 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlot and Rework: Modeling Storylines for Visual Storytelling
Paper and Code
May 23, 2021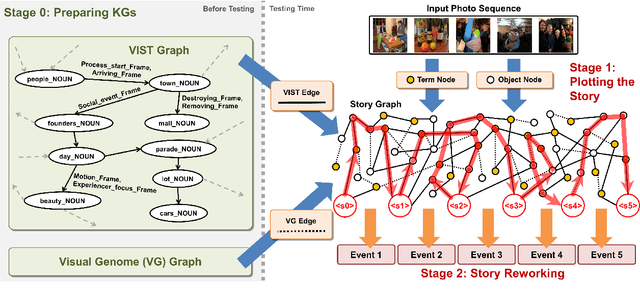



Writing a coherent and engaging story is not easy. Creative writers use their knowledge and worldview to put disjointed elements together to form a coherent storyline, and work and rework iteratively toward perfection. Automated visual storytelling (VIST) models, however, make poor use of external knowledge and iterative generation when attempting to create stories. This paper introduces PR-VIST, a framework that represents the input image sequence as a story graph in which it finds the best path to form a storyline. PR-VIST then takes this path and learns to generate the final story via an iterative training process. This framework produces stories that are superior in terms of diversity, coherence, and humanness, per both automatic and human evaluations. An ablation study shows that both plotting and reworking contribute to the model's superiority.