 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
CSR-Bench: Benchmarking LLM Agents in Deployment of Computer Science Research Repositories
Feb 10, 2025



The increasing complexity of computer science research projects demands more effective tools for deploying code repositories. Large Language Models (LLMs), such as Anthropic Claude and Meta Llama, have demonstrated significant advancements across various fields of computer science research, including the automation of diverse software engineering tasks. To evaluate the effectiveness of LLMs in handling complex code development tasks of research projects, particularly for NLP/CV/AI/ML/DM topics, we introduce CSR-Bench, a benchmark for Computer Science Research projects. This benchmark assesses LLMs from various aspects including accuracy, efficiency, and deployment script quality, aiming to explore their potential in conducting computer science research autonomously. We also introduce a novel framework, CSR-Agents, that utilizes multiple LLM agents to automate the deployment of GitHub code repositories of computer science research projects. Specifically, by checking instructions from markdown files and interpreting repository structures, the model generates and iteratively improves bash commands that set up the experimental environments and deploy the code to conduct research tasks. Preliminary results from CSR-Bench indicate that LLM agents can significantly enhance the workflow of repository deployment, thereby boosting developer productivity and improving the management of developmental workflows.
Learning from Natural Language Explanations for Generalizable Entity Matching
Jun 13, 2024Entity matching is the task of linking records from different sources that refer to the same real-world entity. Past work has primarily treated entity linking as a standard supervised learning problem. However, supervised entity matching models often do not generalize well to new data, and collecting exhaustive labeled training data is often cost prohibitive. Further, recent efforts have adopted LLMs for this task in few/zero-shot settings, exploiting their general knowledge. But LLMs are prohibitively expensive for performing inference at scale for real-world entity matching tasks. As an efficient alternative, we re-cast entity matching as a conditional generation task as opposed to binary classification. This enables us to "distill" LLM reasoning into smaller entity matching models via natural language explanations. This approach achieves strong performance, especially on out-of-domain generalization tests (10.85% F-1) where standalone generative methods struggle. We perform ablations that highlight the importance of explanations, both for performance and model robustness.
GRAM: Generative Retrieval Augmented Matching of Data Schemas in the Context of Data Security
Jun 04, 2024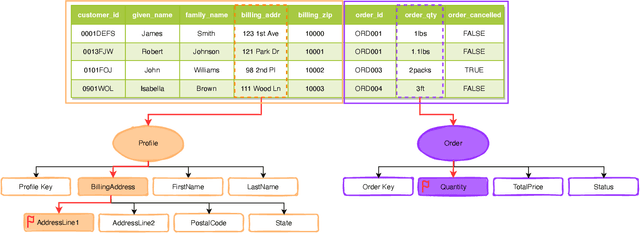
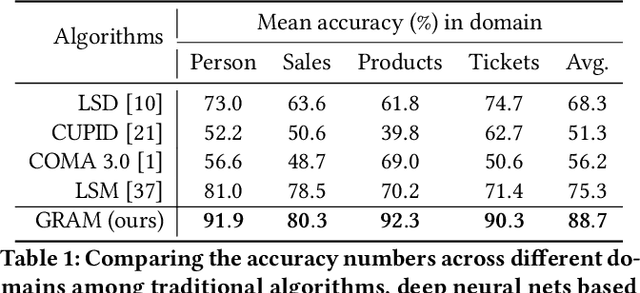

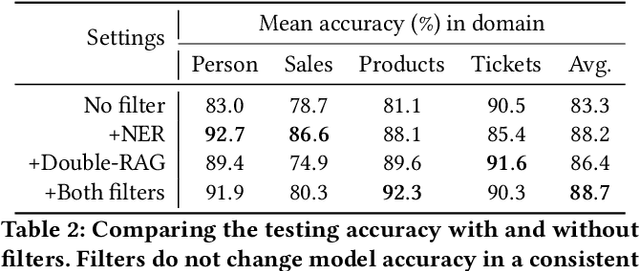
Schema matching constitutes a pivotal phase in the data ingestion process for contemporary database systems. Its objective is to discern pairwise similarities between two sets of attributes, each associated with a distinct data table. This challenge emerges at the initial stages of data analytics, such as when incorporating a third-party table into existing databases to inform business insights. Given its significance in the realm of database systems, schema matching has been under investigation since the 2000s. This study revisits this foundational problem within the context of large language models. Adhering to increasingly stringent data security policies, our focus lies on the zero-shot and few-shot scenarios: the model should analyze only a minimal amount of customer data to execute the matching task, contrasting with the conventional approach of scrutinizing the entire data table. We emphasize that the zero-shot or few-shot assumption is imperative to safeguard the identity and privacy of customer data, even at the potential cost of accuracy. The capability to accurately match attributes under such stringent requirements distinguishes our work from previous literature in this domain.
Neural Locality Sensitive Hashing for Entity Blocking
Jan 31, 2024Locality-sensitive hashing (LSH) is a fundamental algorithmic technique widely employed in large-scale data processing applications, such as nearest-neighbor search, entity resolution, and clustering. However, its applicability in some real-world scenarios is limited due to the need for careful design of hashing functions that align with specific metrics. Existing LSH-based Entity Blocking solutions primarily rely on generic similarity metrics such as Jaccard similarity, whereas practical use cases often demand complex and customized similarity rules surpassing the capabilities of generic similarity metrics. Consequently, designing LSH functions for these customized similarity rules presents considerable challenges. In this research, we propose a neuralization approach to enhance locality-sensitive hashing by training deep neural networks to serve as hashing functions for complex metrics. We assess the effectiveness of this approach within the context of the entity resolution problem, which frequently involves the use of task-specific metrics in real-world applications. Specifically, we introduce NLSHBlock (Neural-LSH Block), a novel blocking methodology that leverages pre-trained language models, fine-tuned with a novel LSH-based loss function. Through extensive evaluations conducted on a diverse range of real-world datasets, we demonstrate the superiority of NLSHBlock over existing methods, exhibiting significant performance improvements. Furthermore, we showcase the efficacy of NLSHBlock in enhancing the performance of the entity matching phase, particularly within the semi-supervised setting.
Natural Language is All a Graph Needs
Aug 24, 2023The emergence of large-scale pre-trained language models, such as ChatGPT, has revolutionized various research fields in artificial intelligence. Transformers-based large language models (LLMs) have gradually replaced CNNs and RNNs to unify fields of computer vision and natural language processing. Compared with the data that exists relatively independently such as images, videos or texts, graph is a type of data that contains rich structural and relational information. Meanwhile, natural language, as one of the most expressive mediums, excels in describing complex structures. However, existing work on incorporating graph learning problems into the generative language modeling framework remains very limited. As the importance of large language models continues to grow, it becomes essential to explore whether LLMs can also replace GNNs as the foundation model for graphs. In this paper, we propose InstructGLM (Instruction-finetuned Graph Language Model), systematically design highly scalable prompts based on natural language instructions, and use natural language to describe the geometric structure and node features of the graph for instruction tuning an LLM to perform learning and inference on graphs in a generative manner. Our method exceeds all competitive GNN baselines on ogbn-arxiv, Cora and PubMed datasets, which demonstrates the effectiveness of our method and sheds light on generative large language models as the foundation model for graph machine learning.