 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Word Embedding
Jun 01, 2020
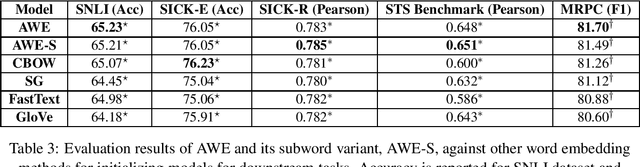
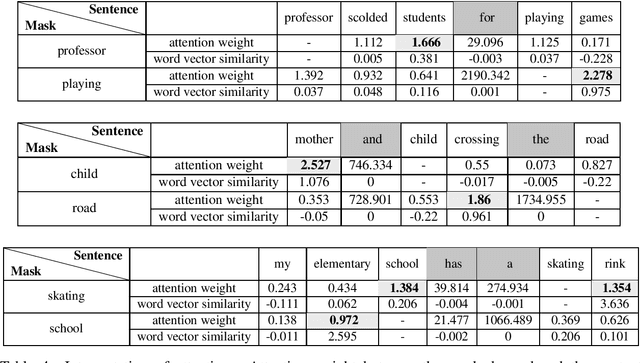
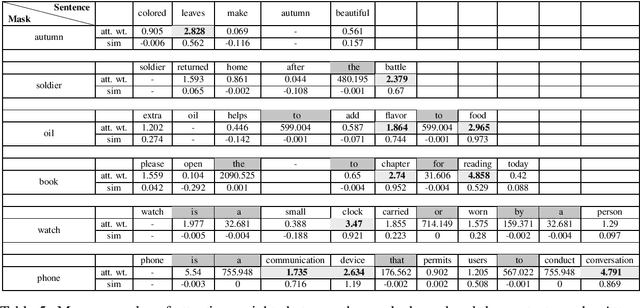
Word embedding models learn semantically rich vector representations of words and are widely used to initialize natural processing language (NLP) models. The popular continuous bag-of-words (CBOW) model of word2vec learns a vector embedding by masking a given word in a sentence and then using the other words as a context to predict it. A limitation of CBOW is that it equally weights the context words when making a prediction, which is inefficient, since some words have higher predictive value than others. We tackle this inefficiency by introducing the Attention Word Embedding (AWE) model, which integrates the attention mechanism into the CBOW model. We also propose AWE-S, which incorporates subword information. We demonstrate that AWE and AWE-S outperform the state-of-the-art word embedding models both on a variety of word similarity datasets and when used for initialization of NLP models.
qDKT: Question-centric Deep Knowledge Tracing
May 25, 2020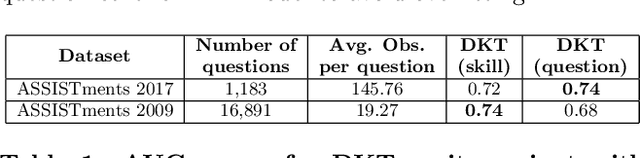
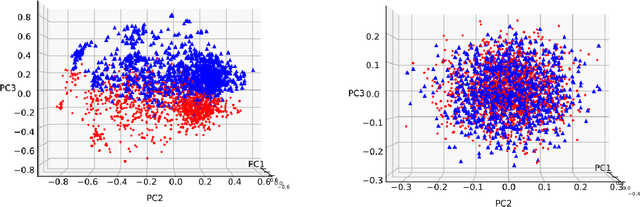

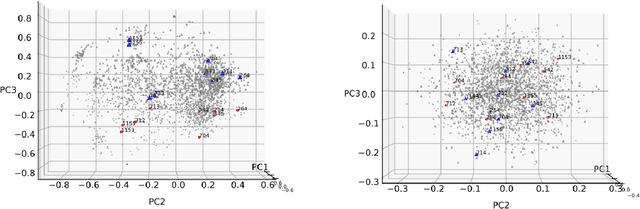
Knowledge tracing (KT) models, e.g., the deep knowledge tracing (DKT) model, track an individual learner's acquisition of skills over time by examining the learner's performance on questions related to those skills. A practical limitation in most existing KT models is that all questions nested under a particular skill are treated as equivalent observations of a learner's ability, which is an inaccurate assumption in real-world educational scenarios. To overcome this limitation we introduce qDKT, a variant of DKT that models every learner's success probability on individual questions over time. First, qDKT incorporates graph Laplacian regularization to smooth predictions under each skill, which is particularly useful when the number of questions in the dataset is big. Second, qDKT uses an initialization scheme inspired by the fastText algorithm, which has found success in a variety of language modeling tasks. Our experiments on several real-world datasets show that qDKT achieves state-of-art performance on predicting learner outcomes. Because of this, qDKT can serve as a simple, yet tough-to-beat, baseline for new question-centric KT models.
Mathematical Language Processing: Automatic Grading and Feedback for Open Response Mathematical Questions
Jan 18, 2015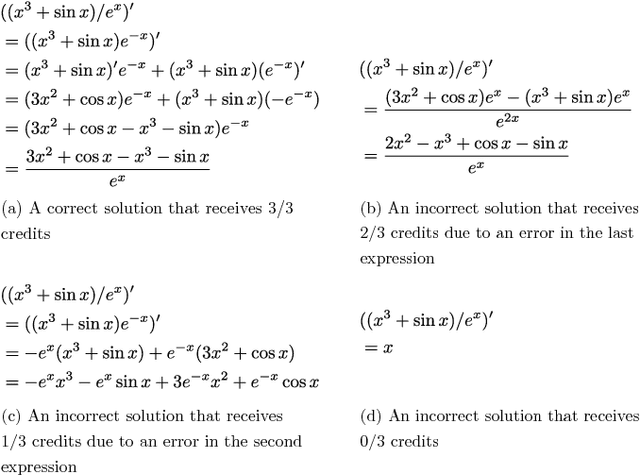

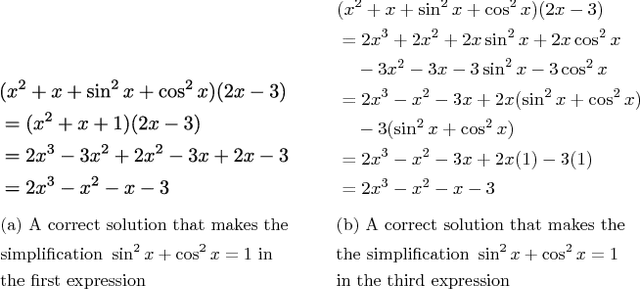
While computer and communication technologies have provided effective means to scale up many aspects of education, the submission and grading of assessments such as homework assignments and tests remains a weak link. In this paper, we study the problem of automatically grading the kinds of open response mathematical questions that figure prominently in STEM (science, technology, engineering, and mathematics) courses. Our data-driven framework for mathematical language processing (MLP) leverages solution data from a large number of learners to evaluate the correctness of their solutions, assign partial-credit scores, and provide feedback to each learner on the likely locations of any errors. MLP takes inspiration from the success of natural language processing for text data and comprises three main steps. First, we convert each solution to an open response mathematical question into a series of numerical features. Second, we cluster the features from several solutions to uncover the structures of correct, partially correct, and incorrect solutions. We develop two different clustering approaches, one that leverages generic clustering algorithms and one based on Bayesian nonparametrics. Third, we automatically grade the remaining (potentially large number of) solutions based on their assigned cluster and one instructor-provided grade per cluster. As a bonus, we can track the cluster assignment of each step of a multistep solution and determine when it departs from a cluster of correct solutions, which enables us to indicate the likely locations of errors to learners. We test and validate MLP on real-world MOOC data to demonstrate how it can substantially reduce the human effort required in large-scale educational platforms.
SPRITE: A Response Model For Multiple Choice Testing
Jan 12, 2015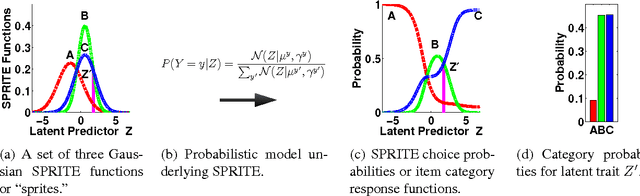
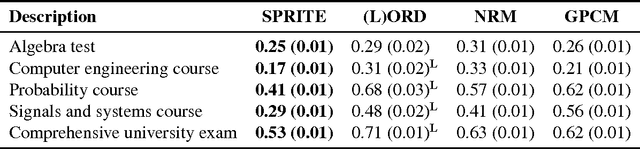
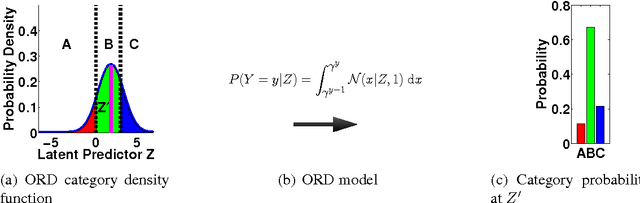
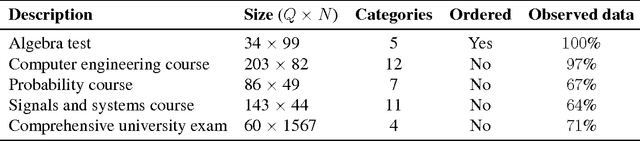
Item response theory (IRT) models for categorical response data are widely used in the analysis of educational data, computerized adaptive testing, and psychological surveys. However, most IRT models rely on both the assumption that categories are strictly ordered and the assumption that this ordering is known a priori. These assumptions are impractical in many real-world scenarios, such as multiple-choice exams where the levels of incorrectness for the distractor categories are often unknown. While a number of results exist on IRT models for unordered categorical data, they tend to have restrictive modeling assumptions that lead to poor data fitting performance in practice. Furthermore, existing unordered categorical models have parameters that are difficult to interpret. In this work, we propose a novel methodology for unordered categorical IRT that we call SPRITE (short for stochastic polytomous response item model) that: (i) analyzes both ordered and unordered categories, (ii) offers interpretable outputs, and (iii) provides improved data fitting compared to existing models. We compare SPRITE to existing item response models and demonstrate its efficacy on both synthetic and real-world educational datasets.
Tag-Aware Ordinal Sparse Factor Analysis for Learning and Content Analytics
Dec 18, 2014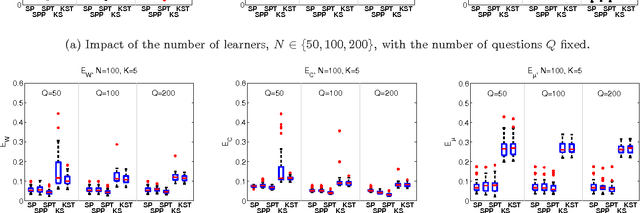
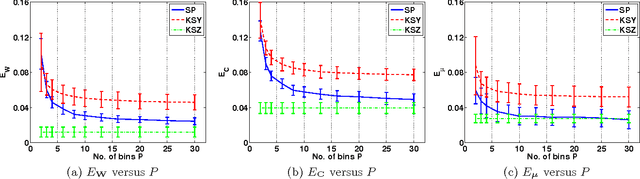
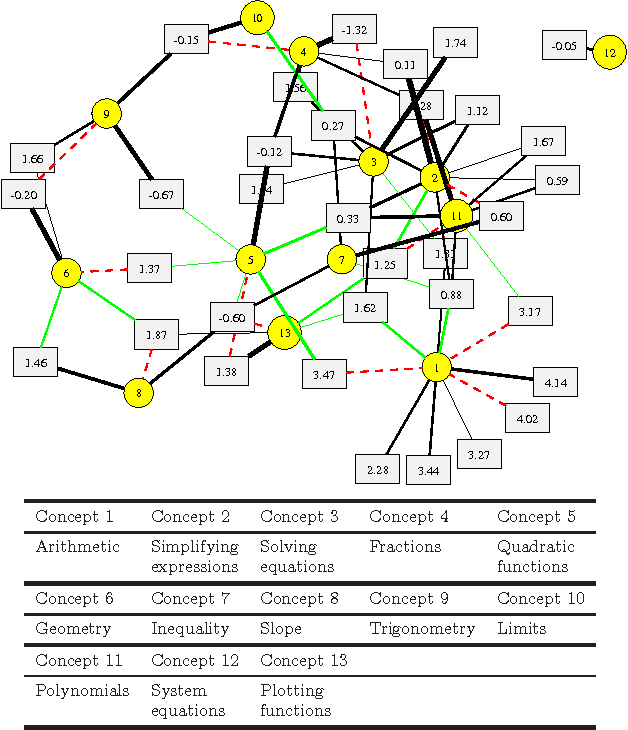
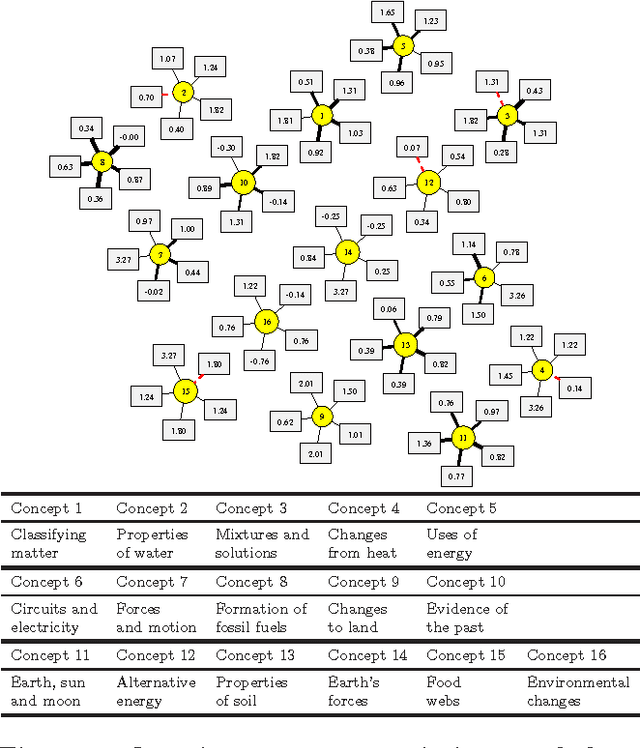
Machine learning offers novel ways and means to design personalized learning systems wherein each student's educational experience is customized in real time depending on their background, learning goals, and performance to date. SPARse Factor Analysis (SPARFA) is a novel framework for machine learning-based learning analytics, which estimates a learner's knowledge of the concepts underlying a domain, and content analytics, which estimates the relationships among a collection of questions and those concepts. SPARFA jointly learns the associations among the questions and the concepts, learner concept knowledge profiles, and the underlying question difficulties, solely based on the correct/incorrect graded responses of a population of learners to a collection of questions. In this paper, we extend the SPARFA framework significantly to enable: (i) the analysis of graded responses on an ordinal scale (partial credit) rather than a binary scale (correct/incorrect); (ii) the exploitation of tags/labels for questions that partially describe the question{concept associations. The resulting Ordinal SPARFA-Tag framework greatly enhances the interpretability of the estimated concepts. We demonstrate using real educational data that Ordinal SPARFA-Tag outperforms both SPARFA and existing collaborative filtering techniques in predicting missing learner responses.
Sparse Factor Analysis for Learning and Content Analytics
Jul 19, 2013We develop a new model and algorithms for machine learning-based learning analytics, which estimate a learner's knowledge of the concepts underlying a domain, and content analytics, which estimate the relationships among a collection of questions and those concepts. Our model represents the probability that a learner provides the correct response to a question in terms of three factors: their understanding of a set of underlying concepts, the concepts involved in each question, and each question's intrinsic difficulty. We estimate these factors given the graded responses to a collection of questions. The underlying estimation problem is ill-posed in general, especially when only a subset of the questions are answered. The key observation that enables a well-posed solution is the fact that typical educational domains of interest involve only a small number of key concepts. Leveraging this observation, we develop both a bi-convex maximum-likelihood and a Bayesian solution to the resulting SPARse Factor Analysis (SPARFA) problem. We also incorporate user-defined tags on questions to facilitate the interpretability of the estimated factors. Experiments with synthetic and real-world data demonstrate the efficacy of our approach. Finally, we make a connection between SPARFA and noisy, binary-valued (1-bit) dictionary learning that is of independent interest.
Joint Topic Modeling and Factor Analysis of Textual Information and Graded Response Data
May 10, 2013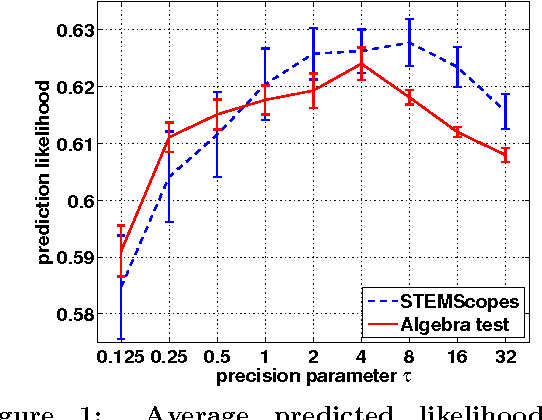
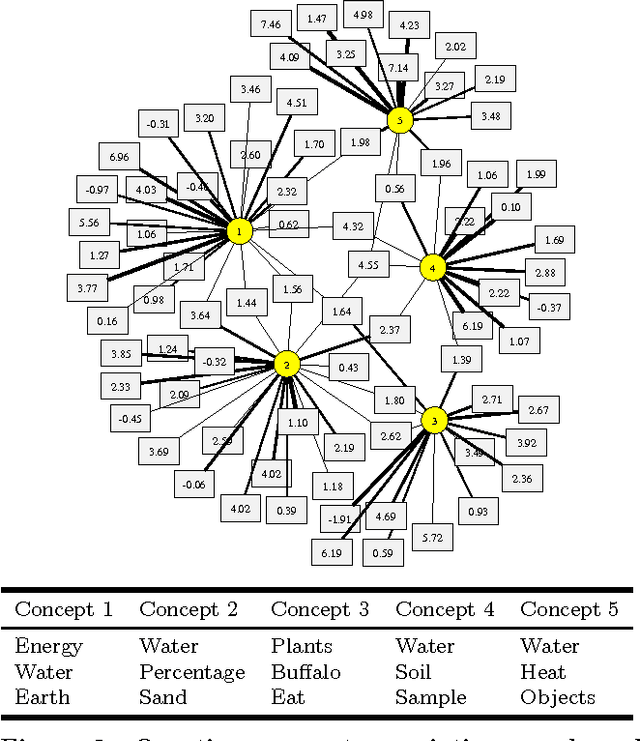
Modern machine learning methods are critical to the development of large-scale personalized learning systems that cater directly to the needs of individual learners. The recently developed SPARse Factor Analysis (SPARFA) framework provides a new statistical model and algorithms for machine learning-based learning analytics, which estimate a learner's knowledge of the latent concepts underlying a domain, and content analytics, which estimate the relationships among a collection of questions and the latent concepts. SPARFA estimates these quantities given only the binary-valued graded responses to a collection of questions. In order to better interpret the estimated latent concepts, SPARFA relies on a post-processing step that utilizes user-defined tags (e.g., topics or keywords) available for each question. In this paper, we relax the need for user-defined tags by extending SPARFA to jointly process both graded learner responses and the text of each question and its associated answer(s) or other feedback. Our purely data-driven approach (i) enhances the interpretability of the estimated latent concepts without the need of explicitly generating a set of tags or performing a post-processing step, (ii) improves the prediction performance of SPARFA, and (iii) scales to large test/assessments where human annotation would prove burdensome. We demonstrate the efficacy of the proposed approach on two real educational datasets.