 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical Language Processing: Automatic Grading and Feedback for Open Response Mathematical Questions
Jan 18, 2015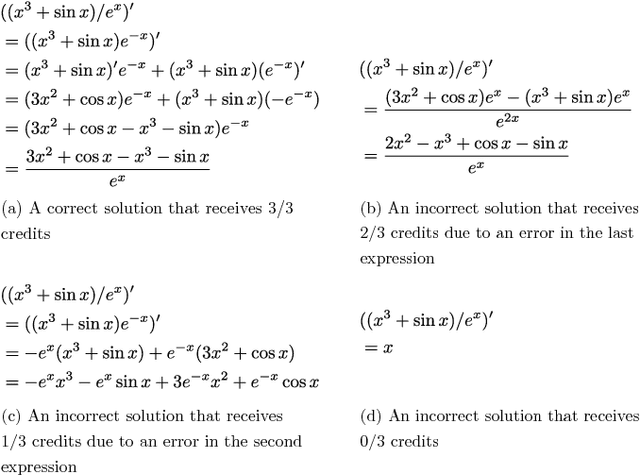

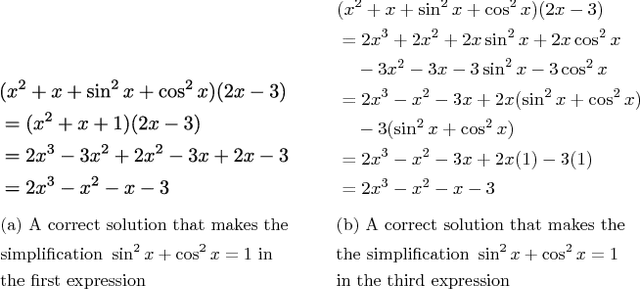
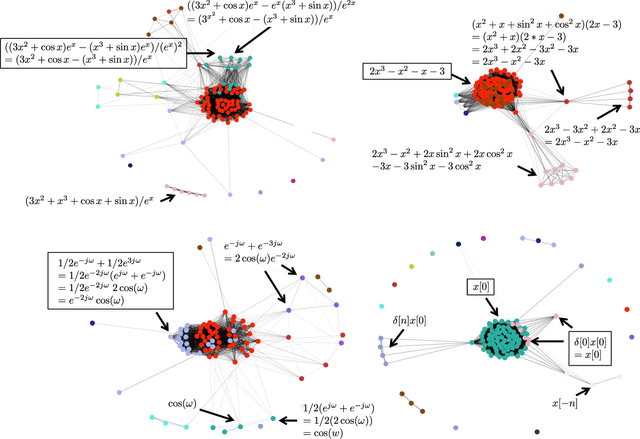
While computer and communication technologies have provided effective means to scale up many aspects of education, the submission and grading of assessments such as homework assignments and tests remains a weak link. In this paper, we study the problem of automatically grading the kinds of open response mathematical questions that figure prominently in STEM (science, technology, engineering, and mathematics) courses. Our data-driven framework for mathematical language processing (MLP) leverages solution data from a large number of learners to evaluate the correctness of their solutions, assign partial-credit scores, and provide feedback to each learner on the likely locations of any errors. MLP takes inspiration from the success of natural language processing for text data and comprises three main steps. First, we convert each solution to an open response mathematical question into a series of numerical features. Second, we cluster the features from several solutions to uncover the structures of correct, partially correct, and incorrect solutions. We develop two different clustering approaches, one that leverages generic clustering algorithms and one based on Bayesian nonparametrics. Third, we automatically grade the remaining (potentially large number of) solutions based on their assigned cluster and one instructor-provided grade per cluster. As a bonus, we can track the cluster assignment of each step of a multistep solution and determine when it departs from a cluster of correct solutions, which enables us to indicate the likely locations of errors to learners. We test and validate MLP on real-world MOOC data to demonstrate how it can substantially reduce the human effort required in large-scale educational platforms.
Active Learning for Undirected Graphical Model Selection
Apr 13, 2014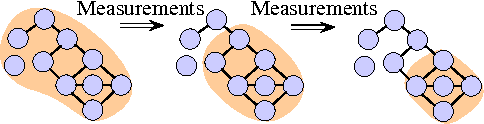


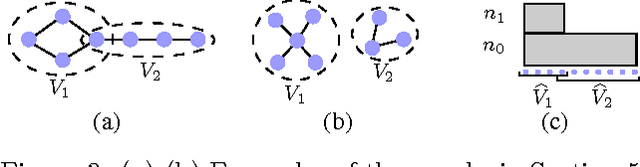
This paper studies graphical model selection, i.e., the problem of estimating a graph of statistical relationships among a collection of random variables. Conventional graphical model selection algorithms are passive, i.e., they require all the measurements to have been collected before processing begins. We propose an active learning algorithm that uses junction tree representations to adapt future measurements based on the information gathered from prior measurements. We prove that, under certain conditions, our active learning algorithm requires fewer scalar measurements than any passive algorithm to reliably estimate a graph. A range of numerical results validate our theory and demonstrates the benefits of active learning.
* AISTATS 2014
Path Thresholding: Asymptotically Tuning-Free High-Dimensional Sparse Regression
Feb 23, 2014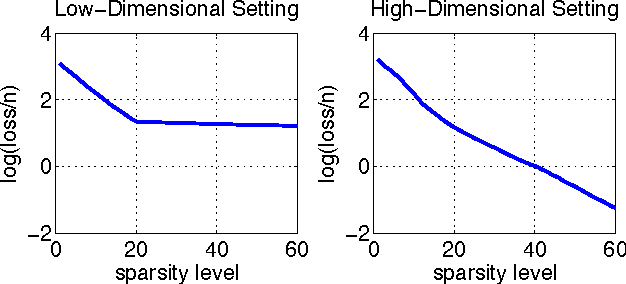
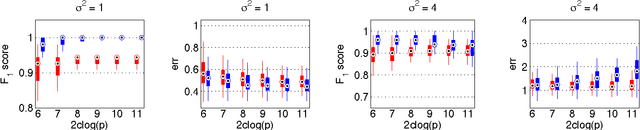
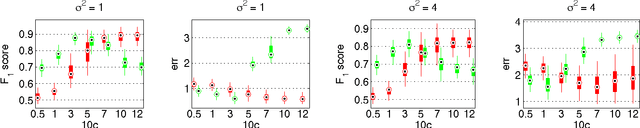
In this paper, we address the challenging problem of selecting tuning parameters for high-dimensional sparse regression. We propose a simple and computationally efficient method, called path thresholding (PaTh), that transforms any tuning parameter-dependent sparse regression algorithm into an asymptotically tuning-free sparse regression algorithm. More specifically, we prove that, as the problem size becomes large (in the number of variables and in the number of observations), PaTh performs accurate sparse regression, under appropriate conditions, without specifying a tuning parameter. In finite-dimensional settings, we demonstrate that PaTh can alleviate the computational burden of model selection algorithms by significantly reducing the search space of tuning parameters.
* AISTATS 2014
Swapping Variables for High-Dimensional Sparse Regression with Correlated Measurements
Feb 22, 2014

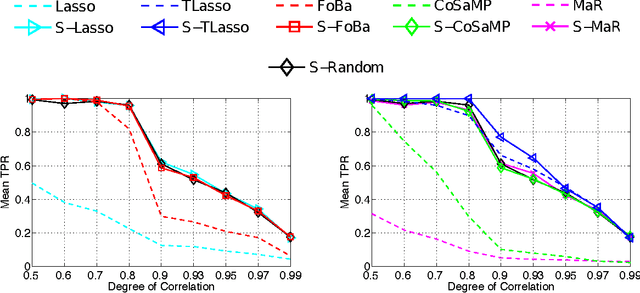
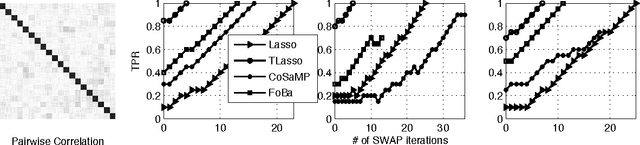
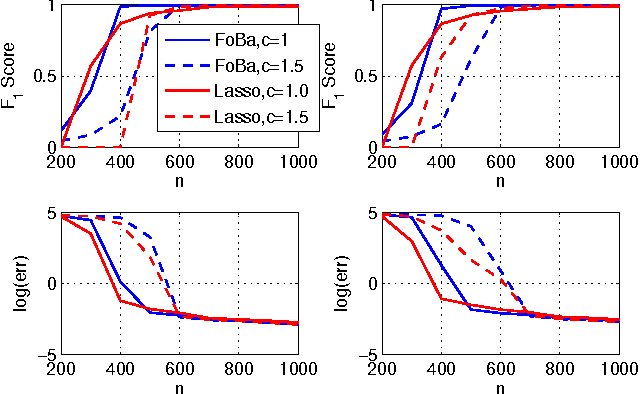
We consider the high-dimensional sparse linear regression problem of accurately estimating a sparse vector using a small number of linear measurements that are contaminated by noise. It is well known that the standard cadre of computationally tractable sparse regression algorithms---such as the Lasso, Orthogonal Matching Pursuit (OMP), and their extensions---perform poorly when the measurement matrix contains highly correlated columns. To address this shortcoming, we develop a simple greedy algorithm, called SWAP, that iteratively swaps variables until convergence. SWAP is surprisingly effective in handling measurement matrices with high correlations. In fact, we prove that SWAP outputs the true support, the locations of the non-zero entries in the sparse vector, under a relatively mild condition on the measurement matrix. Furthermore, we show that SWAP can be used to boost the performance of any sparse regression algorithm. We empirically demonstrate the advantages of SWAP by comparing it with several state-of-the-art sparse regression algorithms.
A Junction Tree Framework for Undirected Graphical Model Selection
Dec 02, 2013

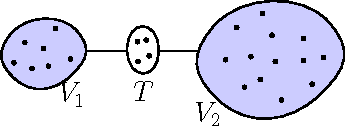
An undirected graphical model is a joint probability distribution defined on an undirected graph G*, where the vertices in the graph index a collection of random variables and the edges encode conditional independence relationships among random variables. The undirected graphical model selection (UGMS) problem is to estimate the graph G* given observations drawn from the undirected graphical model. This paper proposes a framework for decomposing the UGMS problem into multiple subproblems over clusters and subsets of the separators in a junction tree. The junction tree is constructed using a graph that contains a superset of the edges in G*. We highlight three main properties of using junction trees for UGMS. First, different regularization parameters or different UGMS algorithms can be used to learn different parts of the graph. This is possible since the subproblems we identify can be solved independently of each other. Second, under certain conditions, a junction tree based UGMS algorithm can produce consistent results with fewer observations than the usual requirements of existing algorithms. Third, both our theoretical and experimental results show that the junction tree framework does a significantly better job at finding the weakest edges in a graph than existing methods. This property is a consequence of both the first and second properties. Finally, we note that our framework is independent of the choice of the UGMS algorithm and can be used as a wrapper around standard UGMS algorithms for more accurate graph estimation.
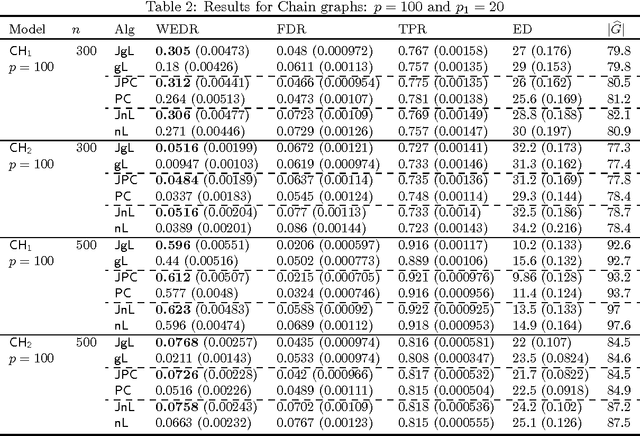
High-Dimensional Screening Using Multiple Grouping of Variables
Dec 02, 2013


Screening is the problem of finding a superset of the set of non-zero entries in an unknown p-dimensional vector \beta* given n noisy observations. Naturally, we want this superset to be as small as possible. We propose a novel framework for screening, which we refer to as Multiple Grouping (MuG), that groups variables, performs variable selection over the groups, and repeats this process multiple number of times to estimate a sequence of sets that contains the non-zero entries in \beta*. Screening is done by taking an intersection of all these estimated sets. The MuG framework can be used in conjunction with any group based variable selection algorithm. In the high-dimensional setting, where p >> n, we show that when MuG is used with the group Lasso estimator, screening can be consistently performed without using any tuning parameter. Our numerical simulations clearly show the merits of using the MuG framework in practice.
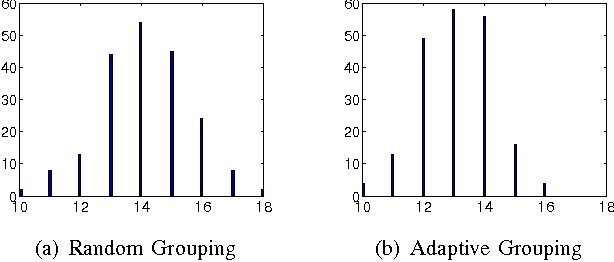
Finding Non-overlapping Clusters for Generalized Inference Over Graphical Models
Mar 18, 2012
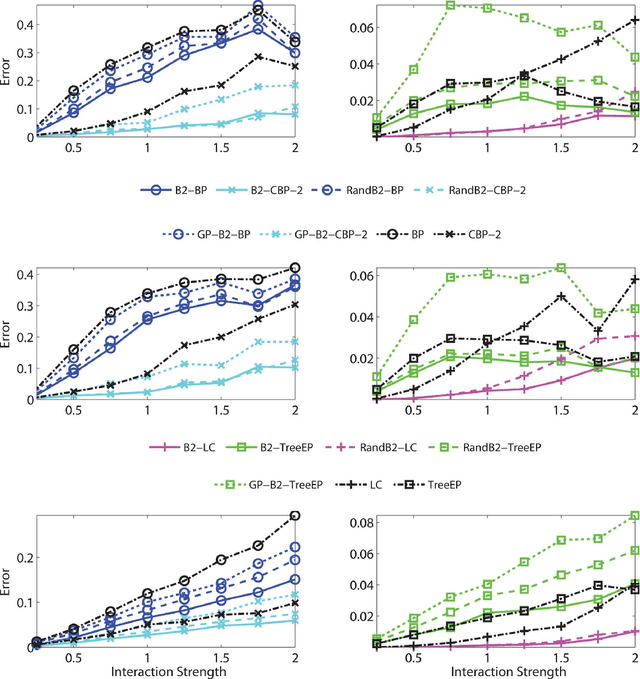
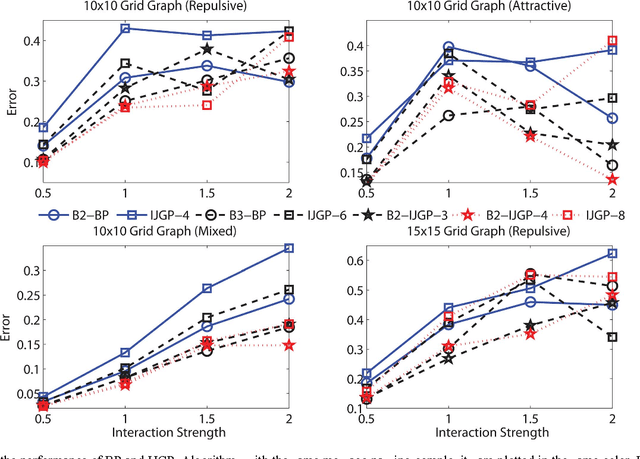
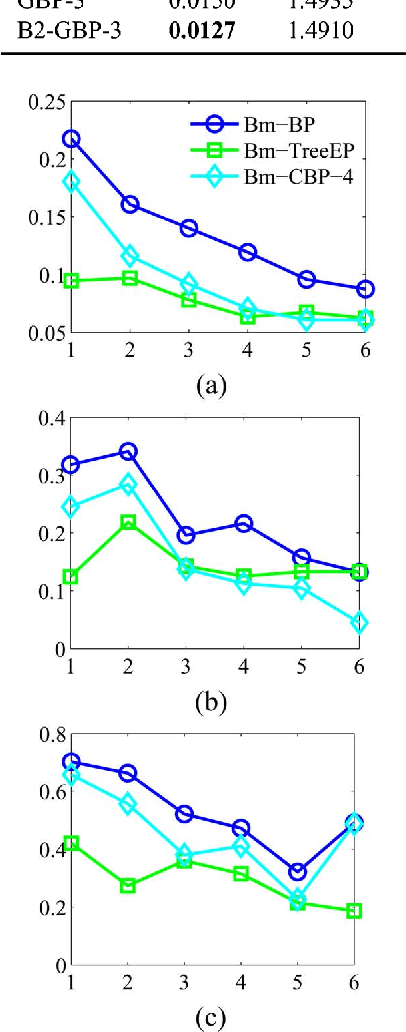
Graphical models use graphs to compactly capture stochastic dependencies amongst a collection of random variables. Inference over graphical models corresponds to finding marginal probability distributions given joint probability distributions. In general, this is computationally intractable, which has led to a quest for finding efficient approximate inference algorithms. We propose a framework for generalized inference over graphical models that can be used as a wrapper for improving the estimates of approximate inference algorithms. Instead of applying an inference algorithm to the original graph, we apply the inference algorithm to a block-graph, defined as a graph in which the nodes are non-overlapping clusters of nodes from the original graph. This results in marginal estimates of a cluster of nodes, which we further marginalize to get the marginal estimates of each node. Our proposed block-graph construction algorithm is simple, efficient, and motivated by the observation that approximate inference is more accurate on graphs with longer cycles. We present extensive numerical simulations that illustrate our block-graph framework with a variety of inference algorithms (e.g., those in the libDAI software package). These simulations show the improvements provided by our framework.
* Extended the previous version to include extensive numerical simulations. See http://www.ima.umn.edu/~dvats/GeneralizedInference.html for code and data
Graphical Models as Block-Tree Graphs
Nov 13, 2010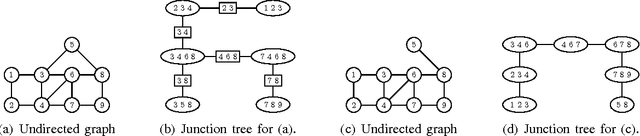


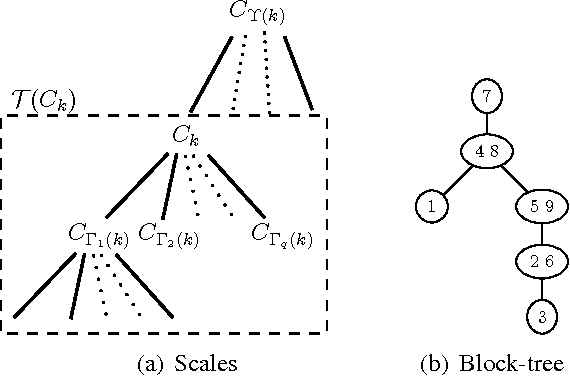
We introduce block-tree graphs as a framework for deriving efficient algorithms on graphical models. We define block-tree graphs as a tree-structured graph where each node is a cluster of nodes such that the clusters in the graph are disjoint. This differs from junction-trees, where two clusters connected by an edge always have at least one common node. When compared to junction-trees, we show that constructing block-tree graphs is faster, and finding optimal block-tree graphs has a much smaller search space. Applying our block-tree graph framework to graphical models, we show that, for some graphs, e.g., grid graphs, using block-tree graphs for inference is computationally more efficient than using junction-trees. For graphical models with boundary conditions, the block-tree graph framework transforms the boundary valued problem into an initial value problem. For Gaussian graphical models, the block-tree graph framework leads to a linear state-space representation. Since exact inference in graphical models can be computationally intractable, we propose to use spanning block-trees to derive approximate inference algorithms. Experimental results show the improved performance in using spanning block-trees versus using spanning trees for approximate estimation over Gaussian graphical models.