 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical Language Processing: Automatic Grading and Feedback for Open Response Mathematical Questions
Paper and Code
Jan 18, 2015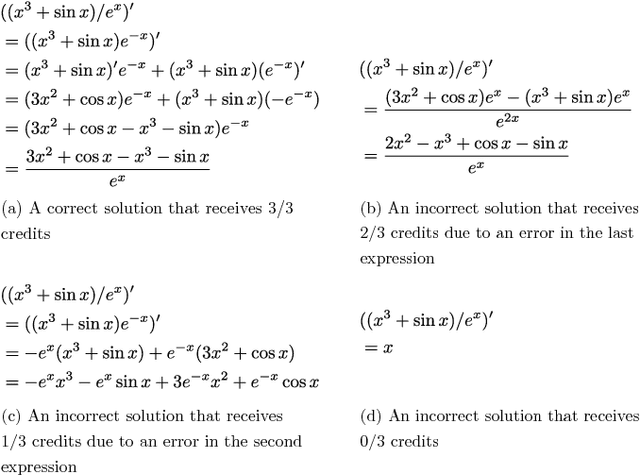

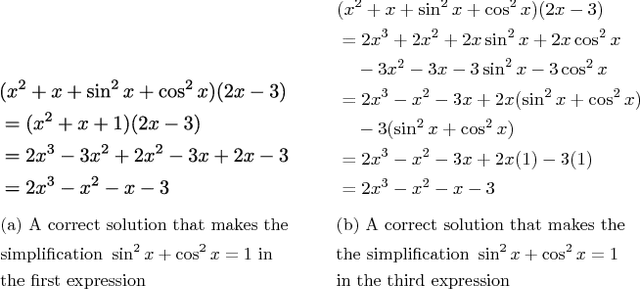
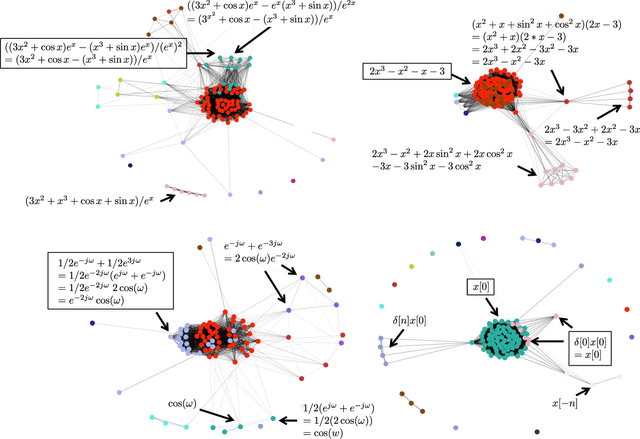
While computer and communication technologies have provided effective means to scale up many aspects of education, the submission and grading of assessments such as homework assignments and tests remains a weak link. In this paper, we study the problem of automatically grading the kinds of open response mathematical questions that figure prominently in STEM (science, technology, engineering, and mathematics) courses. Our data-driven framework for mathematical language processing (MLP) leverages solution data from a large number of learners to evaluate the correctness of their solutions, assign partial-credit scores, and provide feedback to each learner on the likely locations of any errors. MLP takes inspiration from the success of natural language processing for text data and comprises three main steps. First, we convert each solution to an open response mathematical question into a series of numerical features. Second, we cluster the features from several solutions to uncover the structures of correct, partially correct, and incorrect solutions. We develop two different clustering approaches, one that leverages generic clustering algorithms and one based on Bayesian nonparametrics. Third, we automatically grade the remaining (potentially large number of) solutions based on their assigned cluster and one instructor-provided grade per cluster. As a bonus, we can track the cluster assignment of each step of a multistep solution and determine when it departs from a cluster of correct solutions, which enables us to indicate the likely locations of errors to learners. We test and validate MLP on real-world MOOC data to demonstrate how it can substantially reduce the human effort required in large-scale educational platforms.