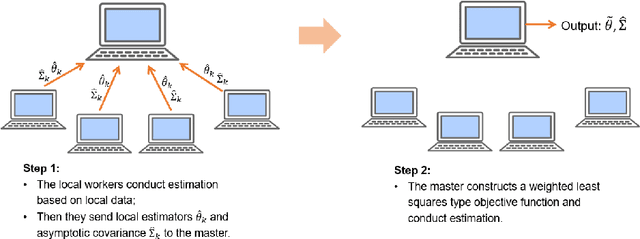
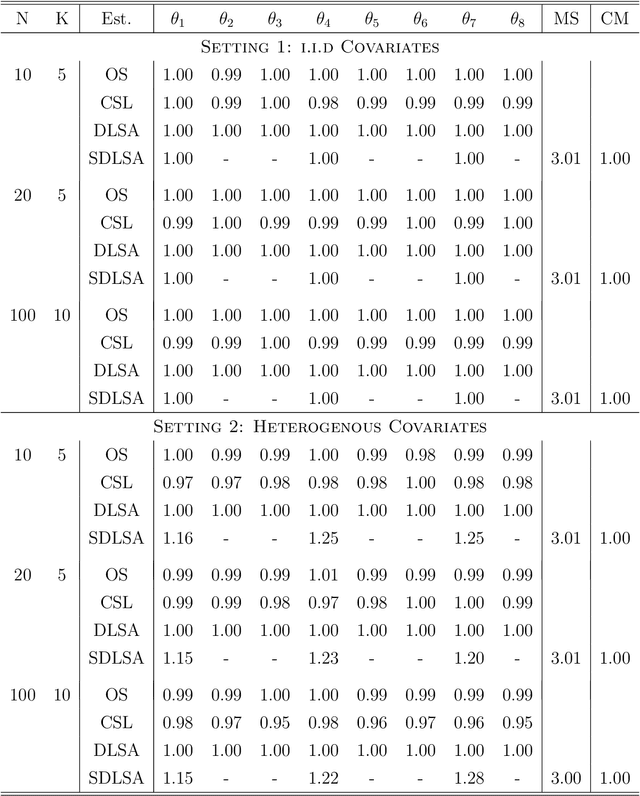
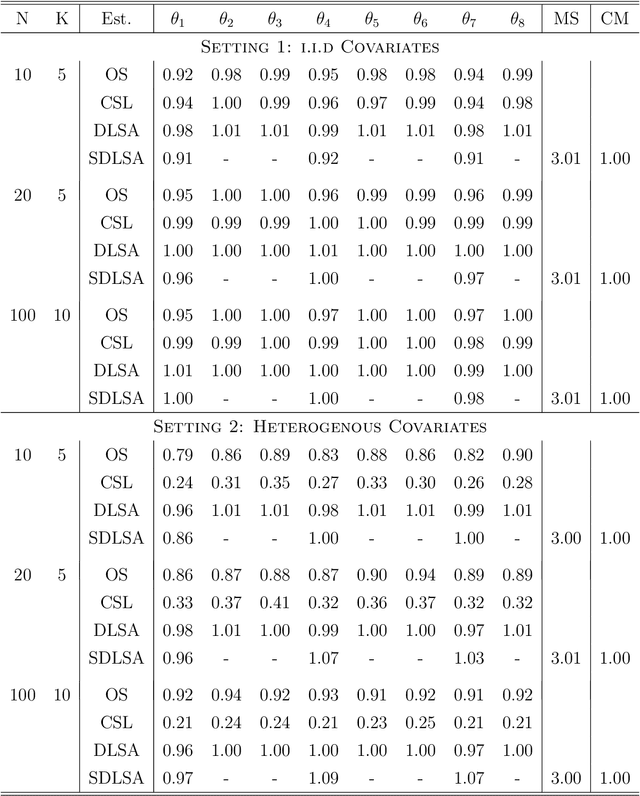
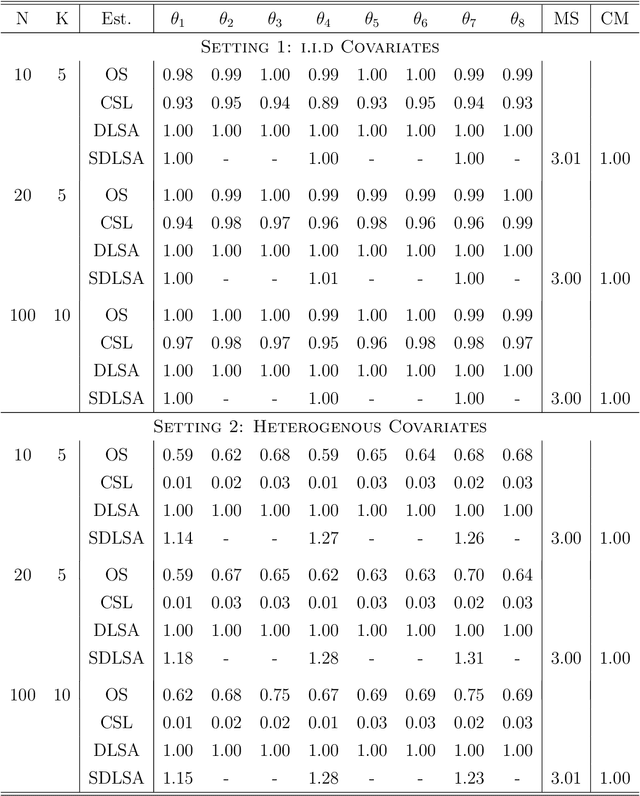
In this work we develop a distributed least squares approximation (DLSA) method, which is able to solve a large family of regression problems (e.g., linear regression, logistic regression, Cox's model) on a distributed system. By approximating the local objective function using a local quadratic form, we are able to obtain a combined estimator by taking a weighted average of local estimators. The resulting estimator is proved to be statistically as efficient as the global estimator. In the meanwhile it requires only one round of communication. We further conduct the shrinkage estimation based on the DLSA estimation by using an adaptive Lasso approach. The solution can be easily obtained by using the LARS algorithm on the master node. It is theoretically shown that the resulting estimator enjoys the oracle property and is selection consistent by using a newly designed distributed Bayesian Information Criterion (DBIC). The finite sample performance as well as the computational efficiency are further illustrated by extensive numerical study and an airline dataset. The airline dataset is 52GB in memory size. The entire methodology has been implemented by Python for a de-facto standard Spark system. By using the proposed DLSA algorithm on the Spark system, it takes 26 minutes to obtain a logistic regression estimator whereas a full likelihood algorithm takes 15 hours to reaches an inferior result.