 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Topological Graph Reasoning for Language-Guided Pulmonary Screening
Apr 07, 2026Medical image segmentation driven by free-text clinical instructions is a critical frontier in computer-aided diagnosis. However, existing multimodal and foundation models struggle with the semantic ambiguity of clinical reports and fail to disambiguate complex anatomical overlaps in low-contrast scans. Furthermore, fully fine-tuning these massive architectures on limited medical datasets invariably leads to severe overfitting. To address these challenges, we propose a novel Semantic-Topological Graph Reasoning (STGR) framework for language-guided pulmonary screening. Our approach elegantly synergizes the reasoning capabilities of large language models (LLaMA-3-V) with the zero-shot delineation of vision foundation models (MedSAM). Specifically, we introduce a Text-to-Vision Intent Distillation (TVID) module to extract precise diagnostic guidance. To resolve anatomical ambiguity, we formulate mask selection as a dynamic graph reasoning problem, where candidate lesions are modeled as nodes and edges capture spatial and semantic affinities. To ensure deployment feasibility, we introduce a Selective Asymmetric Fine-Tuning (SAFT) strategy that updates less than 1% of the parameters. Rigorous 5-fold cross-validation on the LIDC-IDRI and LNDb datasets demonstrates that our framework establishes a new state-of-the-art. Notably, it achieves an 81.5% Dice Similarity Coefficient (DSC) on LIDC-IDRI, outperforming leading LLM-based tools like LISA by over 5%. Crucially, our SAFT strategy acts as a powerful regularizer, yielding exceptional cross-fold stability (0.6% DSC variance) and paving the way for robust, context-aware clinical deployment.
Beyond Words: AuralLLM and SignMST-C for Precise Sign Language Production and Bidirectional Accessibility
Jan 01, 2025
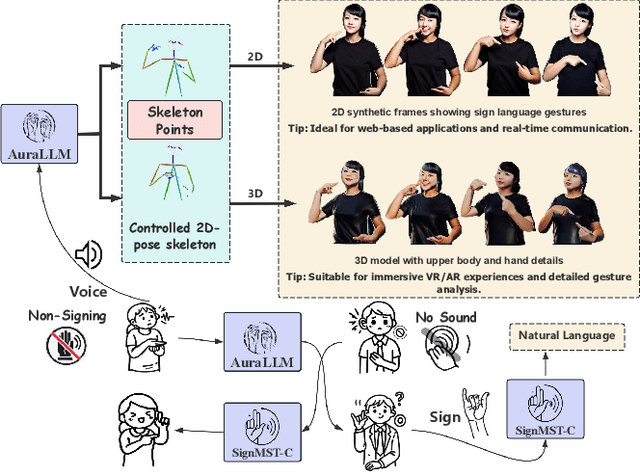


Although sign language recognition aids non-hearing-impaired understanding, many hearing-impaired individuals still rely on sign language alone due to limited literacy, underscoring the need for advanced sign language production and translation (SLP and SLT) systems. In the field of sign language production, the lack of adequate models and datasets restricts practical applications. Existing models face challenges in production accuracy and pose control, making it difficult to provide fluent sign language expressions across diverse scenarios. Additionally, data resources are scarce, particularly high-quality datasets with complete sign vocabulary and pose annotations. To address these issues, we introduce CNText2Sign and CNSign, comprehensive datasets to benchmark SLP and SLT, respectively, with CNText2Sign covering gloss and landmark mappings for SLP, and CNSign providing extensive video-to-text data for SLT. To improve the accuracy and applicability of sign language systems, we propose the AuraLLM and SignMST-C models. AuraLLM, incorporating LoRA and RAG techniques, achieves a BLEU-4 score of 50.41 on the CNText2Sign dataset, enabling precise control over gesture semantics and motion. SignMST-C employs self-supervised rapid motion video pretraining, achieving a BLEU-4 score of 31.03/32.08 on the PHOENIX2014-T benchmark, setting a new state-of-the-art. These models establish robust baselines for the datasets released for their respective tasks.
BERT-hLSTMs: BERT and Hierarchical LSTMs for Visual Storytelling
Dec 03, 2020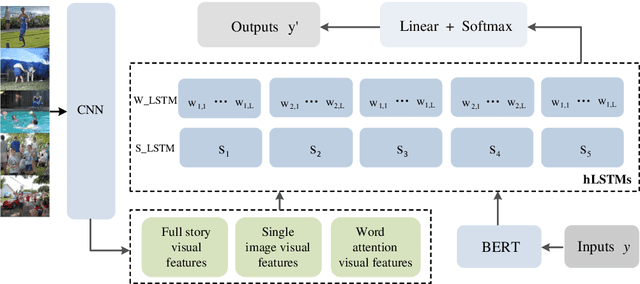

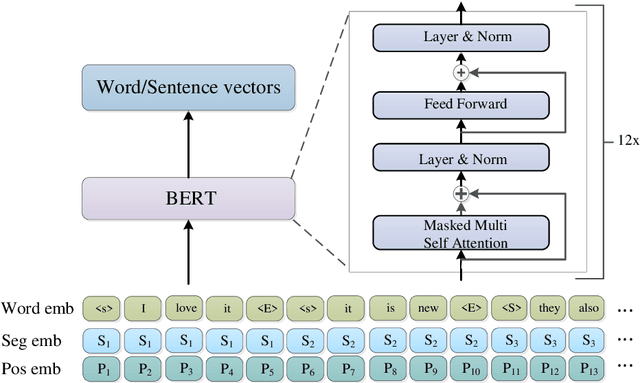
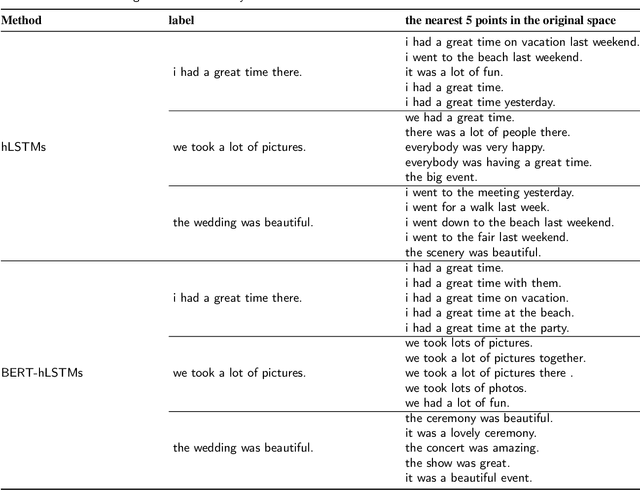
Visual storytelling is a creative and challenging task, aiming to automatically generate a story-like description for a sequence of images. The descriptions generated by previous visual storytelling approaches lack coherence because they use word-level sequence generation methods and do not adequately consider sentence-level dependencies. To tackle this problem, we propose a novel hierarchical visual storytelling framework which separately models sentence-level and word-level semantics. We use the transformer-based BERT to obtain embeddings for sentences and words. We then employ a hierarchical LSTM network: the bottom LSTM receives as input the sentence vector representation from BERT, to learn the dependencies between the sentences corresponding to images, and the top LSTM is responsible for generating the corresponding word vector representations, taking input from the bottom LSTM. Experimental results demonstrate that our model outperforms most closely related baselines under automatic evaluation metrics BLEU and CIDEr, and also show the effectiveness of our method with human evaluation.
Generating Descriptions for Sequential Images with Local-Object Attention and Global Semantic Context Modelling
Dec 02, 2020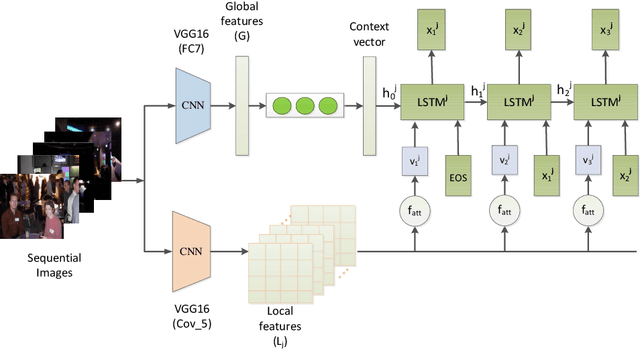
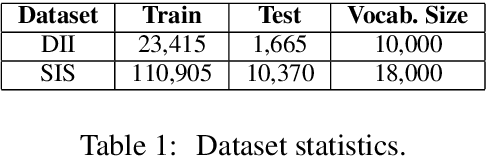

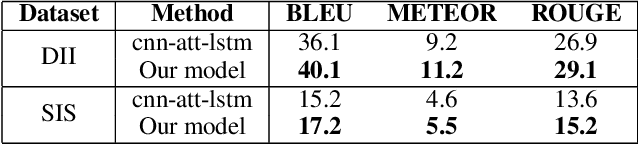
In this paper, we propose an end-to-end CNN-LSTM model for generating descriptions for sequential images with a local-object attention mechanism. To generate coherent descriptions, we capture global semantic context using a multi-layer perceptron, which learns the dependencies between sequential images. A paralleled LSTM network is exploited for decoding the sequence descriptions. Experimental results show that our model outperforms the baseline across three different evaluation metrics on the datasets published by Microsoft.