 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVIN: Learning Multiview Items for Recommendation
May 26, 2020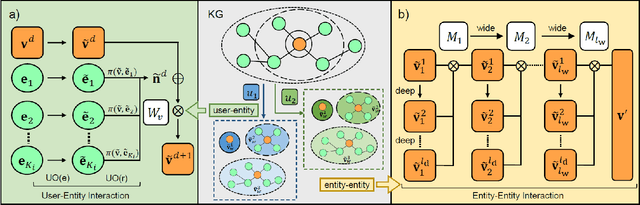
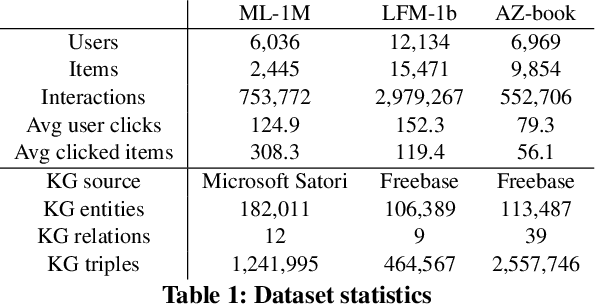
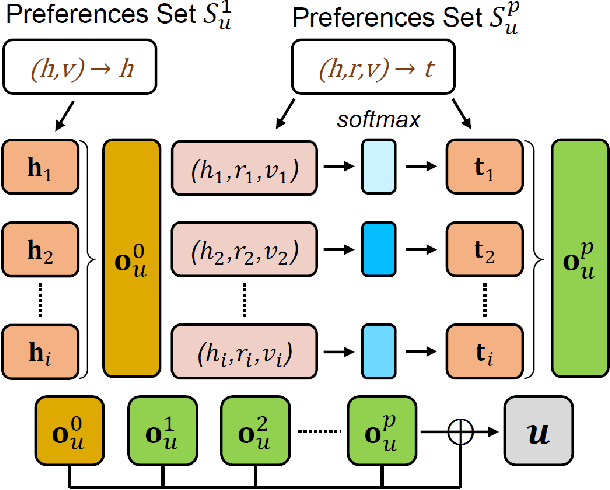
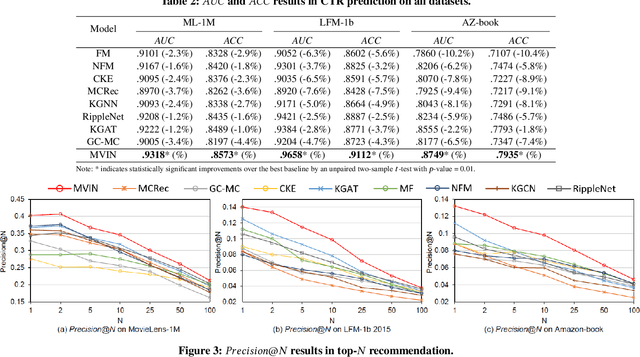
Researchers have begun to utilize heterogeneous knowledge graphs (KGs) as auxiliary information in recommendation systems to mitigate the cold start and sparsity issues. However, utilizing a graph neural network (GNN) to capture information in KG and further apply in RS is still problematic as it is unable to see each item's properties from multiple perspectives. To address these issues, we propose the multi-view item network (MVIN), a GNN-based recommendation model which provides superior recommendations by describing items from a unique mixed view from user and entity angles. MVIN learns item representations from both the user view and the entity view. From the user view, user-oriented modules score and aggregate features to make recommendations from a personalized perspective constructed according to KG entities which incorporates user click information. From the entity view, the mixing layer contrasts layer-wise GCN information to further obtain comprehensive features from internal entity-entity interactions in the KG. We evaluate MVIN on three real-world datasets: MovieLens-1M (ML-1M), LFM-1b 2015 (LFM-1b), and Amazon-Book (AZ-book). Results show that MVIN significantly outperforms state-of-the-art methods on these three datasets. In addition, from user-view cases, we find that MVIN indeed captures entities that attract users. Figures further illustrate that mixing layers in a heterogeneous KG plays a vital role in neighborhood information aggregation.
GraphSW: a training protocol based on stage-wise training for GNN-based Recommender Model
Aug 19, 2019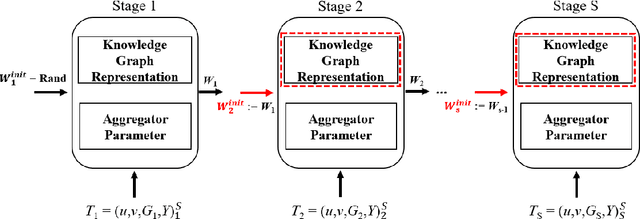
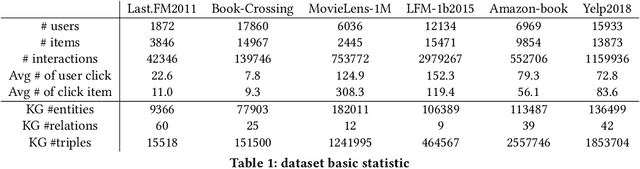


Recently, researchers utilize Knowledge Graph (KG) as side information in recommendation system to address cold start and sparsity issue and improve the recommendation performance. Existing KG-aware recommendation model use the feature of neighboring entities and structural information to update the embedding of currently located entity. Although the fruitful information is beneficial to the following task, the cost of exploring the entire graph is massive and impractical. In order to reduce the computational cost and maintain the pattern of extracting features, KG-aware recommendation model usually utilize fixed-size and random set of neighbors rather than complete information in KG. Nonetheless, there are two critical issues in these approaches: First of all, fixed-size and randomly selected neighbors restrict the view of graph. In addition, as the order of graph feature increases, the growth of parameter dimensionality of the model may lead the training process hard to converge. To solve the aforementioned limitations, we propose GraphSW, a strategy based on stage-wise training framework which would only access to a subset of the entities in KG in every stage. During the following stages, the learned embedding from previous stages is provided to the network in the next stage and the model can learn the information gradually from the KG. We apply stage-wise training on two SOTA recommendation models, RippleNet and Knowledge Graph Convolutional Networks (KGCN). Moreover, we evaluate the performance on six real world datasets, Last.FM 2011, Book-Crossing,movie, LFM-1b 2015, Amazon-book and Yelp 2018. The result of our experiments shows that proposed strategy can help both models to collect more information from the KG and improve the performance. Furthermore, it is observed that GraphSW can assist KGCN to converge effectively in high-order graph feature.