 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A Personality-Driven Multi-Agent Framework for Social Media Simulation
Dec 22, 2025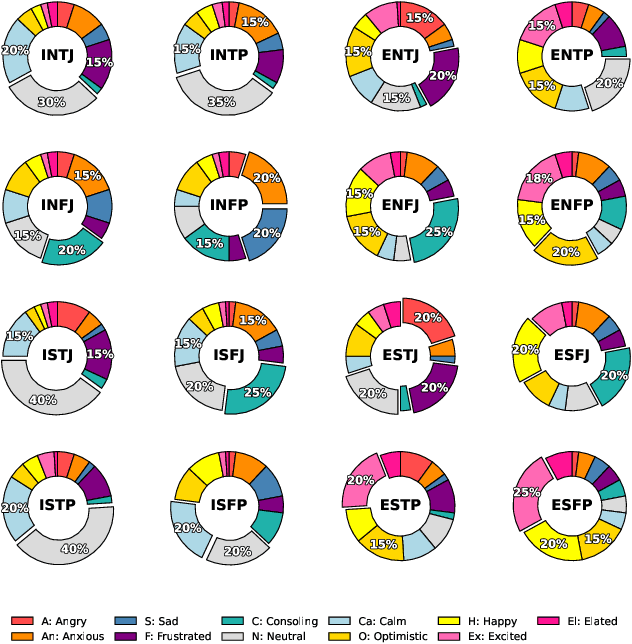
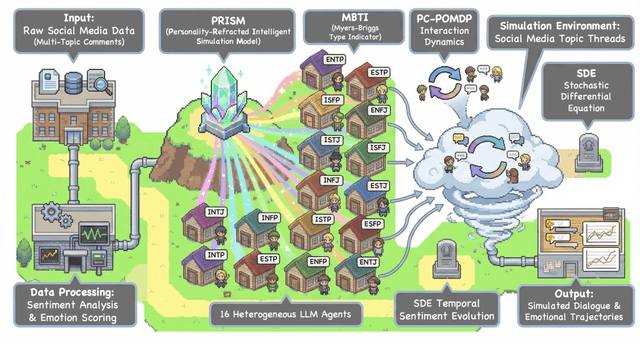
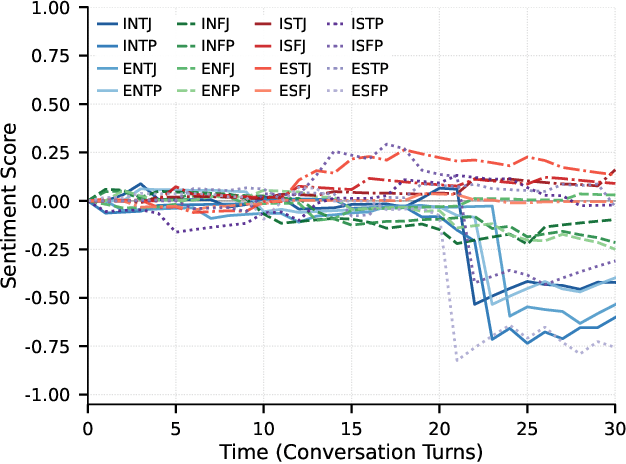

Traditional agent-based models (ABMs) of opinion dynamics often fail to capture the psychological heterogeneity driving online polarization due to simplistic homogeneity assumptions. This limitation obscures the critical interplay between individual cognitive biases and information propagation, thereby hindering a mechanistic understanding of how ideological divides are amplified. To address this challenge, we introduce the Personality-Refracted Intelligent Simulation Model (PRISM), a hybrid framework coupling stochastic differential equations (SDE) for continuous emotional evolution with a personality-conditional partially observable Markov decision process (PC-POMDP) for discrete decision-making. In contrast to continuous trait approaches, PRISM assigns distinct Myers-Briggs Type Indicator (MBTI) based cognitive policies to multimodal large language model (MLLM) agents, initialized via data-driven priors from large-scale social media datasets. PRISM achieves superior personality consistency aligned with human ground truth, significantly outperforming standard homogeneous and Big Five benchmarks. This framework effectively replicates emergent phenomena such as rational suppression and affective resonance, offering a robust tool for analyzing complex social media ecosystems.
Rhythm of Opinion: A Hawkes-Graph Framework for Dynamic Propagation Analysis
Apr 21, 2025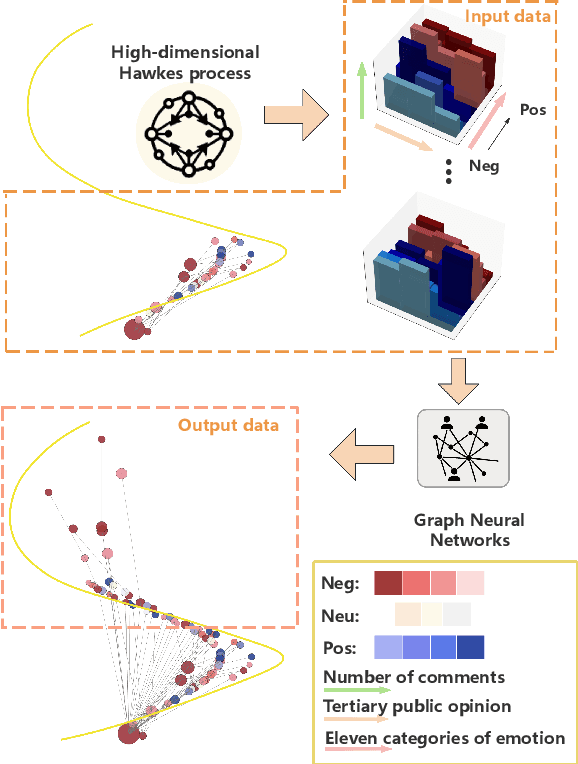
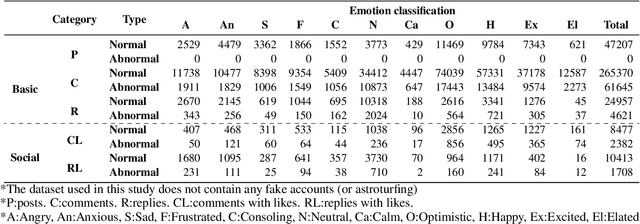
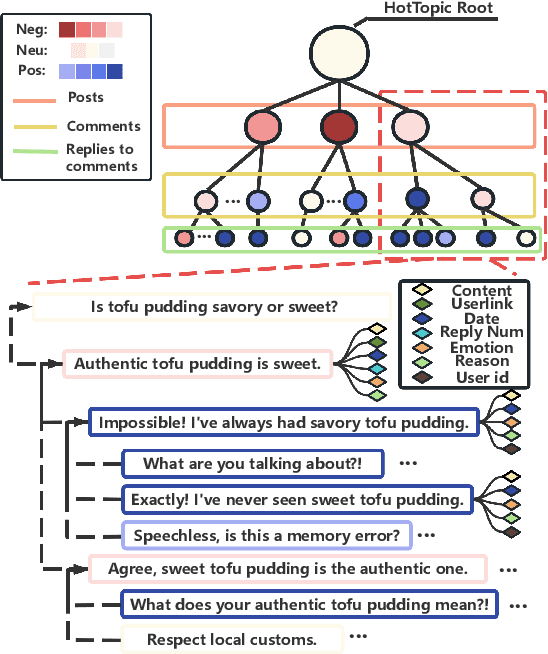
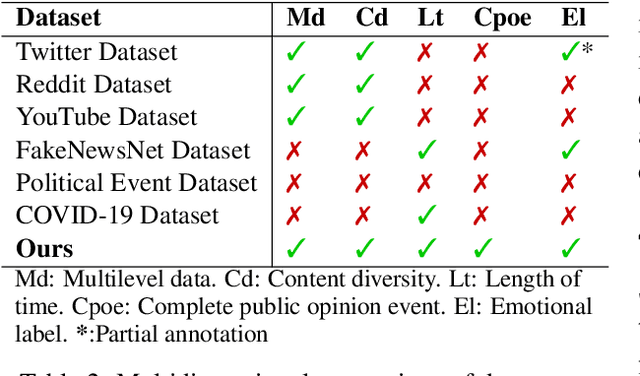
The rapid development of social media has significantly reshaped the dynamics of public opinion, resulting in complex interactions that traditional models fail to effectively capture. To address this challenge, we propose an innovative approach that integrates multi-dimensional Hawkes processes with Graph Neural Network, modeling opinion propagation dynamics among nodes in a social network while considering the intricate hierarchical relationships between comments. The extended multi-dimensional Hawkes process captures the hierarchical structure, multi-dimensional interactions, and mutual influences across different topics, forming a complex propagation network. Moreover, recognizing the lack of high-quality datasets capable of comprehensively capturing the evolution of public opinion dynamics, we introduce a new dataset, VISTA. It includes 159 trending topics, corresponding to 47,207 posts, 327,015 second-level comments, and 29,578 third-level comments, covering diverse domains such as politics, entertainment, sports, health, and medicine. The dataset is annotated with detailed sentiment labels across 11 categories and clearly defined hierarchical relationships. When combined with our method, it offers strong interpretability by linking sentiment propagation to the comment hierarchy and temporal evolution. Our approach provides a robust baseline for future research.
Decoding the Flow: CauseMotion for Emotional Causality Analysis in Long-form Conversations
Jan 01, 2025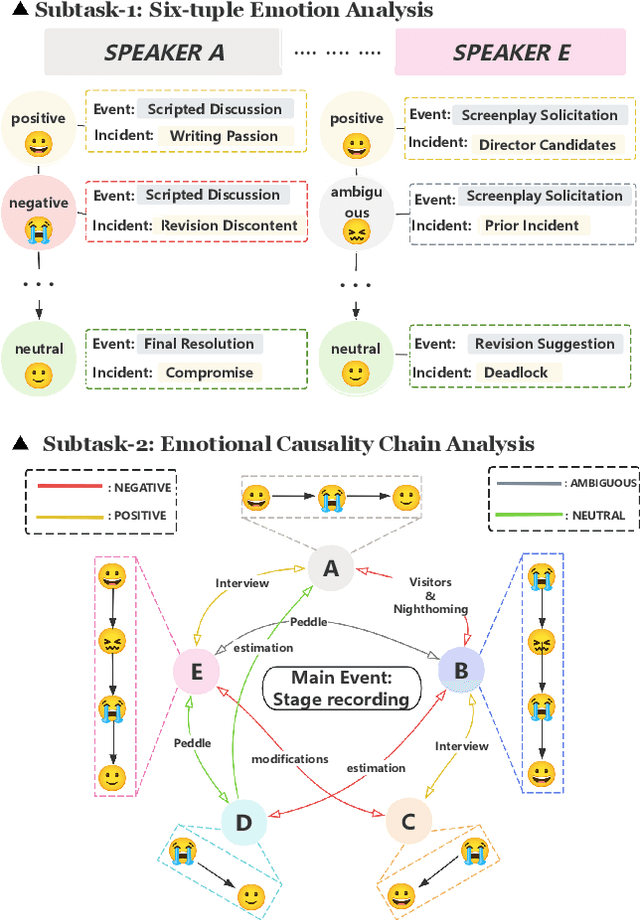
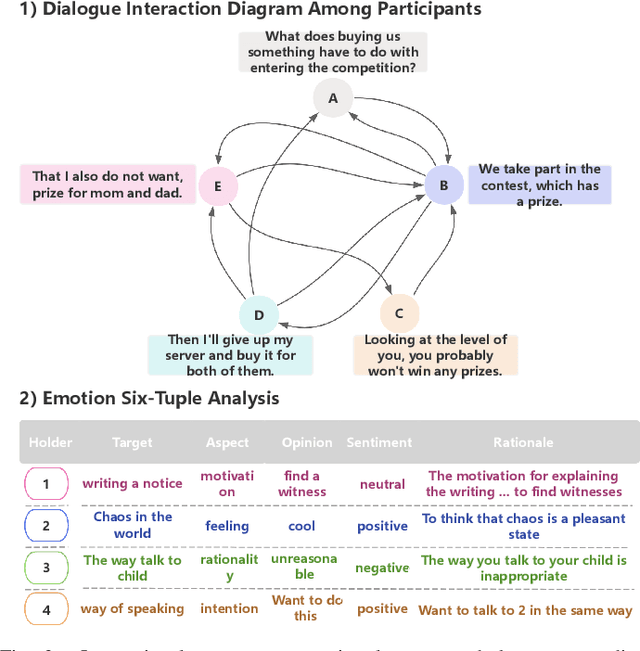
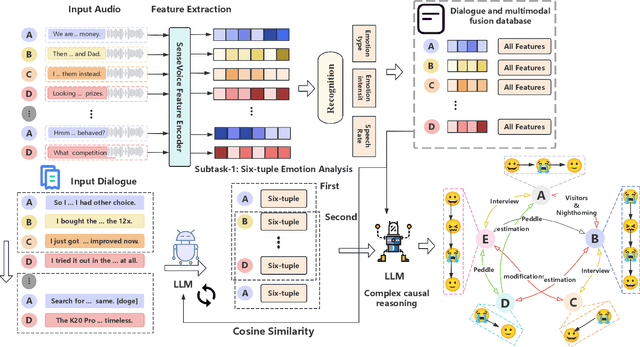
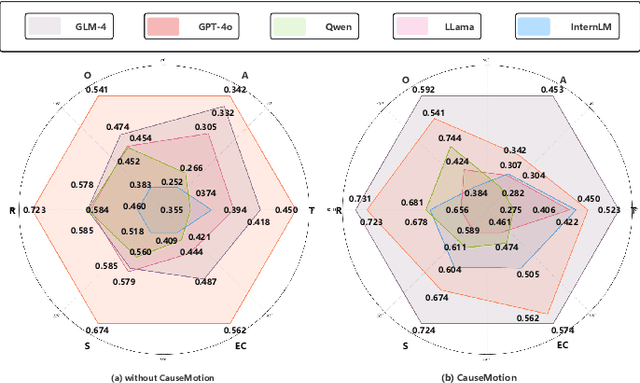
Long-sequence causal reasoning seeks to uncover causal relationships within extended time series data but is hindered by complex dependencies and the challenges of validating causal links. To address the limitations of large-scale language models (e.g., GPT-4) in capturing intricate emotional causality within extended dialogues, we propose CauseMotion, a long-sequence emotional causal reasoning framework grounded in Retrieval-Augmented Generation (RAG) and multimodal fusion. Unlike conventional methods relying only on textual information, CauseMotion enriches semantic representations by incorporating audio-derived features-vocal emotion, emotional intensity, and speech rate-into textual modalities. By integrating RAG with a sliding window mechanism, it effectively retrieves and leverages contextually relevant dialogue segments, thus enabling the inference of complex emotional causal chains spanning multiple conversational turns. To evaluate its effectiveness, we constructed the first benchmark dataset dedicated to long-sequence emotional causal reasoning, featuring dialogues with over 70 turns. Experimental results demonstrate that the proposed RAG-based multimodal integrated approach, the efficacy of substantially enhances both the depth of emotional understanding and the causal inference capabilities of large-scale language models. A GLM-4 integrated with CauseMotion achieves an 8.7% improvement in causal accuracy over the original model and surpasses GPT-4o by 1.2%. Additionally, on the publicly available DiaASQ dataset, CauseMotion-GLM-4 achieves state-of-the-art results in accuracy, F1 score, and causal reasoning accuracy.
Beyond Words: AuralLLM and SignMST-C for Precise Sign Language Production and Bidirectional Accessibility
Jan 01, 2025Although sign language recognition aids non-hearing-impaired understanding, many hearing-impaired individuals still rely on sign language alone due to limited literacy, underscoring the need for advanced sign language production and translation (SLP and SLT) systems. In the field of sign language production, the lack of adequate models and datasets restricts practical applications. Existing models face challenges in production accuracy and pose control, making it difficult to provide fluent sign language expressions across diverse scenarios. Additionally, data resources are scarce, particularly high-quality datasets with complete sign vocabulary and pose annotations. To address these issues, we introduce CNText2Sign and CNSign, comprehensive datasets to benchmark SLP and SLT, respectively, with CNText2Sign covering gloss and landmark mappings for SLP, and CNSign providing extensive video-to-text data for SLT. To improve the accuracy and applicability of sign language systems, we propose the AuraLLM and SignMST-C models. AuraLLM, incorporating LoRA and RAG techniques, achieves a BLEU-4 score of 50.41 on the CNText2Sign dataset, enabling precise control over gesture semantics and motion. SignMST-C employs self-supervised rapid motion video pretraining, achieving a BLEU-4 score of 31.03/32.08 on the PHOENIX2014-T benchmark, setting a new state-of-the-art. These models establish robust baselines for the datasets released for their respective tasks.