 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Embedding Models Perform Well for Knowledge Base Completion?
Paper and Code
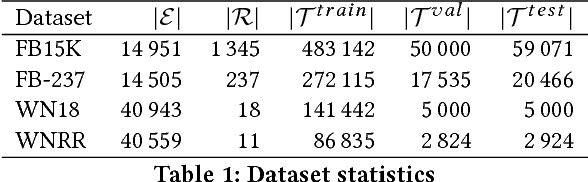
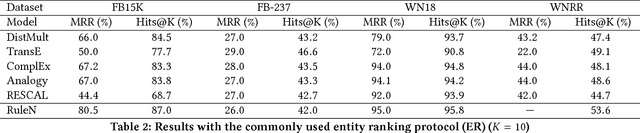
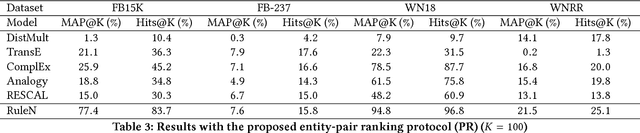
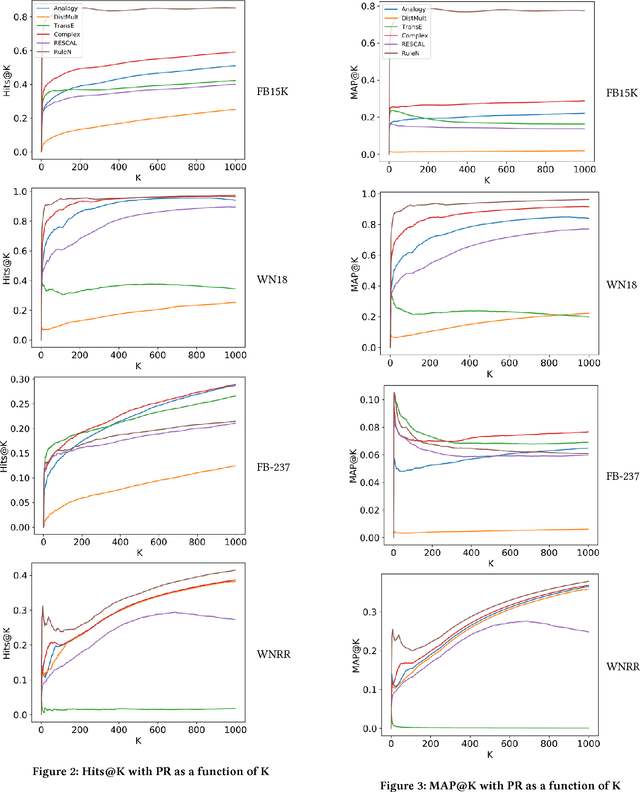
In this work, we put into question the effectiveness of the evaluation methods currently used to measure the performance of latent factor models for the task of knowledge base completion. We argue that by focusing on a small subset of possible facts in the knowledge base, current evaluation practices are better suited for question answering tasks, rather than knowledge base completion, where it is also important to avoid the addition of incorrect facts into the knowledge base. We illustrate our point by showing how models with limited expressiveness achieve state-of-the-art performance, even while adding many incorrect (even nonsensical) facts to a knowledge base. Finally, we show that when using a simple evaluation procedure designed to also penalize the addition of incorrect facts, the general and relative performance of all models looks very different than previously seen. This indicates the need for more powerful latent factor models for the task of knowledge base completion.