 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTMBA: Towards Text To Multiple Sources Binaural Audio Generation
Jul 22, 2025



Most existing text-to-audio (TTA) generation methods produce mono outputs, neglecting essential spatial information for immersive auditory experiences. To address this issue, we propose a cascaded method for text-to-multisource binaural audio generation (TTMBA) with both temporal and spatial control. First, a pretrained large language model (LLM) segments the text into a structured format with time and spatial details for each sound event. Next, a pretrained mono audio generation network creates multiple mono audios with varying durations for each event. These mono audios are transformed into binaural audios using a binaural rendering neural network based on spatial data from the LLM. Finally, the binaural audios are arranged by their start times, resulting in multisource binaural audio. Experimental results demonstrate the superiority of the proposed method in terms of both audio generation quality and spatial perceptual accuracy.
Unifying Prediction and Explanation in Time-Series Transformers via Shapley-based Pretraining
Jan 25, 2025



In this paper, we propose ShapTST, a framework that enables time-series transformers to efficiently generate Shapley-value-based explanations alongside predictions in a single forward pass. Shapley values are widely used to evaluate the contribution of different time-steps and features in a test sample, and are commonly generated through repeatedly inferring on each sample with different parts of information removed. Therefore, it requires expensive inference-time computations that occur at every request for model explanations. In contrast, our framework unifies the explanation and prediction in training through a novel Shapley-based pre-training design, which eliminates the undesirable test-time computation and replaces it with a single-time pre-training. Moreover, this specialized pre-training benefits the prediction performance by making the transformer model more effectively weigh different features and time-steps in the time-series, particularly improving the robustness against data noise that is common to raw time-series data. We experimentally validated our approach on eight public datasets, where our time-series model achieved competitive results in both classification and regression tasks, while providing Shapley-based explanations similar to those obtained with post-hoc computation. Our work offers an efficient and explainable solution for time-series analysis tasks in the safety-critical applications.
Improvement and Implementation of a Speech Emotion Recognition Model Based on Dual-Layer LSTM
Nov 14, 2024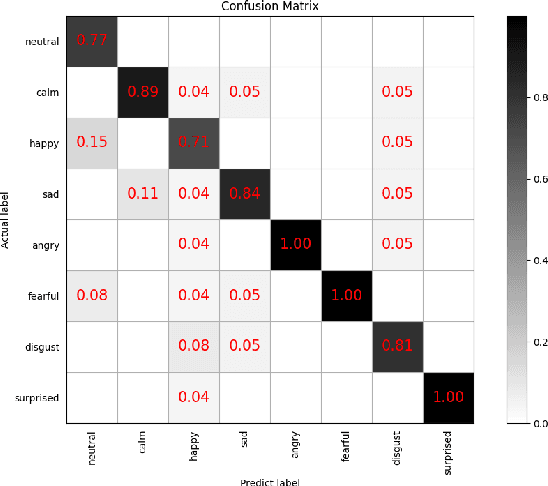
This paper builds upon an existing speech emotion recognition model by adding an additional LSTM layer to improve the accuracy and processing efficiency of emotion recognition from audio data. By capturing the long-term dependencies within audio sequences through a dual-layer LSTM network, the model can recognize and classify complex emotional patterns more accurately. Experiments conducted on the RAVDESS dataset validated this approach, showing that the modified dual layer LSTM model improves accuracy by 2% compared to the single-layer LSTM while significantly reducing recognition latency, thereby enhancing real-time performance. These results indicate that the dual-layer LSTM architecture is highly suitable for handling emotional features with long-term dependencies, providing a viable optimization for speech emotion recognition systems. This research provides a reference for practical applications in fields like intelligent customer service, sentiment analysis and human-computer interaction.