 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDream3DAvatar: Text-Controlled 3D Avatar Reconstruction from a Single Image
Sep 16, 2025
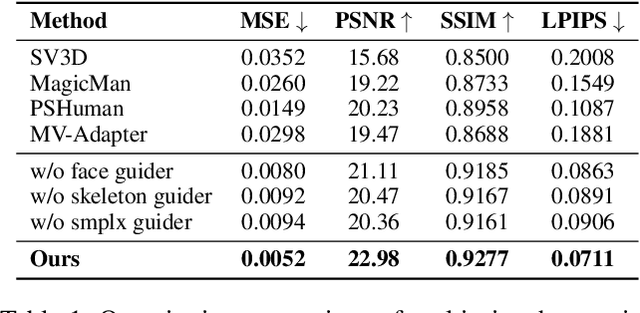
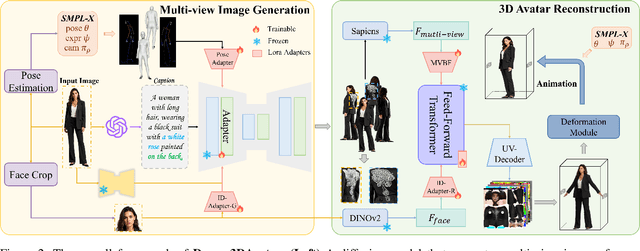
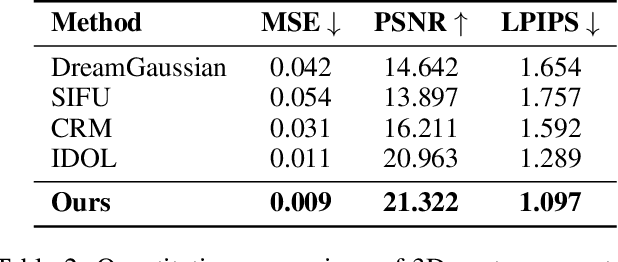
With the rapid advancement of 3D representation techniques and generative models, substantial progress has been made in reconstructing full-body 3D avatars from a single image. However, this task remains fundamentally ill-posedness due to the limited information available from monocular input, making it difficult to control the geometry and texture of occluded regions during generation. To address these challenges, we redesign the reconstruction pipeline and propose Dream3DAvatar, an efficient and text-controllable two-stage framework for 3D avatar generation. In the first stage, we develop a lightweight, adapter-enhanced multi-view generation model. Specifically, we introduce the Pose-Adapter to inject SMPL-X renderings and skeletal information into SDXL, enforcing geometric and pose consistency across views. To preserve facial identity, we incorporate ID-Adapter-G, which injects high-resolution facial features into the generation process. Additionally, we leverage BLIP2 to generate high-quality textual descriptions of the multi-view images, enhancing text-driven controllability in occluded regions. In the second stage, we design a feedforward Transformer model equipped with a multi-view feature fusion module to reconstruct high-fidelity 3D Gaussian Splat representations (3DGS) from the generated images. Furthermore, we introduce ID-Adapter-R, which utilizes a gating mechanism to effectively fuse facial features into the reconstruction process, improving high-frequency detail recovery. Extensive experiments demonstrate that our method can generate realistic, animation-ready 3D avatars without any post-processing and consistently outperforms existing baselines across multiple evaluation metrics.
Network EM Algorithm for Gaussian Mixture Model in Decentralized Federated Learning
Nov 08, 2024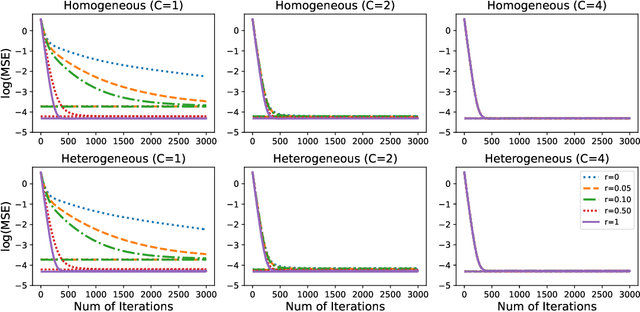
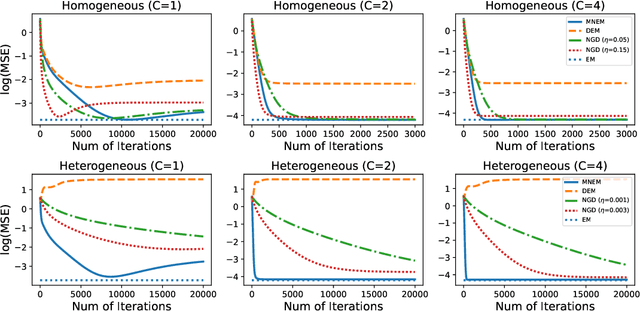
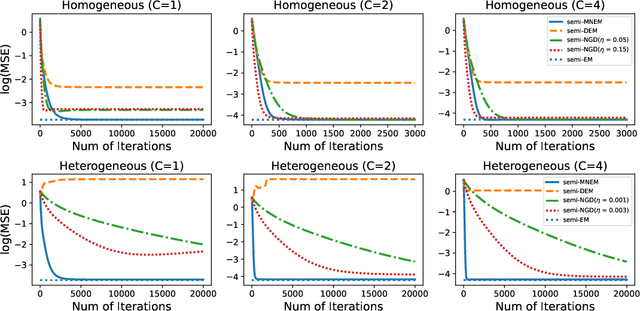
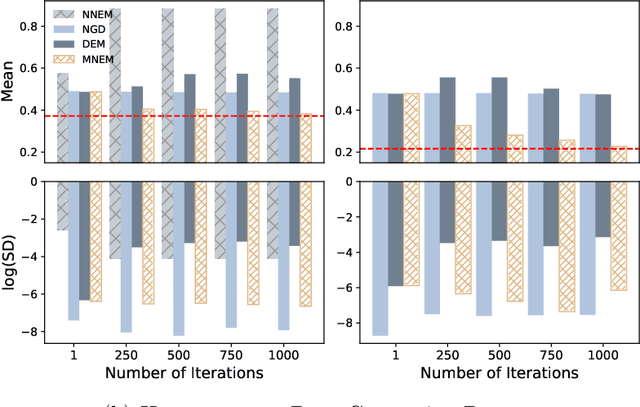
We systematically study various network Expectation-Maximization (EM) algorithms for the Gaussian mixture model within the framework of decentralized federated learning. Our theoretical investigation reveals that directly extending the classical decentralized supervised learning method to the EM algorithm exhibits poor estimation accuracy with heterogeneous data across clients and struggles to converge numerically when Gaussian components are poorly-separated. To address these issues, we propose two novel solutions. First, to handle heterogeneous data, we introduce a momentum network EM (MNEM) algorithm, which uses a momentum parameter to combine information from both the current and historical estimators. Second, to tackle the challenge of poorly-separated Gaussian components, we develop a semi-supervised MNEM (semi-MNEM) algorithm, which leverages partially labeled data. Rigorous theoretical analysis demonstrates that MNEM can achieve statistical efficiency comparable to that of the whole sample estimator when the mixture components satisfy certain separation conditions, even in heterogeneous scenarios. Moreover, the semi-MNEM estimator enhances the convergence speed of the MNEM algorithm, effectively addressing the numerical convergence challenges in poorly-separated scenarios. Extensive simulation and real data analyses are conducted to justify our theoretical findings.
Multi-view clustering integrating anchor attribute and structural information
Oct 29, 2024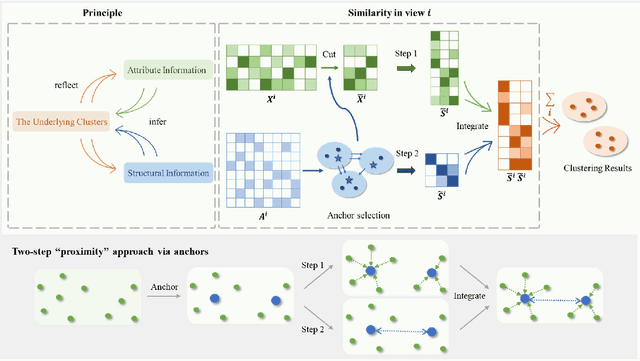


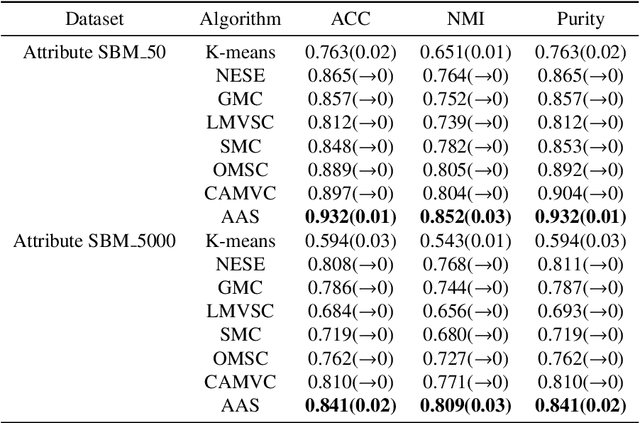
Multisource data has spurred the development of advanced clustering algorithms, such as multi-view clustering, which critically relies on constructing similarity matrices. Traditional algorithms typically generate these matrices from sample attributes alone. However, real-world networks often include pairwise directed topological structures critical for clustering. This paper introduces a novel multi-view clustering algorithm, AAS. It utilizes a two-step proximity approach via anchors in each view, integrating attribute and directed structural information. This approach enhances the clarity of category characteristics in the similarity matrices. The anchor structural similarity matrix leverages strongly connected components of directed graphs. The entire process-from similarity matrices construction to clustering - is consolidated into a unified optimization framework. Comparative experiments on the modified Attribute SBM dataset against eight algorithms affirm the effectiveness and superiority of AAS.
A Selective Review on Statistical Methods for Massive Data Computation: Distributed Computing, Subsampling, and Minibatch Techniques
Mar 17, 2024This paper presents a selective review of statistical computation methods for massive data analysis. A huge amount of statistical methods for massive data computation have been rapidly developed in the past decades. In this work, we focus on three categories of statistical computation methods: (1) distributed computing, (2) subsampling methods, and (3) minibatch gradient techniques. The first class of literature is about distributed computing and focuses on the situation, where the dataset size is too huge to be comfortably handled by one single computer. In this case, a distributed computation system with multiple computers has to be utilized. The second class of literature is about subsampling methods and concerns about the situation, where the sample size of dataset is small enough to be placed on one single computer but too large to be easily processed by its memory as a whole. The last class of literature studies those minibatch gradient related optimization techniques, which have been extensively used for optimizing various deep learning models.