 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Powers of Precision: Structure-Informed Detection in Complex Systems -- From Customer Churn to Seizure Onset
Jan 29, 2026Emergent phenomena -- onset of epileptic seizures, sudden customer churn, or pandemic outbreaks -- often arise from hidden causal interactions in complex systems. We propose a machine learning method for their early detection that addresses a core challenge: unveiling and harnessing a system's latent causal structure despite the data-generating process being unknown and partially observed. The method learns an optimal feature representation from a one-parameter family of estimators -- powers of the empirical covariance or precision matrix -- offering a principled way to tune in to the underlying structure driving the emergence of critical events. A supervised learning module then classifies the learned representation. We prove structural consistency of the family and demonstrate the empirical soundness of our approach on seizure detection and churn prediction, attaining competitive results in both. Beyond prediction, and toward explainability, we ascertain that the optimal covariance power exhibits evidence of good identifiability while capturing structural signatures, thus reconciling predictive performance with interpretable statistical structure.
GLUE: Gradient-free Learning to Unify Experts
Dec 27, 2025In many deployed systems (multilingual ASR, cross-hospital imaging, region-specific perception), multiple pretrained specialist models coexist. Yet, new target domains often require domain expansion: a generalized model that performs well beyond any single specialist's domain. Given such a new target domain, prior works seek a single strong initialization prior for the model parameters by first blending expert models to initialize a target model. However, heuristic blending -- using coefficients based on data size or proxy metrics -- often yields lower target-domain test accuracy, and learning the coefficients on the target loss typically requires computationally-expensive full backpropagation through the network. We propose GLUE, Gradient-free Learning To Unify Experts, which initializes the target model as a convex combination of fixed experts, learning the mixture coefficients of this combination via a gradient-free two-point (SPSA) update that requires only two forward passes per step. Across experiments on three datasets and three network architectures, GLUE produces a single prior that can be fine-tuned effectively to outperform baselines. GLUE improves test accuracy by up to 8.5% over data-size weighting and by up to 9.1% over proxy-metric selection. GLUE either outperforms backpropagation-based full-gradient mixing or matches its performance within 1.4%.
Inferring the Graph Structure of Images for Graph Neural Networks
Sep 04, 2025Image datasets such as MNIST are a key benchmark for testing Graph Neural Network (GNN) architectures. The images are traditionally represented as a grid graph with each node representing a pixel and edges connecting neighboring pixels (vertically and horizontally). The graph signal is the values (intensities) of each pixel in the image. The graphs are commonly used as input to graph neural networks (e.g., Graph Convolutional Neural Networks (Graph CNNs) [1, 2], Graph Attention Networks (GAT) [3], GatedGCN [4]) to classify the images. In this work, we improve the accuracy of downstream graph neural network tasks by finding alternative graphs to the grid graph and superpixel methods to represent the dataset images, following the approach in [5, 6]. We find row correlation, column correlation, and product graphs for each image in MNIST and Fashion-MNIST using correlations between the pixel values building on the method in [5, 6]. Experiments show that using these different graph representations and features as input into downstream GNN models improves the accuracy over using the traditional grid graph and superpixel methods in the literature.
GradNetOT: Learning Optimal Transport Maps with GradNets
Jul 17, 2025Monotone gradient functions play a central role in solving the Monge formulation of the optimal transport problem, which arises in modern applications ranging from fluid dynamics to robot swarm control. When the transport cost is the squared Euclidean distance, Brenier's theorem guarantees that the unique optimal map is the gradient of a convex function, namely a monotone gradient map, and it satisfies a Monge-Amp\`ere equation. In [arXiv:2301.10862] [arXiv:2404.07361], we proposed Monotone Gradient Networks (mGradNets), neural networks that directly parameterize the space of monotone gradient maps. In this work, we leverage mGradNets to directly learn the optimal transport mapping by minimizing a training loss function defined using the Monge-Amp\`ere equation. We empirically show that the structural bias of mGradNets facilitates the learning of optimal transport maps and employ our method for a robot swarm control problem.
BRIDGES: Bridging Graph Modality and Large Language Models within EDA Tasks
Apr 07, 2025While many EDA tasks already involve graph-based data, existing LLMs in EDA primarily either represent graphs as sequential text, or simply ignore graph-structured data that might be beneficial like dataflow graphs of RTL code. Recent studies have found that LLM performance suffers when graphs are represented as sequential text, and using additional graph information significantly boosts performance. To address these challenges, we introduce BRIDGES, a framework designed to incorporate graph modality into LLMs for EDA tasks. BRIDGES integrates an automated data generation workflow, a solution that combines graph modality with LLM, and a comprehensive evaluation suite. First, we establish an LLM-driven workflow to generate RTL and netlist-level data, converting them into dataflow and netlist graphs with function descriptions. This workflow yields a large-scale dataset comprising over 500,000 graph instances and more than 1.5 billion tokens. Second, we propose a lightweight cross-modal projector that encodes graph representations into text-compatible prompts, enabling LLMs to effectively utilize graph data without architectural modifications. Experimental results demonstrate 2x to 10x improvements across multiple tasks compared to text-only baselines, including accuracy in design retrieval, type prediction and perplexity in function description, with negligible computational overhead (<1% model weights increase and <30% additional runtime overhead). Even without additional LLM finetuning, our results outperform text-only by a large margin. We plan to release BRIDGES, including the dataset, models, and training flow.
ReLU Networks as Random Functions: Their Distribution in Probability Space
Mar 28, 2025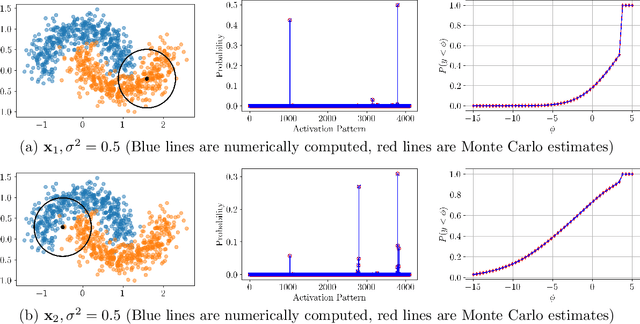

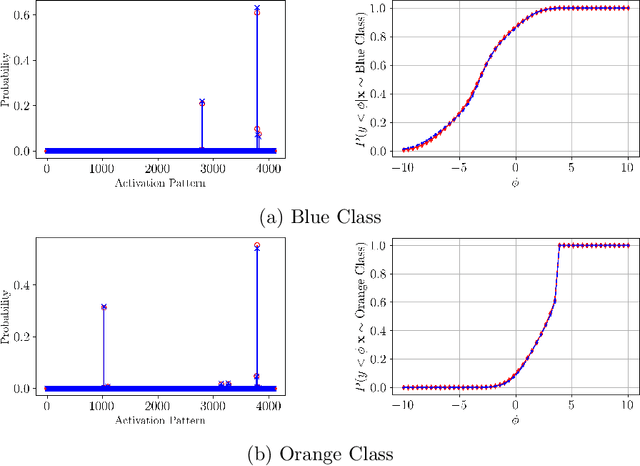

This paper presents a novel framework for understanding trained ReLU networks as random, affine functions, where the randomness is induced by the distribution over the inputs. By characterizing the probability distribution of the network's activation patterns, we derive the discrete probability distribution over the affine functions realizable by the network. We extend this analysis to describe the probability distribution of the network's outputs. Our approach provides explicit, numerically tractable expressions for these distributions in terms of Gaussian orthant probabilities. Additionally, we develop approximation techniques to identify the support of affine functions a trained ReLU network can realize for a given distribution of inputs. Our work provides a framework for understanding the behavior and performance of ReLU networks corresponding to stochastic inputs, paving the way for more interpretable and reliable models.
FedBaF: Federated Learning Aggregation Biased by a Foundation Model
Oct 24, 2024Foundation models are now a major focus of leading technology organizations due to their ability to generalize across diverse tasks. Existing approaches for adapting foundation models to new applications often rely on Federated Learning (FL) and disclose the foundation model weights to clients when using it to initialize the global model. While these methods ensure client data privacy, they compromise model and information security. In this paper, we introduce Federated Learning Aggregation Biased by a Foundation Model (FedBaF), a novel method for dynamically integrating pre-trained foundation model weights during the FL aggregation phase. Unlike conventional methods, FedBaF preserves the confidentiality of the foundation model while still leveraging its power to train more accurate models, especially in non-IID and adversarial scenarios. Our comprehensive experiments use Pre-ResNet and foundation models like Vision Transformer to demonstrate that FedBaF not only matches, but often surpasses the test accuracy of traditional weight initialization methods by up to 11.4\% in IID and up to 15.8\% in non-IID settings. Additionally, FedBaF applied to a Transformer-based language model significantly reduced perplexity by up to 39.2\%.
Gradient Networks
Apr 10, 2024



Directly parameterizing and learning gradients of functions has widespread significance, with specific applications in optimization, generative modeling, and optimal transport. This paper introduces gradient networks (GradNets): novel neural network architectures that parameterize gradients of various function classes. GradNets exhibit specialized architectural constraints that ensure correspondence to gradient functions. We provide a comprehensive GradNet design framework that includes methods for transforming GradNets into monotone gradient networks (mGradNets), which are guaranteed to represent gradients of convex functions. We establish the approximation capabilities of the proposed GradNet and mGradNet. Our results demonstrate that these networks universally approximate the gradients of (convex) functions. Furthermore, these networks can be customized to correspond to specific spaces of (monotone) gradient functions, including gradients of transformed sums of (convex) ridge functions. Our analysis leads to two distinct GradNet architectures, GradNet-C and GradNet-M, and we describe the corresponding monotone versions, mGradNet-C and mGradNet-M. Our empirical results show that these architectures offer efficient parameterizations and outperform popular methods in gradient field learning tasks.
An Analytic Solution to Covariance Propagation in Neural Networks
Mar 24, 2024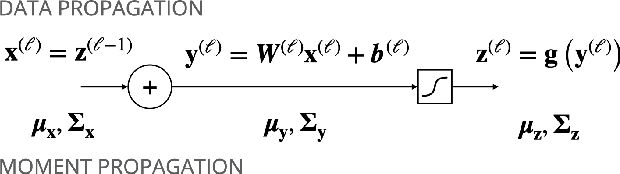

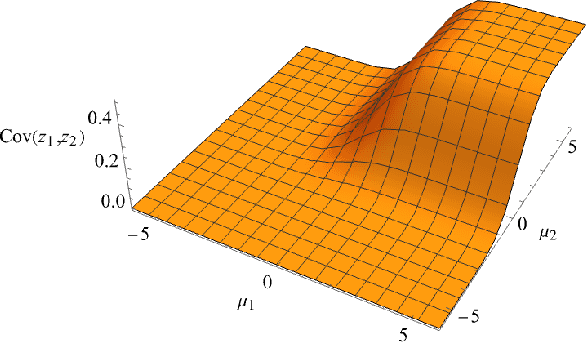
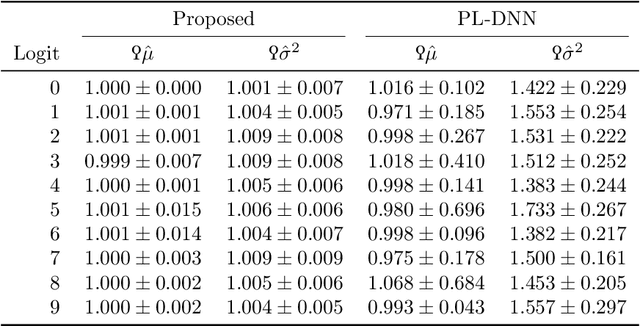
Uncertainty quantification of neural networks is critical to measuring the reliability and robustness of deep learning systems. However, this often involves costly or inaccurate sampling methods and approximations. This paper presents a sample-free moment propagation technique that propagates mean vectors and covariance matrices across a network to accurately characterize the input-output distributions of neural networks. A key enabler of our technique is an analytic solution for the covariance of random variables passed through nonlinear activation functions, such as Heaviside, ReLU, and GELU. The wide applicability and merits of the proposed technique are shown in experiments analyzing the input-output distributions of trained neural networks and training Bayesian neural networks.
Peer-to-Peer Learning + Consensus with Non-IID Data
Dec 21, 2023



Peer-to-peer deep learning algorithms are enabling distributed edge devices to collaboratively train deep neural networks without exchanging raw training data or relying on a central server. Peer-to-Peer Learning (P2PL) and other algorithms based on Distributed Local-Update Stochastic/mini-batch Gradient Descent (local DSGD) rely on interleaving epochs of training with distributed consensus steps. This process leads to model parameter drift/divergence amongst participating devices in both IID and non-IID settings. We observe that model drift results in significant oscillations in test performance evaluated after local training and consensus phases. We then identify factors that amplify performance oscillations and demonstrate that our novel approach, P2PL with Affinity, dampens test performance oscillations in non-IID settings without incurring any additional communication cost.