 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLUE: Gradient-free Learning to Unify Experts
Dec 27, 2025In many deployed systems (multilingual ASR, cross-hospital imaging, region-specific perception), multiple pretrained specialist models coexist. Yet, new target domains often require domain expansion: a generalized model that performs well beyond any single specialist's domain. Given such a new target domain, prior works seek a single strong initialization prior for the model parameters by first blending expert models to initialize a target model. However, heuristic blending -- using coefficients based on data size or proxy metrics -- often yields lower target-domain test accuracy, and learning the coefficients on the target loss typically requires computationally-expensive full backpropagation through the network. We propose GLUE, Gradient-free Learning To Unify Experts, which initializes the target model as a convex combination of fixed experts, learning the mixture coefficients of this combination via a gradient-free two-point (SPSA) update that requires only two forward passes per step. Across experiments on three datasets and three network architectures, GLUE produces a single prior that can be fine-tuned effectively to outperform baselines. GLUE improves test accuracy by up to 8.5% over data-size weighting and by up to 9.1% over proxy-metric selection. GLUE either outperforms backpropagation-based full-gradient mixing or matches its performance within 1.4%.
FedTLU: Federated Learning with Targeted Layer Updates
Dec 23, 2024Federated learning (FL) addresses privacy concerns in language modeling by enabling multiple clients to contribute to training language models. However, non-IID (identically and independently distributed) data across clients often limits FL's performance. This issue is especially challenging during model fine-tuning, as noise due to variations in clients' data distributions can harm model convergence near the optimum. This paper proposes a targeted layer update strategy for fine-tuning in FL. Instead of randomly updating layers of the language model, as often done in practice, we use a scoring mechanism to identify and update the most critical layers, avoiding excessively noisy or even poisoned updates by freezing the parameters in other layers. We show in extensive experiments that our method improves convergence and performance in non-IID settings, offering a more efficient approach to fine-tuning federated language models.
FedBaF: Federated Learning Aggregation Biased by a Foundation Model
Oct 24, 2024Foundation models are now a major focus of leading technology organizations due to their ability to generalize across diverse tasks. Existing approaches for adapting foundation models to new applications often rely on Federated Learning (FL) and disclose the foundation model weights to clients when using it to initialize the global model. While these methods ensure client data privacy, they compromise model and information security. In this paper, we introduce Federated Learning Aggregation Biased by a Foundation Model (FedBaF), a novel method for dynamically integrating pre-trained foundation model weights during the FL aggregation phase. Unlike conventional methods, FedBaF preserves the confidentiality of the foundation model while still leveraging its power to train more accurate models, especially in non-IID and adversarial scenarios. Our comprehensive experiments use Pre-ResNet and foundation models like Vision Transformer to demonstrate that FedBaF not only matches, but often surpasses the test accuracy of traditional weight initialization methods by up to 11.4\% in IID and up to 15.8\% in non-IID settings. Additionally, FedBaF applied to a Transformer-based language model significantly reduced perplexity by up to 39.2\%.
Federated Learning with Flexible Architectures
Jun 14, 2024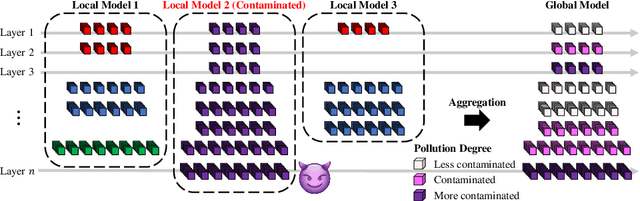
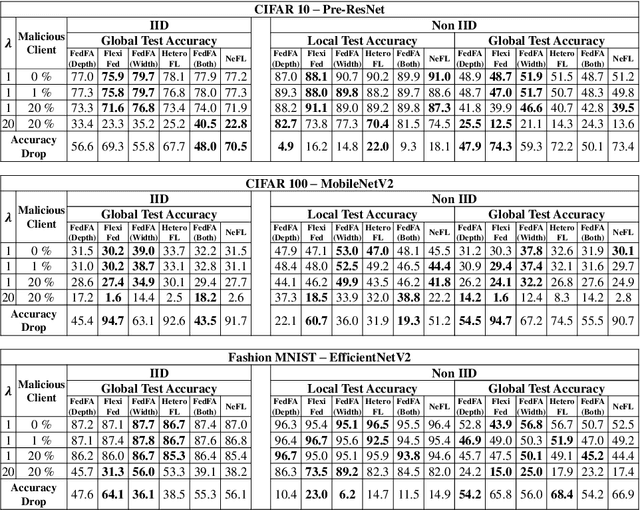
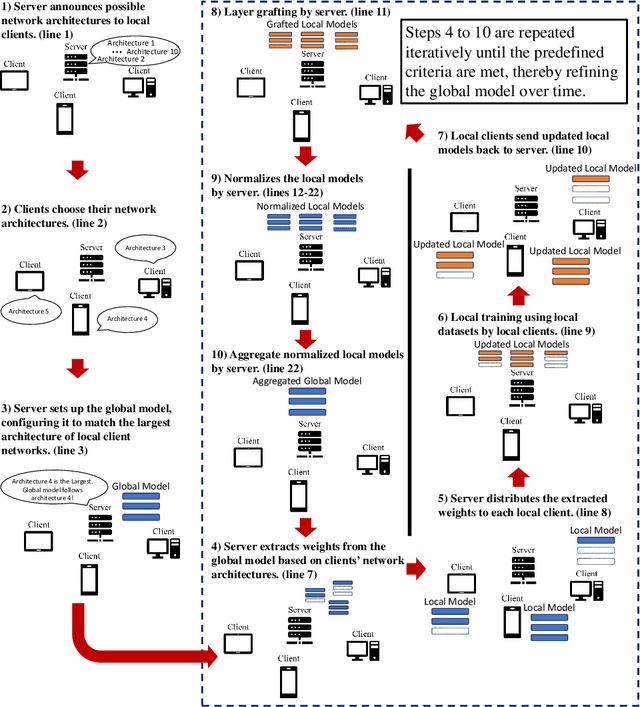

Traditional federated learning (FL) methods have limited support for clients with varying computational and communication abilities, leading to inefficiencies and potential inaccuracies in model training. This limitation hinders the widespread adoption of FL in diverse and resource-constrained environments, such as those with client devices ranging from powerful servers to mobile devices. To address this need, this paper introduces Federated Learning with Flexible Architectures (FedFA), an FL training algorithm that allows clients to train models of different widths and depths. Each client can select a network architecture suitable for its resources, with shallower and thinner networks requiring fewer computing resources for training. Unlike prior work in this area, FedFA incorporates the layer grafting technique to align clients' local architectures with the largest network architecture in the FL system during model aggregation. Layer grafting ensures that all client contributions are uniformly integrated into the global model, thereby minimizing the risk of any individual client's data skewing the model's parameters disproportionately and introducing security benefits. Moreover, FedFA introduces the scalable aggregation method to manage scale variations in weights among different network architectures. Experimentally, FedFA outperforms previous width and depth flexible aggregation strategies. Furthermore, FedFA demonstrates increased robustness against performance degradation in backdoor attack scenarios compared to earlier strategies.
Fair Concurrent Training of Multiple Models in Federated Learning
Apr 22, 2024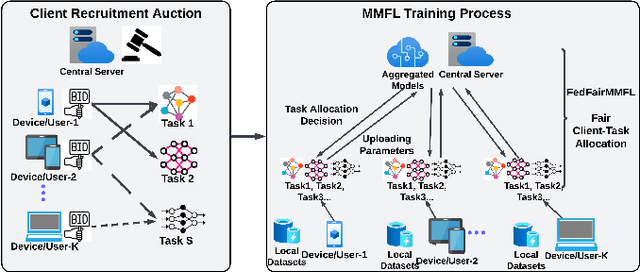
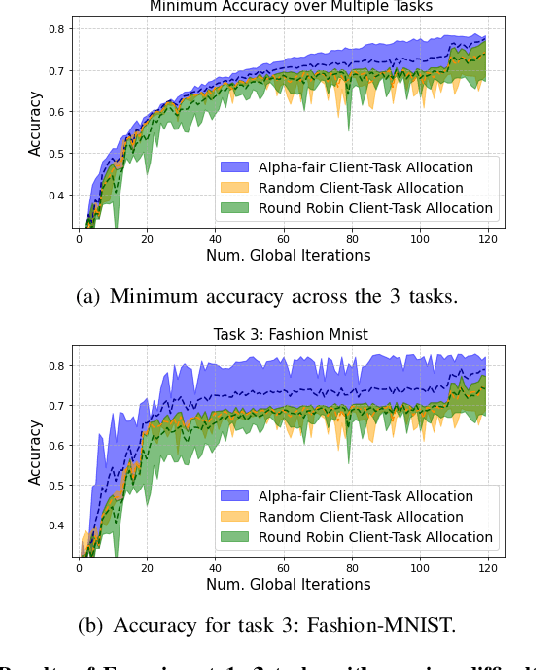
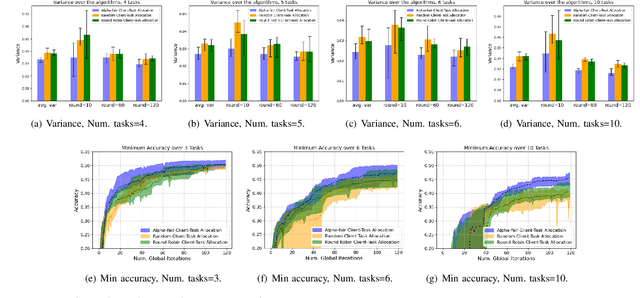
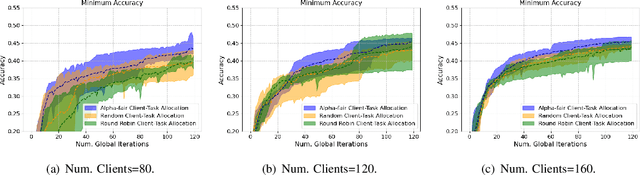
Federated learning (FL) enables collaborative learning across multiple clients. In most FL work, all clients train a single learning task. However, the recent proliferation of FL applications may increasingly require multiple FL tasks to be trained simultaneously, sharing clients' computing and communication resources, which we call Multiple-Model Federated Learning (MMFL). Current MMFL algorithms use naive average-based client-task allocation schemes that can lead to unfair performance when FL tasks have heterogeneous difficulty levels, e.g., tasks with larger models may need more rounds and data to train. Just as naively allocating resources to generic computing jobs with heterogeneous resource needs can lead to unfair outcomes, naive allocation of clients to FL tasks can lead to unfairness, with some tasks having excessively long training times, or lower converged accuracies. Furthermore, in the FL setting, since clients are typically not paid for their training effort, we face a further challenge that some clients may not even be willing to train some tasks, e.g., due to high computational costs, which may exacerbate unfairness in training outcomes across tasks. We address both challenges by firstly designing FedFairMMFL, a difficulty-aware algorithm that dynamically allocates clients to tasks in each training round. We provide guarantees on airness and FedFairMMFL's convergence rate. We then propose a novel auction design that incentivizes clients to train multiple tasks, so as to fairly distribute clients' training efforts across the tasks. We show how our fairness-based learning and incentive mechanisms impact training convergence and finally evaluate our algorithm with multiple sets of learning tasks on real world datasets.
VFP: Converting Tabular Data for IIoT into Images Considering Correlations of Attributes for Convolutional Neural Networks
Mar 16, 2023For tabular data generated from IIoT devices, traditional machine learning (ML) techniques based on the decision tree algorithm have been employed. However, these methods have limitations in processing tabular data where real number attributes dominate. To address this issue, DeepInsight, REFINED, and IGTD were proposed to convert tabular data into images for utilizing convolutional neural networks (CNNs). They gather similar features in some specific spots of an image to make the converted image look like an actual image. Gathering similar features contrasts with traditional ML techniques for tabular data, which drops some highly correlated attributes to avoid overfitting. Also, previous converting methods fixed the image size, and there are wasted or insufficient pixels according to the number of attributes of tabular data. Therefore, this paper proposes a new converting method, Vortex Feature Positioning (VFP). VFP considers the correlation of features and places similar features far away from each. Features are positioned in the vortex shape from the center of an image, and the number of attributes determines the image size. VFP shows better test performance than traditional ML techniques for tabular data and previous converting methods in five datasets: Iris, Wine, Dry Bean, Epileptic Seizure, and SECOM, which have differences in the number of attributes.