 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Signal Processing: History, Development, Impact, and Outlook
Mar 21, 2023Graph signal processing (GSP) generalizes signal processing (SP) tasks to signals living on non-Euclidean domains whose structure can be captured by a weighted graph. Graphs are versatile, able to model irregular interactions, easy to interpret, and endowed with a corpus of mathematical results, rendering them natural candidates to serve as the basis for a theory of processing signals in more irregular domains. In this article, we provide an overview of the evolution of GSP, from its origins to the challenges ahead. The first half is devoted to reviewing the history of GSP and explaining how it gave rise to an encompassing framework that shares multiple similarities with SP. A key message is that GSP has been critical to develop novel and technically sound tools, theory, and algorithms that, by leveraging analogies with and the insights of digital SP, provide new ways to analyze, process, and learn from graph signals. In the second half, we shift focus to review the impact of GSP on other disciplines. First, we look at the use of GSP in data science problems, including graph learning and graph-based deep learning. Second, we discuss the impact of GSP on applications, including neuroscience and image and video processing. We conclude with a brief discussion of the emerging and future directions of GSP.
Signal Processing on the Permutahedron: Tight Spectral Frames for Ranked Data Analysis
Mar 06, 2021



Ranked data sets, where m judges/voters specify a preference ranking of n objects/candidates, are increasingly prevalent in contexts such as political elections, computer vision, recommender systems, and bioinformatics. The vote counts for each ranking can be viewed as an n! data vector lying on the permutahedron, which is a Cayley graph of the symmetric group with vertices labeled by permutations and an edge when two permutations differ by an adjacent transposition. Leveraging combinatorial representation theory and recent progress in signal processing on graphs, we investigate a novel, scalable transform method to interpret and exploit structure in ranked data. We represent data on the permutahedron using an overcomplete dictionary of atoms, each of which captures both smoothness information about the data (typically the focus of spectral graph decomposition methods in graph signal processing) and structural information about the data (typically the focus of symmetry decomposition methods from representation theory). These atoms have a more naturally interpretable structure than any known basis for signals on the permutahedron, and they form a Parseval frame, ensuring beneficial numerical properties such as energy preservation. We develop specialized algorithms and open software that take advantage of the symmetry and structure of the permutahedron to improve the scalability of the proposed method, making it more applicable to the high-dimensional ranked data found in applications.
Localized Spectral Graph Filter Frames: A Unifying Framework, Survey of Design Considerations, and Numerical Comparison
Jun 19, 2020



Representing data residing on a graph as a linear combination of building block signals can enable efficient and insightful visual or statistical analysis of the data, and such representations prove useful as regularizers in signal processing and machine learning tasks. Designing such collections of building block signals -- or more formally, dictionaries of atoms -- that specifically account for the underlying graph structure as well as any available representative training signals has been an active area of research over the last decade. In this article, we survey a particular class of dictionaries called localized spectral graph filter frames, whose atoms are created by localizing spectral patterns to different regions of the graph. After showing how this class encompasses a variety of approaches from spectral graph wavelets to graph filter banks, we focus on the two main questions of how to design the spectral filters and how to select the center vertices to which the patterns are localized. Throughout, we emphasize computationally efficient methods that ensure the resulting transforms and their inverses can be applied to data residing on large, sparse graphs. We demonstrate how this class of transform methods can be used in signal processing tasks such as denoising and non-linear approximation, and provide code for readers to experiment with these methods in new application domains.
Learning parametric dictionaries for graph signals
Jan 05, 2014
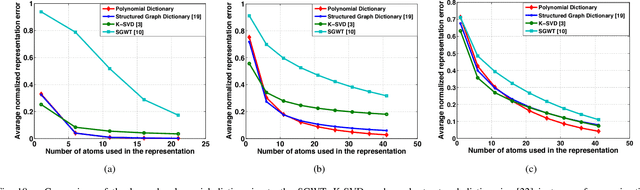


In sparse signal representation, the choice of a dictionary often involves a tradeoff between two desirable properties -- the ability to adapt to specific signal data and a fast implementation of the dictionary. To sparsely represent signals residing on weighted graphs, an additional design challenge is to incorporate the intrinsic geometric structure of the irregular data domain into the atoms of the dictionary. In this work, we propose a parametric dictionary learning algorithm to design data-adapted, structured dictionaries that sparsely represent graph signals. In particular, we model graph signals as combinations of overlapping local patterns. We impose the constraint that each dictionary is a concatenation of subdictionaries, with each subdictionary being a polynomial of the graph Laplacian matrix, representing a single pattern translated to different areas of the graph. The learning algorithm adapts the patterns to a training set of graph signals. Experimental results on both synthetic and real datasets demonstrate that the dictionaries learned by the proposed algorithm are competitive with and often better than unstructured dictionaries learned by state-of-the-art numerical learning algorithms in terms of sparse approximation of graph signals. In contrast to the unstructured dictionaries, however, the dictionaries learned by the proposed algorithm feature localized atoms and can be implemented in a computationally efficient manner in signal processing tasks such as compression, denoising, and classification.
The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains
Mar 10, 2013
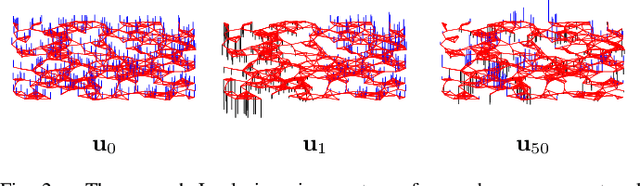
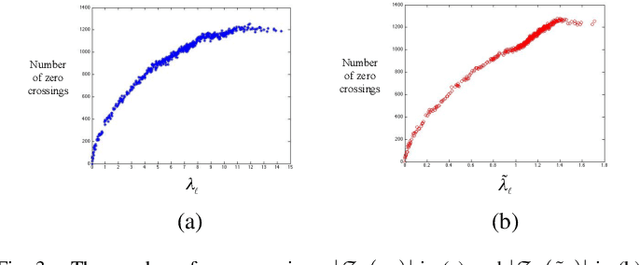

In applications such as social, energy, transportation, sensor, and neuronal networks, high-dimensional data naturally reside on the vertices of weighted graphs. The emerging field of signal processing on graphs merges algebraic and spectral graph theoretic concepts with computational harmonic analysis to process such signals on graphs. In this tutorial overview, we outline the main challenges of the area, discuss different ways to define graph spectral domains, which are the analogues to the classical frequency domain, and highlight the importance of incorporating the irregular structures of graph data domains when processing signals on graphs. We then review methods to generalize fundamental operations such as filtering, translation, modulation, dilation, and downsampling to the graph setting, and survey the localized, multiscale transforms that have been proposed to efficiently extract information from high-dimensional data on graphs. We conclude with a brief discussion of open issues and possible extensions.