 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairRank: Online Pairwise Learning to Rank by Divide-and-Conquer
Paper and Code
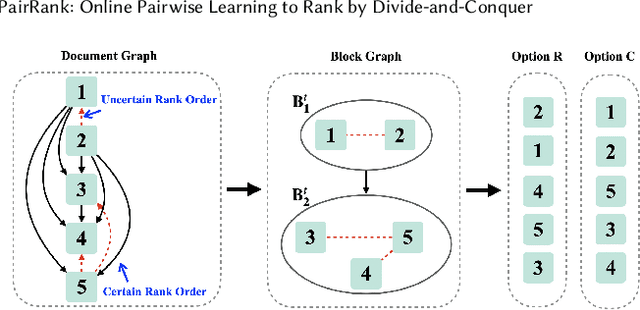
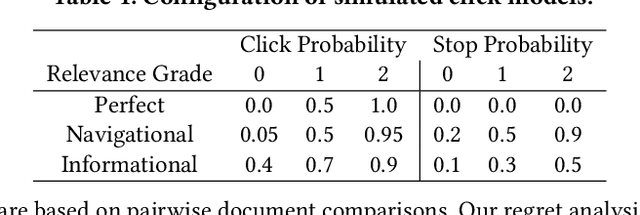

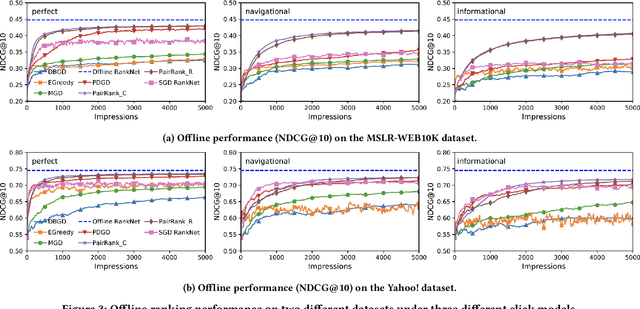
Online Learning to Rank (OL2R) eliminates the need of explicit relevance annotation by directly optimizing the rankers from their interactions with users. However, the required exploration drives it away from successful practices in offline learning to rank, which limits OL2R's empirical performance and practical applicability. In this work, we propose to estimate a pairwise learning to rank model online. In each round, candidate documents are partitioned and ranked according to the model's confidence on the estimated pairwise rank order, and exploration is only performed on the uncertain pairs of documents, i.e., \emph{divide-and-conquer}. Regret directly defined on the number of mis-ordered pairs is proven, which connects the online solution's theoretical convergence with its expected ranking performance. Comparisons against an extensive list of OL2R baselines on two public learning to rank benchmark datasets demonstrate the effectiveness of the proposed solution.