 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork EM Algorithm for Gaussian Mixture Model in Decentralized Federated Learning
Nov 08, 2024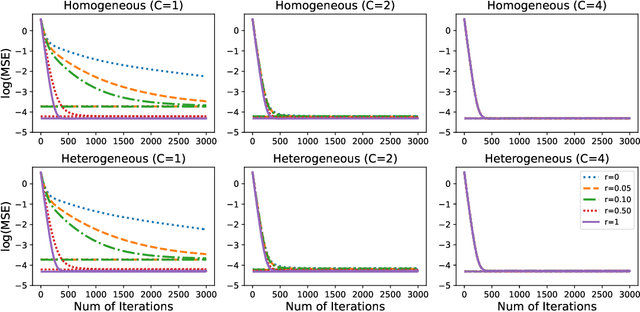
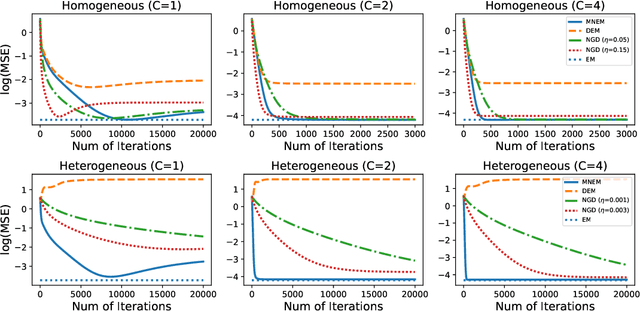
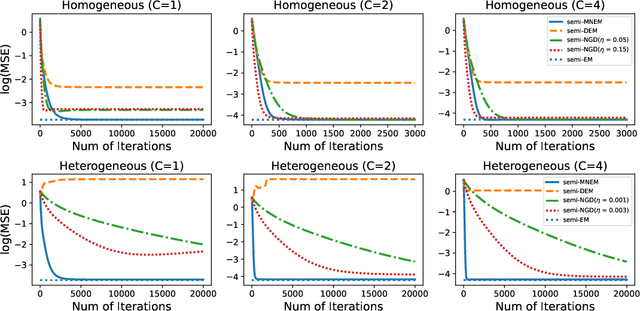
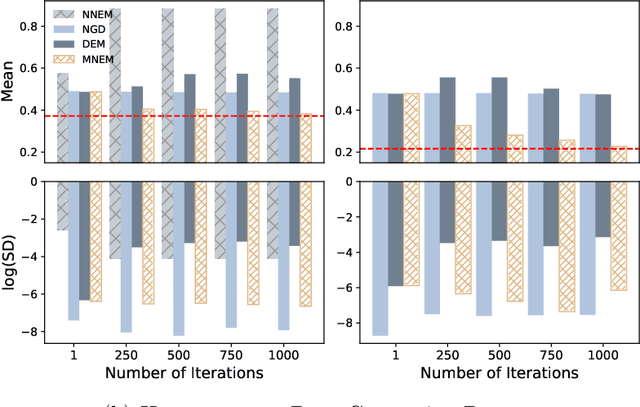
We systematically study various network Expectation-Maximization (EM) algorithms for the Gaussian mixture model within the framework of decentralized federated learning. Our theoretical investigation reveals that directly extending the classical decentralized supervised learning method to the EM algorithm exhibits poor estimation accuracy with heterogeneous data across clients and struggles to converge numerically when Gaussian components are poorly-separated. To address these issues, we propose two novel solutions. First, to handle heterogeneous data, we introduce a momentum network EM (MNEM) algorithm, which uses a momentum parameter to combine information from both the current and historical estimators. Second, to tackle the challenge of poorly-separated Gaussian components, we develop a semi-supervised MNEM (semi-MNEM) algorithm, which leverages partially labeled data. Rigorous theoretical analysis demonstrates that MNEM can achieve statistical efficiency comparable to that of the whole sample estimator when the mixture components satisfy certain separation conditions, even in heterogeneous scenarios. Moreover, the semi-MNEM estimator enhances the convergence speed of the MNEM algorithm, effectively addressing the numerical convergence challenges in poorly-separated scenarios. Extensive simulation and real data analyses are conducted to justify our theoretical findings.
A Selective Review on Statistical Methods for Massive Data Computation: Distributed Computing, Subsampling, and Minibatch Techniques
Mar 17, 2024This paper presents a selective review of statistical computation methods for massive data analysis. A huge amount of statistical methods for massive data computation have been rapidly developed in the past decades. In this work, we focus on three categories of statistical computation methods: (1) distributed computing, (2) subsampling methods, and (3) minibatch gradient techniques. The first class of literature is about distributed computing and focuses on the situation, where the dataset size is too huge to be comfortably handled by one single computer. In this case, a distributed computation system with multiple computers has to be utilized. The second class of literature is about subsampling methods and concerns about the situation, where the sample size of dataset is small enough to be placed on one single computer but too large to be easily processed by its memory as a whole. The last class of literature studies those minibatch gradient related optimization techniques, which have been extensively used for optimizing various deep learning models.
Quasi-Newton Updating for Large-Scale Distributed Learning
Jun 11, 2023



Distributed computing is critically important for modern statistical analysis. Herein, we develop a distributed quasi-Newton (DQN) framework with excellent statistical, computation, and communication efficiency. In the DQN method, no Hessian matrix inversion or communication is needed. This considerably reduces the computation and communication complexity of the proposed method. Notably, related existing methods only analyze numerical convergence and require a diverging number of iterations to converge. However, we investigate the statistical properties of the DQN method and theoretically demonstrate that the resulting estimator is statistically efficient over a small number of iterations under mild conditions. Extensive numerical analyses demonstrate the finite sample performance.
Network Gradient Descent Algorithm for Decentralized Federated Learning
May 06, 2022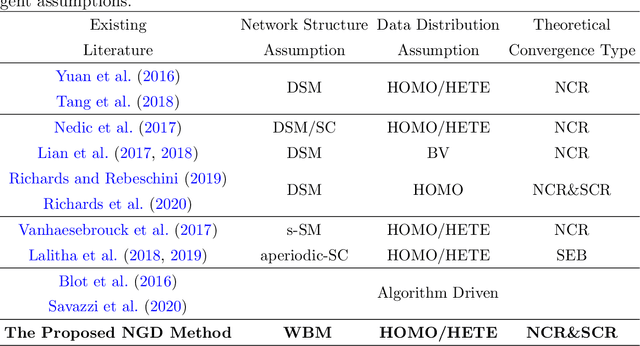
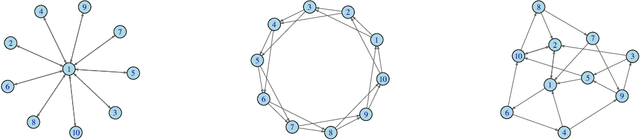

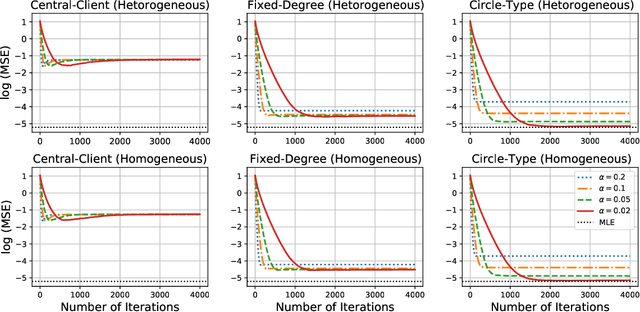
We study a fully decentralized federated learning algorithm, which is a novel gradient descent algorithm executed on a communication-based network. For convenience, we refer to it as a network gradient descent (NGD) method. In the NGD method, only statistics (e.g., parameter estimates) need to be communicated, minimizing the risk of privacy. Meanwhile, different clients communicate with each other directly according to a carefully designed network structure without a central master. This greatly enhances the reliability of the entire algorithm. Those nice properties inspire us to carefully study the NGD method both theoretically and numerically. Theoretically, we start with a classical linear regression model. We find that both the learning rate and the network structure play significant roles in determining the NGD estimator's statistical efficiency. The resulting NGD estimator can be statistically as efficient as the global estimator, if the learning rate is sufficiently small and the network structure is well balanced, even if the data are distributed heterogeneously. Those interesting findings are then extended to general models and loss functions. Extensive numerical studies are presented to corroborate our theoretical findings. Classical deep learning models are also presented for illustration purpose.