 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Hallucinations of Medical Multimodal Large Language Models with Visual Retrieval-Augmented Generation
Feb 20, 2025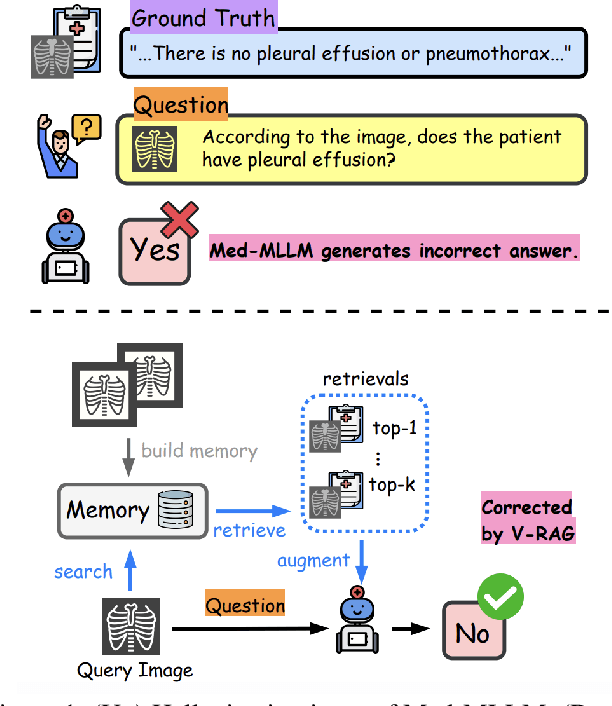
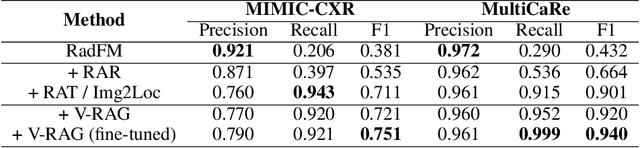
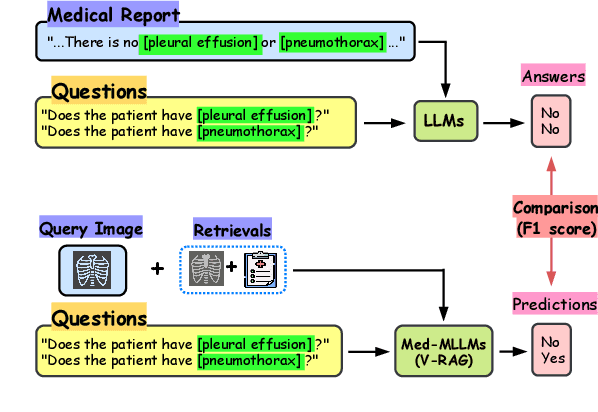
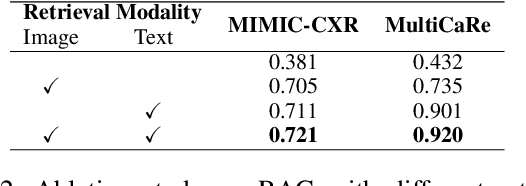
Multimodal Large Language Models (MLLMs) have shown impressive performance in vision and text tasks. However, hallucination remains a major challenge, especially in fields like healthcare where details are critical. In this work, we show how MLLMs may be enhanced to support Visual RAG (V-RAG), a retrieval-augmented generation framework that incorporates both text and visual data from retrieved images. On the MIMIC-CXR chest X-ray report generation and Multicare medical image caption generation datasets, we show that Visual RAG improves the accuracy of entity probing, which asks whether a medical entities is grounded by an image. We show that the improvements extend both to frequent and rare entities, the latter of which may have less positive training data. Downstream, we apply V-RAG with entity probing to correct hallucinations and generate more clinically accurate X-ray reports, obtaining a higher RadGraph-F1 score.
Unlocking the Potential of Model Calibration in Federated Learning
Sep 07, 2024



Over the past several years, various federated learning (FL) methodologies have been developed to improve model accuracy, a primary performance metric in machine learning. However, to utilize FL in practical decision-making scenarios, beyond considering accuracy, the trained model must also have a reliable confidence in each of its predictions, an aspect that has been largely overlooked in existing FL research. Motivated by this gap, we propose Non-Uniform Calibration for Federated Learning (NUCFL), a generic framework that integrates FL with the concept of model calibration. The inherent data heterogeneity in FL environments makes model calibration particularly difficult, as it must ensure reliability across diverse data distributions and client conditions. Our NUCFL addresses this challenge by dynamically adjusting the model calibration objectives based on statistical relationships between each client's local model and the global model in FL. In particular, NUCFL assesses the similarity between local and global model relationships, and controls the penalty term for the calibration loss during client-side local training. By doing so, NUCFL effectively aligns calibration needs for the global model in heterogeneous FL settings while not sacrificing accuracy. Extensive experiments show that NUCFL offers flexibility and effectiveness across various FL algorithms, enhancing accuracy as well as model calibration.
Rethinking the Starting Point: Enhancing Performance and Fairness of Federated Learning via Collaborative Pre-Training
Feb 03, 2024

Most existing federated learning (FL) methodologies have assumed training begins from a randomly initialized model. Recently, several studies have empirically demonstrated that leveraging a pre-trained model can offer advantageous initializations for FL. In this paper, we propose a collaborative pre-training approach, CoPreFL, which strategically designs a pre-trained model to serve as a good initialization for any downstream FL task. The key idea of our pre-training algorithm is a meta-learning procedure which mimics downstream distributed scenarios, enabling it to adapt to any unforeseen FL task. CoPreFL's pre-training optimization procedure also strikes a balance between average performance and fairness, with the aim of addressing these competing challenges in downstream FL tasks through intelligent initializations. Extensive experimental results validate that our pre-training method provides a robust initialization for any unseen downstream FL task, resulting in enhanced average performance and more equitable predictions.
Only Send What You Need: Learning to Communicate Efficiently in Federated Multilingual Machine Translation
Jan 15, 2024
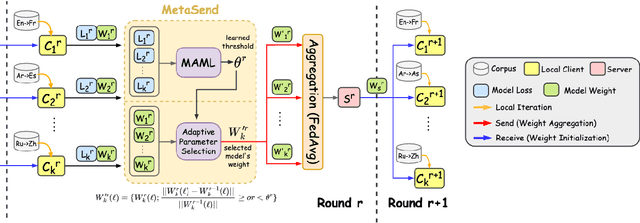

Federated learning (FL) is a promising approach for solving multilingual tasks, potentially enabling clients with their own language-specific data to collaboratively construct a high-quality neural machine translation (NMT) model. However, communication constraints in practical network systems present challenges for exchanging large-scale NMT engines between FL parties. In this paper, we propose a meta-learning-based adaptive parameter selection methodology, MetaSend, that improves the communication efficiency of model transmissions from clients during FL-based multilingual NMT training. Our approach learns a dynamic threshold for filtering parameters prior to transmission without compromising the NMT model quality, based on the tensor deviations of clients between different FL rounds. Through experiments on two NMT datasets with different language distributions, we demonstrate that MetaSend obtains substantial improvements over baselines in translation quality in the presence of a limited communication budget.
Multi-Layer Personalized Federated Learning for Mitigating Biases in Student Predictive Analytics
Dec 05, 2022



Traditional learning-based approaches to student modeling (e.g., predicting grades based on measured activities) generalize poorly to underrepresented/minority student groups due to biases in data availability. In this paper, we propose a Multi-Layer Personalized Federated Learning (MLPFL) methodology which optimizes inference accuracy over different layers of student grouping criteria, such as by course and by demographic subgroups within each course. In our approach, personalized models for individual student subgroups are derived from a global model, which is trained in a distributed fashion via meta-gradient updates that account for subgroup heterogeneity while preserving modeling commonalities that exist across the full dataset. To evaluate our methodology, we consider case studies of two popular downstream student modeling tasks, knowledge tracing and outcome prediction, which leverage multiple modalities of student behavior (e.g., visits to lecture videos and participation on forums) in model training. Experiments on three real-world datasets from online courses demonstrate that our approach obtains substantial improvements over existing student modeling baselines in terms of increasing the average and decreasing the variance of prediction quality across different student subgroups. Visual analysis of the resulting students' knowledge state embeddings confirm that our personalization methodology extracts activity patterns which cluster into different student subgroups, consistent with the performance enhancements we obtain over the baselines.
Mitigating Biases in Student Performance Prediction via Attention-Based Personalized Federated Learning
Aug 02, 2022
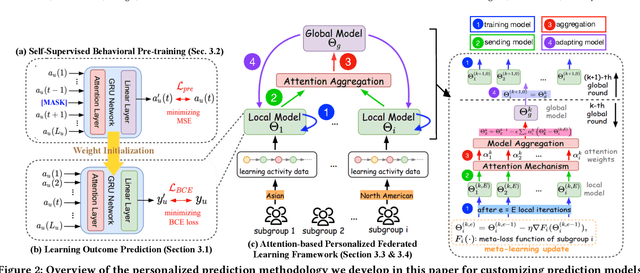
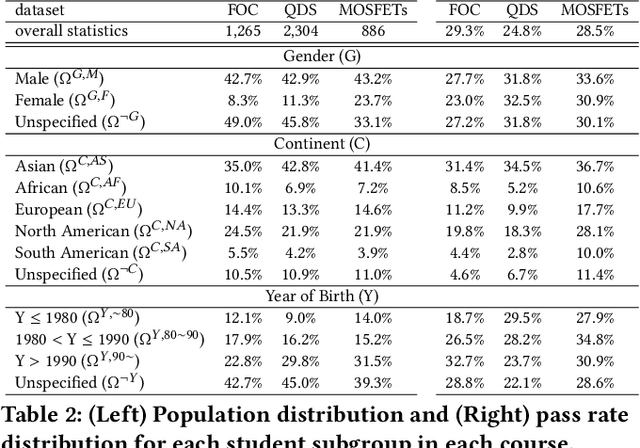
Traditional learning-based approaches to student modeling generalize poorly to underrepresented student groups due to biases in data availability. In this paper, we propose a methodology for predicting student performance from their online learning activities that optimizes inference accuracy over different demographic groups such as race and gender. Building upon recent foundations in federated learning, in our approach, personalized models for individual student subgroups are derived from a global model aggregated across all student models via meta-gradient updates that account for subgroup heterogeneity. To learn better representations of student activity, we augment our approach with a self-supervised behavioral pretraining methodology that leverages multiple modalities of student behavior (e.g., visits to lecture videos and participation on forums), and include a neural network attention mechanism in the model aggregation stage. Through experiments on three real-world datasets from online courses, we demonstrate that our approach obtains substantial improvements over existing student modeling baselines in predicting student learning outcomes for all subgroups. Visual analysis of the resulting student embeddings confirm that our personalization methodology indeed identifies different activity patterns within different subgroups, consistent with its stronger inference ability compared with the baselines.
Let's Talk! Striking Up Conversations via Conversational Visual Question Generation
May 19, 2022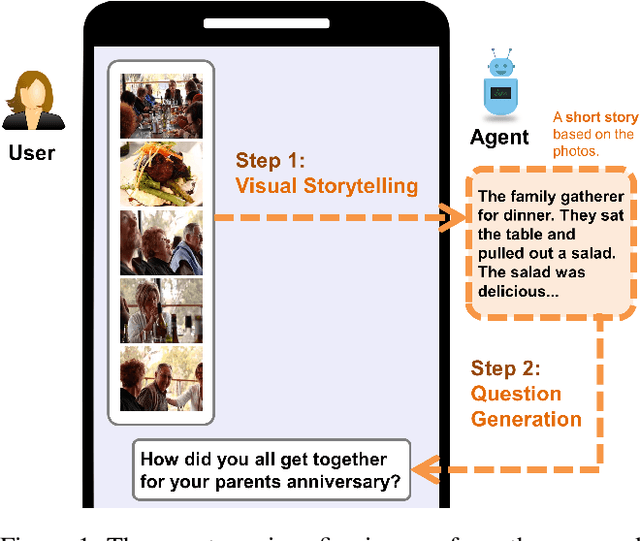

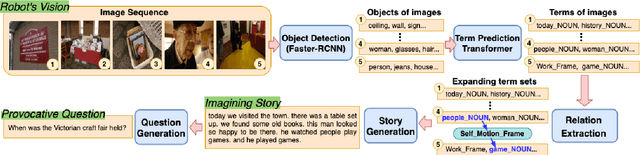

An engaging and provocative question can open up a great conversation. In this work, we explore a novel scenario: a conversation agent views a set of the user's photos (for example, from social media platforms) and asks an engaging question to initiate a conversation with the user. The existing vision-to-question models mostly generate tedious and obvious questions, which might not be ideals conversation starters. This paper introduces a two-phase framework that first generates a visual story for the photo set and then uses the story to produce an interesting question. The human evaluation shows that our framework generates more response-provoking questions for starting conversations than other vision-to-question baselines.
Click-Based Student Performance Prediction: A Clustering Guided Meta-Learning Approach
Nov 16, 2021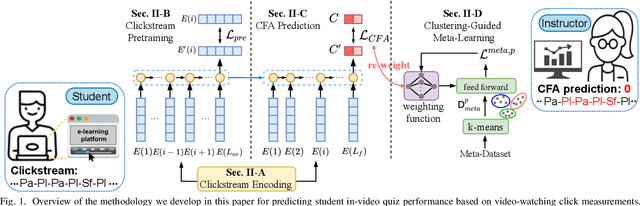
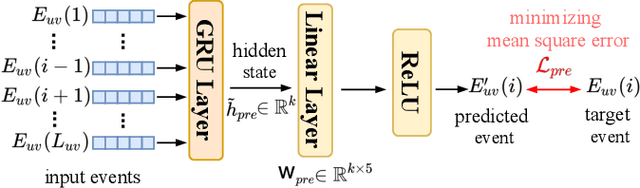
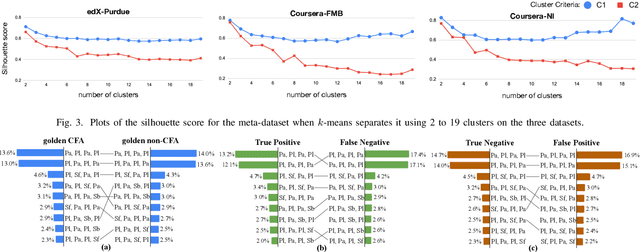
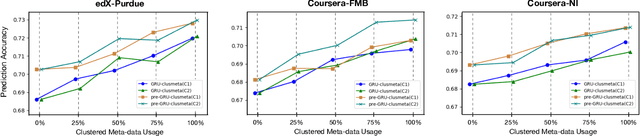
We study the problem of predicting student knowledge acquisition in online courses from clickstream behavior. Motivated by the proliferation of eLearning lecture delivery, we specifically focus on student in-video activity in lectures videos, which consist of content and in-video quizzes. Our methodology for predicting in-video quiz performance is based on three key ideas we develop. First, we model students' clicking behavior via time-series learning architectures operating on raw event data, rather than defining hand-crafted features as in existing approaches that may lose important information embedded within the click sequences. Second, we develop a self-supervised clickstream pre-training to learn informative representations of clickstream events that can initialize the prediction model effectively. Third, we propose a clustering guided meta-learning-based training that optimizes the prediction model to exploit clusters of frequent patterns in student clickstream sequences. Through experiments on three real-world datasets, we demonstrate that our method obtains substantial improvements over two baseline models in predicting students' in-video quiz performance. Further, we validate the importance of the pre-training and meta-learning components of our framework through ablation studies. Finally, we show how our methodology reveals insights on video-watching behavior associated with knowledge acquisition for useful learning analytics.
Plot and Rework: Modeling Storylines for Visual Storytelling
May 23, 2021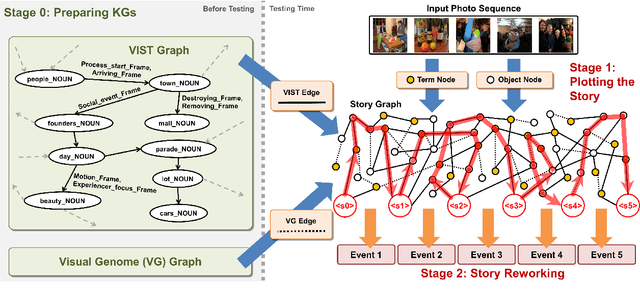



Writing a coherent and engaging story is not easy. Creative writers use their knowledge and worldview to put disjointed elements together to form a coherent storyline, and work and rework iteratively toward perfection. Automated visual storytelling (VIST) models, however, make poor use of external knowledge and iterative generation when attempting to create stories. This paper introduces PR-VIST, a framework that represents the input image sequence as a story graph in which it finds the best path to form a storyline. PR-VIST then takes this path and learns to generate the final story via an iterative training process. This framework produces stories that are superior in terms of diversity, coherence, and humanness, per both automatic and human evaluations. An ablation study shows that both plotting and reworking contribute to the model's superiority.
MVIN: Learning Multiview Items for Recommendation
May 26, 2020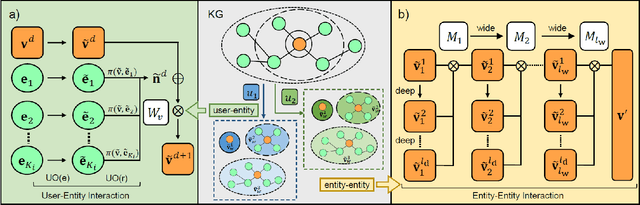
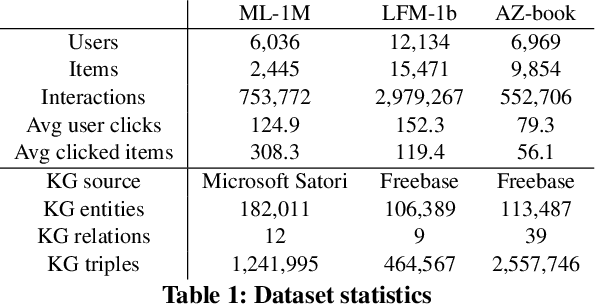
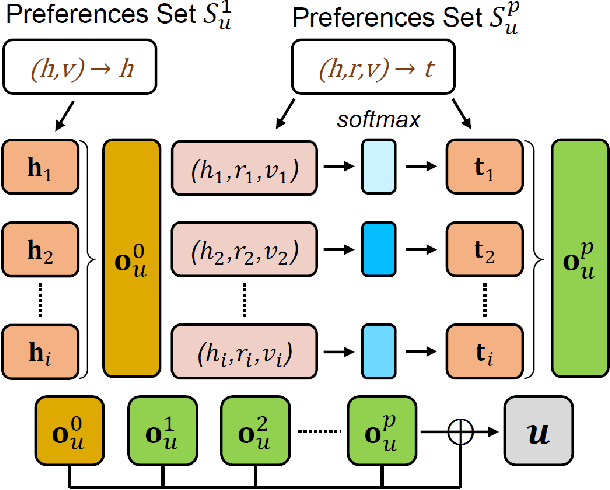
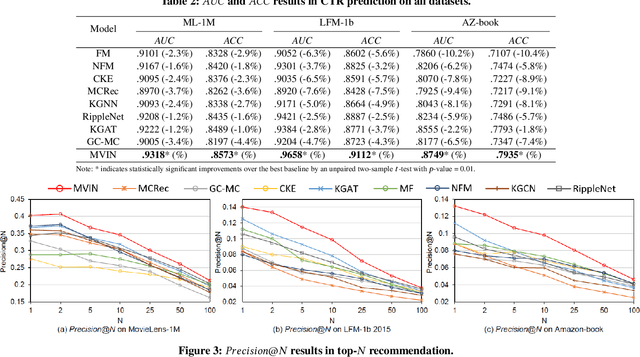
Researchers have begun to utilize heterogeneous knowledge graphs (KGs) as auxiliary information in recommendation systems to mitigate the cold start and sparsity issues. However, utilizing a graph neural network (GNN) to capture information in KG and further apply in RS is still problematic as it is unable to see each item's properties from multiple perspectives. To address these issues, we propose the multi-view item network (MVIN), a GNN-based recommendation model which provides superior recommendations by describing items from a unique mixed view from user and entity angles. MVIN learns item representations from both the user view and the entity view. From the user view, user-oriented modules score and aggregate features to make recommendations from a personalized perspective constructed according to KG entities which incorporates user click information. From the entity view, the mixing layer contrasts layer-wise GCN information to further obtain comprehensive features from internal entity-entity interactions in the KG. We evaluate MVIN on three real-world datasets: MovieLens-1M (ML-1M), LFM-1b 2015 (LFM-1b), and Amazon-Book (AZ-book). Results show that MVIN significantly outperforms state-of-the-art methods on these three datasets. In addition, from user-view cases, we find that MVIN indeed captures entities that attract users. Figures further illustrate that mixing layers in a heterogeneous KG plays a vital role in neighborhood information aggregation.