 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvisible Tokens, Visible Bills: The Urgent Need to Audit Hidden Operations in Opaque LLM Services
May 24, 2025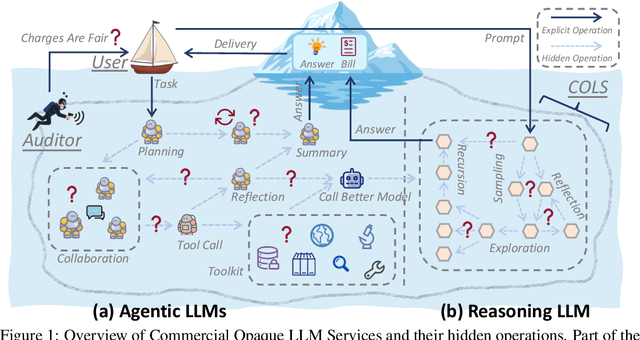
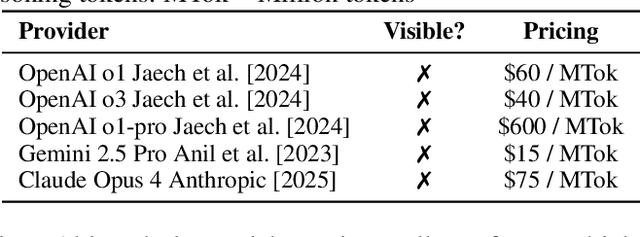
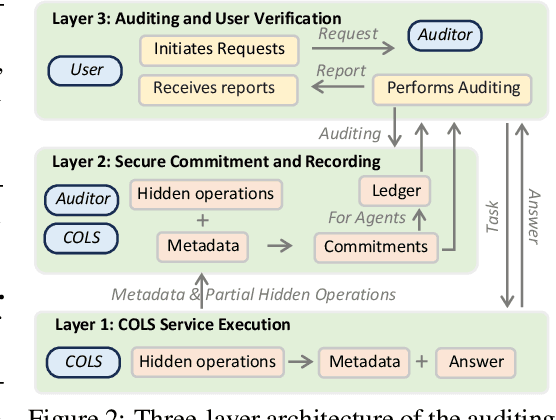

Modern large language model (LLM) services increasingly rely on complex, often abstract operations, such as multi-step reasoning and multi-agent collaboration, to generate high-quality outputs. While users are billed based on token consumption and API usage, these internal steps are typically not visible. We refer to such systems as Commercial Opaque LLM Services (COLS). This position paper highlights emerging accountability challenges in COLS: users are billed for operations they cannot observe, verify, or contest. We formalize two key risks: \textit{quantity inflation}, where token and call counts may be artificially inflated, and \textit{quality downgrade}, where providers might quietly substitute lower-cost models or tools. Addressing these risks requires a diverse set of auditing strategies, including commitment-based, predictive, behavioral, and signature-based methods. We further explore the potential of complementary mechanisms such as watermarking and trusted execution environments to enhance verifiability without compromising provider confidentiality. We also propose a modular three-layer auditing framework for COLS and users that enables trustworthy verification across execution, secure logging, and user-facing auditability without exposing proprietary internals. Our aim is to encourage further research and policy development toward transparency, auditability, and accountability in commercial LLM services.
NetSight: Graph Attention Based Traffic Forecasting in Computer Networks
May 11, 2025The traffic in today's networks is increasingly influenced by the interactions among network nodes as well as by the temporal fluctuations in the demands of the nodes. Traditional statistical prediction methods are becoming obsolete due to their inability to address the non-linear and dynamic spatio-temporal dependencies present in today's network traffic. The most promising direction of research today is graph neural networks (GNNs) based prediction approaches that are naturally suited to handle graph-structured data. Unfortunately, the state-of-the-art GNN approaches separate the modeling of spatial and temporal information, resulting in the loss of important information about joint dependencies. These GNN based approaches further do not model information at both local and global scales simultaneously, leaving significant room for improvement. To address these challenges, we propose NetSight. NetSight learns joint spatio-temporal dependencies simultaneously at both global and local scales from the time-series of measurements of any given network metric collected at various nodes in a network. Using the learned information, NetSight can then accurately predict the future values of the given network metric at those nodes in the network. We propose several new concepts and techniques in the design of NetSight, such as spatio-temporal adjacency matrix and node normalization. Through extensive evaluations and comparison with prior approaches using data from two large real-world networks, we show that NetSight significantly outperforms all prior state-of-the-art approaches. We will release the source code and data used in the evaluation of NetSight on the acceptance of this paper.
Unifying Prediction and Explanation in Time-Series Transformers via Shapley-based Pretraining
Jan 25, 2025



In this paper, we propose ShapTST, a framework that enables time-series transformers to efficiently generate Shapley-value-based explanations alongside predictions in a single forward pass. Shapley values are widely used to evaluate the contribution of different time-steps and features in a test sample, and are commonly generated through repeatedly inferring on each sample with different parts of information removed. Therefore, it requires expensive inference-time computations that occur at every request for model explanations. In contrast, our framework unifies the explanation and prediction in training through a novel Shapley-based pre-training design, which eliminates the undesirable test-time computation and replaces it with a single-time pre-training. Moreover, this specialized pre-training benefits the prediction performance by making the transformer model more effectively weigh different features and time-steps in the time-series, particularly improving the robustness against data noise that is common to raw time-series data. We experimentally validated our approach on eight public datasets, where our time-series model achieved competitive results in both classification and regression tasks, while providing Shapley-based explanations similar to those obtained with post-hoc computation. Our work offers an efficient and explainable solution for time-series analysis tasks in the safety-critical applications.
Multi-view Fuzzy Graph Attention Networks for Enhanced Graph Learning
Dec 23, 2024Fuzzy Graph Attention Network (FGAT), which combines Fuzzy Rough Sets and Graph Attention Networks, has shown promise in tasks requiring robust graph-based learning. However, existing models struggle to effectively capture dependencies from multiple perspectives, limiting their ability to model complex data. To address this gap, we propose the Multi-view Fuzzy Graph Attention Network (MFGAT), a novel framework that constructs and aggregates multi-view information using a specially designed Transformation Block. This block dynamically transforms data from multiple aspects and aggregates the resulting representations via a weighted sum mechanism, enabling comprehensive multi-view modeling. The aggregated information is fed into FGAT to enhance fuzzy graph convolutions. Additionally, we introduce a simple yet effective learnable global pooling mechanism for improved graph-level understanding. Extensive experiments on graph classification tasks demonstrate that MFGAT outperforms state-of-the-art baselines, underscoring its effectiveness and versatility.
FGATT: A Robust Framework for Wireless Data Imputation Using Fuzzy Graph Attention Networks and Transformer Encoders
Dec 02, 2024Missing data is a pervasive challenge in wireless networks and many other domains, often compromising the performance of machine learning and deep learning models. To address this, we propose a novel framework, FGATT, that combines the Fuzzy Graph Attention Network (FGAT) with the Transformer encoder to perform robust and accurate data imputation. FGAT leverages fuzzy rough sets and graph attention mechanisms to capture spatial dependencies dynamically, even in scenarios where predefined spatial information is unavailable. The Transformer encoder is employed to model temporal dependencies, utilizing its self-attention mechanism to focus on significant time-series patterns. A self-adaptive graph construction method is introduced to enable dynamic connectivity learning, ensuring the framework's applicability to a wide range of wireless datasets. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods in imputation accuracy and robustness, particularly in scenarios with substantial missing data. The proposed model is well-suited for applications in wireless sensor networks and IoT environments, where data integrity is critical.
Comparative Analysis of Pooling Mechanisms in LLMs: A Sentiment Analysis Perspective
Nov 22, 2024

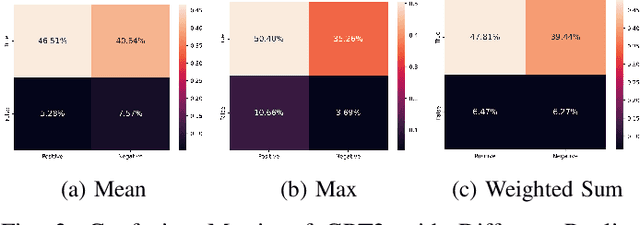

Large Language Models (LLMs) have revolutionized natural language processing (NLP) by delivering state-of-the-art performance across a variety of tasks. Among these, Transformer-based models like BERT and GPT rely on pooling layers to aggregate token-level embeddings into sentence-level representations. Common pooling mechanisms such as Mean, Max, and Weighted Sum play a pivotal role in this aggregation process. Despite their widespread use, the comparative performance of these strategies on different LLM architectures remains underexplored. To address this gap, this paper investigates the effects of these pooling mechanisms on two prominent LLM families -- BERT and GPT, in the context of sentence-level sentiment analysis. Comprehensive experiments reveal that each pooling mechanism exhibits unique strengths and weaknesses depending on the task's specific requirements. Our findings underline the importance of selecting pooling methods tailored to the demands of particular applications, prompting a re-evaluation of common assumptions regarding pooling operations. By offering actionable insights, this study contributes to the optimization of LLM-based models for downstream tasks.
Enhancing Link Prediction with Fuzzy Graph Attention Networks and Dynamic Negative Sampling
Nov 12, 2024Link prediction is crucial for understanding complex networks but traditional Graph Neural Networks (GNNs) often rely on random negative sampling, leading to suboptimal performance. This paper introduces Fuzzy Graph Attention Networks (FGAT), a novel approach integrating fuzzy rough sets for dynamic negative sampling and enhanced node feature aggregation. Fuzzy Negative Sampling (FNS) systematically selects high-quality negative edges based on fuzzy similarities, improving training efficiency. FGAT layer incorporates fuzzy rough set principles, enabling robust and discriminative node representations. Experiments on two research collaboration networks demonstrate FGAT's superior link prediction accuracy, outperforming state-of-the-art baselines by leveraging the power of fuzzy rough sets for effective negative sampling and node feature learning.