 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Pooling Mechanisms in LLMs: A Sentiment Analysis Perspective
Paper and Code
Nov 22, 2024

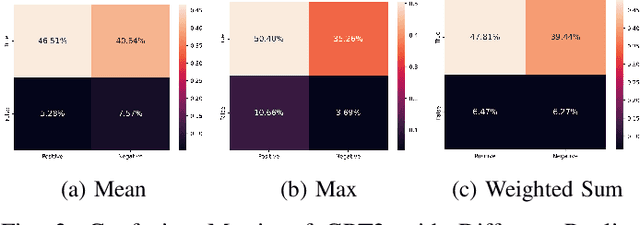

Large Language Models (LLMs) have revolutionized natural language processing (NLP) by delivering state-of-the-art performance across a variety of tasks. Among these, Transformer-based models like BERT and GPT rely on pooling layers to aggregate token-level embeddings into sentence-level representations. Common pooling mechanisms such as Mean, Max, and Weighted Sum play a pivotal role in this aggregation process. Despite their widespread use, the comparative performance of these strategies on different LLM architectures remains underexplored. To address this gap, this paper investigates the effects of these pooling mechanisms on two prominent LLM families -- BERT and GPT, in the context of sentence-level sentiment analysis. Comprehensive experiments reveal that each pooling mechanism exhibits unique strengths and weaknesses depending on the task's specific requirements. Our findings underline the importance of selecting pooling methods tailored to the demands of particular applications, prompting a re-evaluation of common assumptions regarding pooling operations. By offering actionable insights, this study contributes to the optimization of LLM-based models for downstream tasks.