 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification on Graph Learning: A Survey
Apr 23, 2024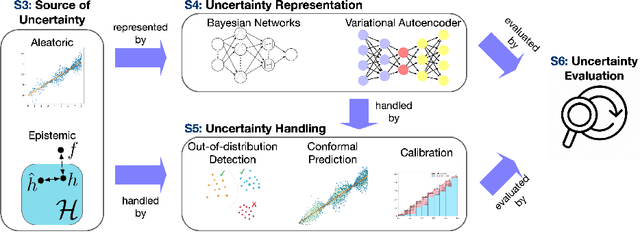
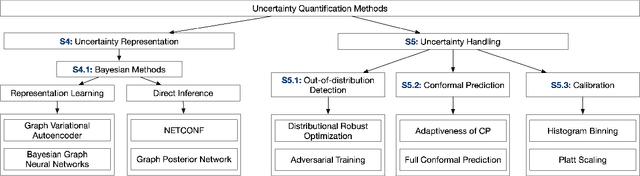
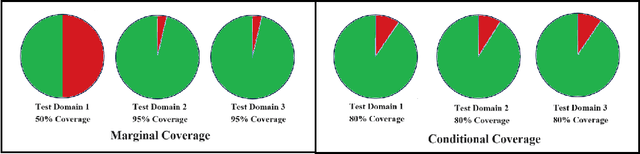
Graphical models, including Graph Neural Networks (GNNs) and Probabilistic Graphical Models (PGMs), have demonstrated their exceptional capabilities across numerous fields. These models necessitate effective uncertainty quantification to ensure reliable decision-making amid the challenges posed by model training discrepancies and unpredictable testing scenarios. This survey examines recent works that address uncertainty quantification within the model architectures, training, and inference of GNNs and PGMs. We aim to provide an overview of the current landscape of uncertainty in graphical models by organizing the recent methods into uncertainty representation and handling. By summarizing state-of-the-art methods, this survey seeks to deepen the understanding of uncertainty quantification in graphical models, thereby increasing their effectiveness and safety in critical applications.
Robust Ranking Explanations
Jul 08, 2023



Robust explanations of machine learning models are critical to establish human trust in the models. Due to limited cognition capability, most humans can only interpret the top few salient features. It is critical to make top salient features robust to adversarial attacks, especially those against the more vulnerable gradient-based explanations. Existing defense measures robustness using $\ell_p$-norms, which have weaker protection power. We define explanation thickness for measuring salient features ranking stability, and derive tractable surrogate bounds of the thickness to design the \textit{R2ET} algorithm to efficiently maximize the thickness and anchor top salient features. Theoretically, we prove a connection between R2ET and adversarial training. Experiments with a wide spectrum of network architectures and data modalities, including brain networks, demonstrate that R2ET attains higher explanation robustness under stealthy attacks while retaining accuracy.