 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClick-Based Student Performance Prediction: A Clustering Guided Meta-Learning Approach
Nov 16, 2021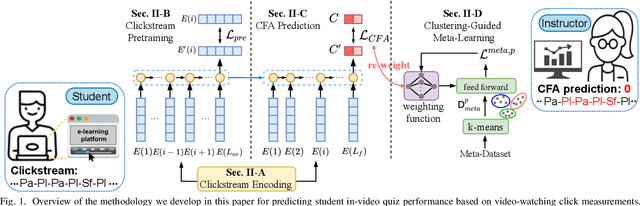
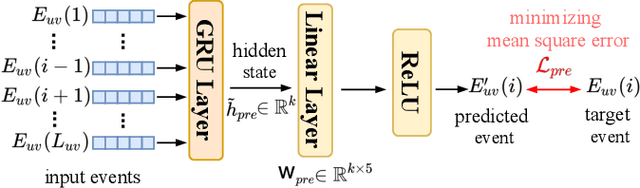
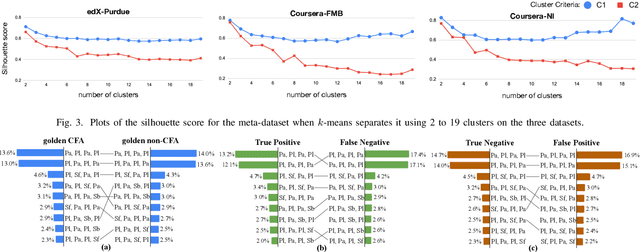
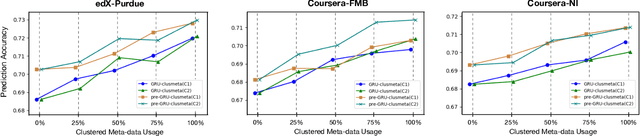
We study the problem of predicting student knowledge acquisition in online courses from clickstream behavior. Motivated by the proliferation of eLearning lecture delivery, we specifically focus on student in-video activity in lectures videos, which consist of content and in-video quizzes. Our methodology for predicting in-video quiz performance is based on three key ideas we develop. First, we model students' clicking behavior via time-series learning architectures operating on raw event data, rather than defining hand-crafted features as in existing approaches that may lose important information embedded within the click sequences. Second, we develop a self-supervised clickstream pre-training to learn informative representations of clickstream events that can initialize the prediction model effectively. Third, we propose a clustering guided meta-learning-based training that optimizes the prediction model to exploit clusters of frequent patterns in student clickstream sequences. Through experiments on three real-world datasets, we demonstrate that our method obtains substantial improvements over two baseline models in predicting students' in-video quiz performance. Further, we validate the importance of the pre-training and meta-learning components of our framework through ablation studies. Finally, we show how our methodology reveals insights on video-watching behavior associated with knowledge acquisition for useful learning analytics.
Math Word Problem Generation with Mathematical Consistency and Problem Context Constraints
Sep 09, 2021
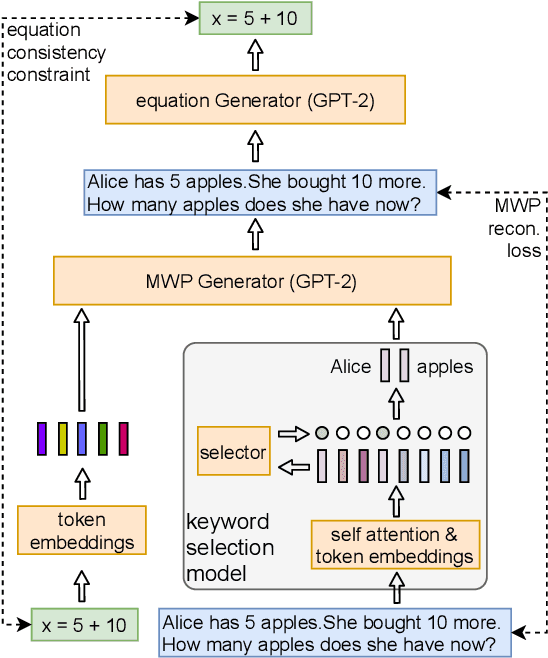


We study the problem of generating arithmetic math word problems (MWPs) given a math equation that specifies the mathematical computation and a context that specifies the problem scenario. Existing approaches are prone to generating MWPs that are either mathematically invalid or have unsatisfactory language quality. They also either ignore the context or require manual specification of a problem template, which compromises the diversity of the generated MWPs. In this paper, we develop a novel MWP generation approach that leverages i) pre-trained language models and a context keyword selection model to improve the language quality of the generated MWPs and ii) an equation consistency constraint for math equations to improve the mathematical validity of the generated MWPs. Extensive quantitative and qualitative experiments on three real-world MWP datasets demonstrate the superior performance of our approach compared to various baselines.
Context-Aware Attentive Knowledge Tracing
Jul 24, 2020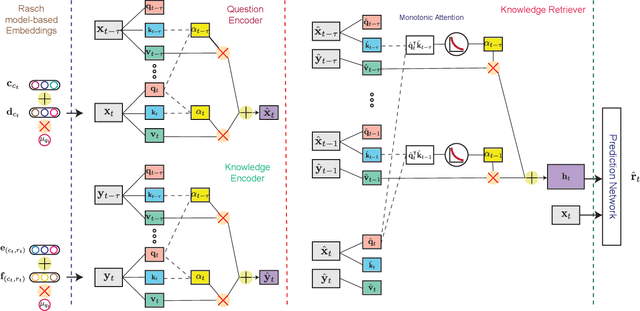

Knowledge tracing (KT) refers to the problem of predicting future learner performance given their past performance in educational applications. Recent developments in KT using flexible deep neural network-based models excel at this task. However, these models often offer limited interpretability, thus making them insufficient for personalized learning, which requires using interpretable feedback and actionable recommendations to help learners achieve better learning outcomes. In this paper, we propose attentive knowledge tracing (AKT), which couples flexible attention-based neural network models with a series of novel, interpretable model components inspired by cognitive and psychometric models. AKT uses a novel monotonic attention mechanism that relates a learner's future responses to assessment questions to their past responses; attention weights are computed using exponential decay and a context-aware relative distance measure, in addition to the similarity between questions. Moreover, we use the Rasch model to regularize the concept and question embeddings; these embeddings are able to capture individual differences among questions on the same concept without using an excessive number of parameters. We conduct experiments on several real-world benchmark datasets and show that AKT outperforms existing KT methods (by up to $6\%$ in AUC in some cases) on predicting future learner responses. We also conduct several case studies and show that AKT exhibits excellent interpretability and thus has potential for automated feedback and personalization in real-world educational settings.
qDKT: Question-centric Deep Knowledge Tracing
May 25, 2020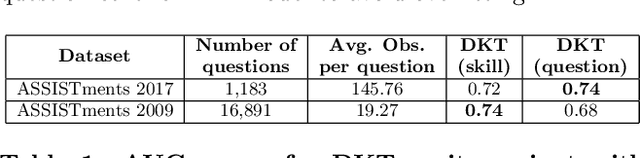
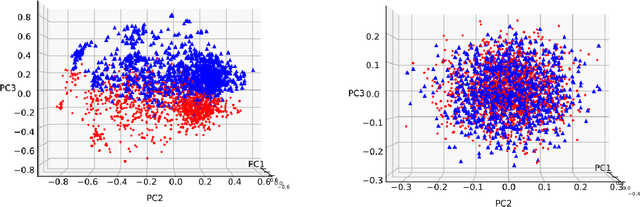

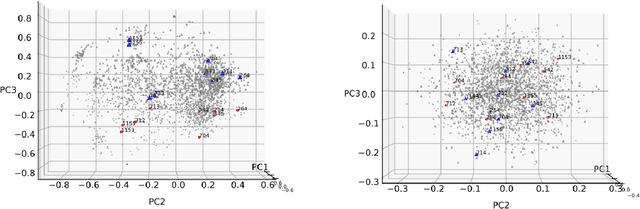
Knowledge tracing (KT) models, e.g., the deep knowledge tracing (DKT) model, track an individual learner's acquisition of skills over time by examining the learner's performance on questions related to those skills. A practical limitation in most existing KT models is that all questions nested under a particular skill are treated as equivalent observations of a learner's ability, which is an inaccurate assumption in real-world educational scenarios. To overcome this limitation we introduce qDKT, a variant of DKT that models every learner's success probability on individual questions over time. First, qDKT incorporates graph Laplacian regularization to smooth predictions under each skill, which is particularly useful when the number of questions in the dataset is big. Second, qDKT uses an initialization scheme inspired by the fastText algorithm, which has found success in a variety of language modeling tasks. Our experiments on several real-world datasets show that qDKT achieves state-of-art performance on predicting learner outcomes. Because of this, qDKT can serve as a simple, yet tough-to-beat, baseline for new question-centric KT models.
MSE-Optimal Neural Network Initialization via Layer Fusion
Jan 28, 2020
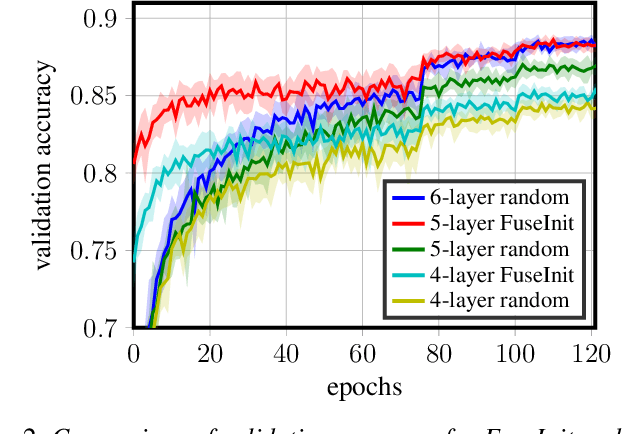


Deep neural networks achieve state-of-the-art performance for a range of classification and inference tasks. However, the use of stochastic gradient descent combined with the nonconvexity of the underlying optimization problems renders parameter learning susceptible to initialization. To address this issue, a variety of methods that rely on random parameter initialization or knowledge distillation have been proposed in the past. In this paper, we propose FuseInit, a novel method to initialize shallower networks by fusing neighboring layers of deeper networks that are trained with random initialization. We develop theoretical results and efficient algorithms for mean-square error (MSE)-optimal fusion of neighboring dense-dense, convolutional-dense, and convolutional-convolutional layers. We show experiments for a range of classification and regression datasets, which suggest that deeper neural networks are less sensitive to initialization and shallower networks can perform better (sometimes as well as their deeper counterparts) if initialized with FuseInit.
IdeoTrace: A Framework for Ideology Tracing with a Case Study on the 2016 U.S. Presidential Election
May 30, 2019
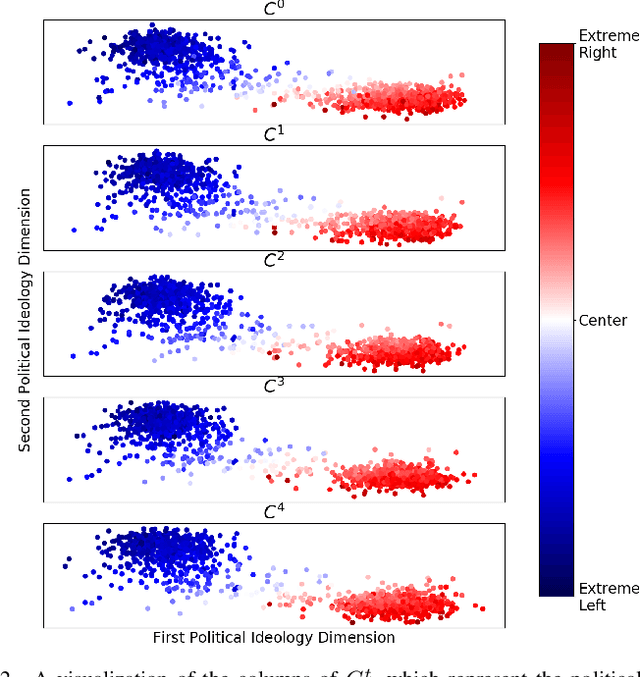
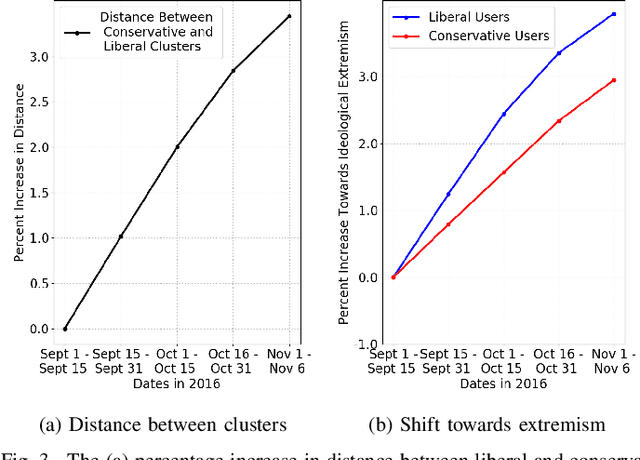
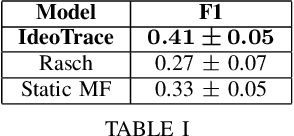
The 2016 United States presidential election has been characterized as a period of extreme divisiveness that was exacerbated on social media by the influence of fake news, trolls, and social bots. However, the extent to which the public became more polarized in response to these influences over the course of the election is not well understood. In this paper we propose IdeoTrace, a framework for (i) jointly estimating the ideology of social media users and news websites and (ii) tracing changes in user ideology over time. We apply this framework to the last two months of the election period for a group of 47508 Twitter users and demonstrate that both liberal and conservative users became more polarized over time.
An Estimation and Analysis Framework for the Rasch Model
Jun 09, 2018
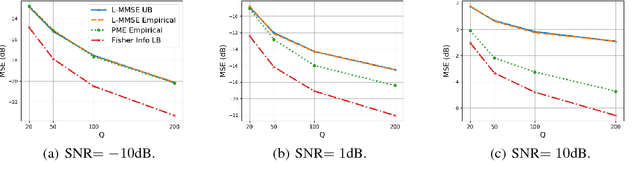
The Rasch model is widely used for item response analysis in applications ranging from recommender systems to psychology, education, and finance. While a number of estimators have been proposed for the Rasch model over the last decades, the available analytical performance guarantees are mostly asymptotic. This paper provides a framework that relies on a novel linear minimum mean-squared error (L-MMSE) estimator which enables an exact, nonasymptotic, and closed-form analysis of the parameter estimation error under the Rasch model. The proposed framework provides guidelines on the number of items and responses required to attain low estimation errors in tests or surveys. We furthermore demonstrate its efficacy on a number of real-world collaborative filtering datasets, which reveals that the proposed L-MMSE estimator performs on par with state-of-the-art nonlinear estimators in terms of predictive performance.
Linear Spectral Estimators and an Application to Phase Retrieval
Jun 09, 2018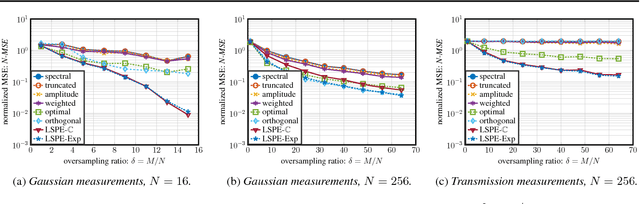
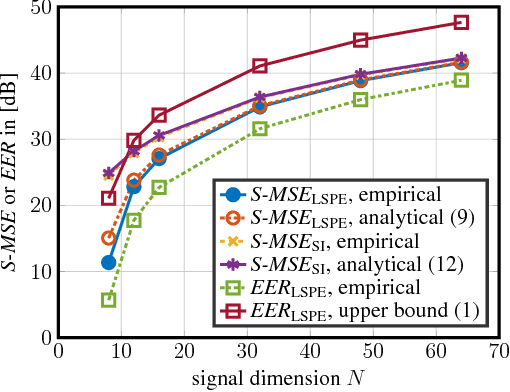


Phase retrieval refers to the problem of recovering real- or complex-valued vectors from magnitude measurements. The best-known algorithms for this problem are iterative in nature and rely on so-called spectral initializers that provide accurate initialization vectors. We propose a novel class of estimators suitable for general nonlinear measurement systems, called linear spectral estimators (LSPEs), which can be used to compute accurate initialization vectors for phase retrieval problems. The proposed LSPEs not only provide accurate initialization vectors for noisy phase retrieval systems with structured or random measurement matrices, but also enable the derivation of sharp and nonasymptotic mean-squared error bounds. We demonstrate the efficacy of LSPEs on synthetic and real-world phase retrieval problems, and show that our estimators significantly outperform existing methods for structured measurement systems that arise in practice.
Linearized Binary Regression
Feb 01, 2018

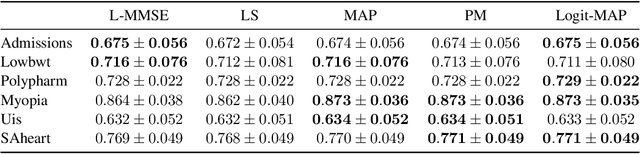
Probit regression was first proposed by Bliss in 1934 to study mortality rates of insects. Since then, an extensive body of work has analyzed and used probit or related binary regression methods (such as logistic regression) in numerous applications and fields. This paper provides a fresh angle to such well-established binary regression methods. Concretely, we demonstrate that linearizing the probit model in combination with linear estimators performs on par with state-of-the-art nonlinear regression methods, such as posterior mean or maximum aposteriori estimation, for a broad range of real-world regression problems. We derive exact, closed-form, and nonasymptotic expressions for the mean-squared error of our linearized estimators, which clearly separates them from nonlinear regression methods that are typically difficult to analyze. We showcase the efficacy of our methods and results for a number of synthetic and real-world datasets, which demonstrates that linearized binary regression finds potential use in a variety of inference, estimation, signal processing, and machine learning applications that deal with binary-valued observations or measurements.
Data-Mining Textual Responses to Uncover Misconception Patterns
Mar 30, 2017
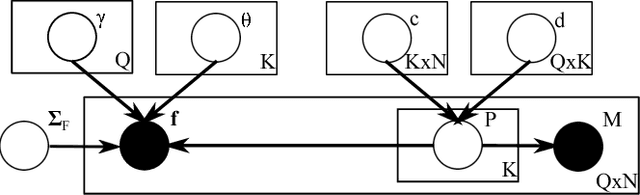


An important, yet largely unstudied, problem in student data analysis is to detect misconceptions from students' responses to open-response questions. Misconception detection enables instructors to deliver more targeted feedback on the misconceptions exhibited by many students in their class, thus improving the quality of instruction. In this paper, we propose a new natural language processing-based framework to detect the common misconceptions among students' textual responses to short-answer questions. We propose a probabilistic model for students' textual responses involving misconceptions and experimentally validate it on a real-world student-response dataset. Experimental results show that our proposed framework excels at classifying whether a response exhibits one or more misconceptions. More importantly, it can also automatically detect the common misconceptions exhibited across responses from multiple students to multiple questions; this property is especially important at large scale, since instructors will no longer need to manually specify all possible misconceptions that students might exhibit.