 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Topic Modeling and Factor Analysis of Textual Information and Graded Response Data
Paper and Code
May 10, 2013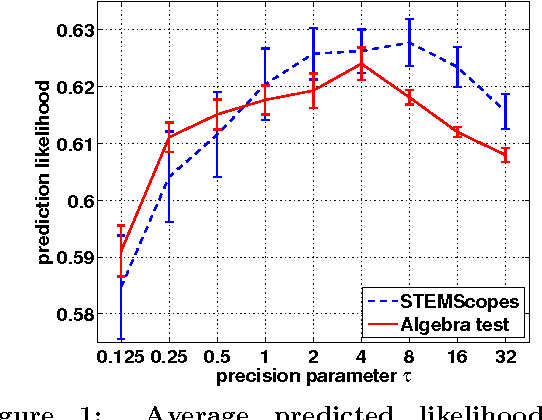
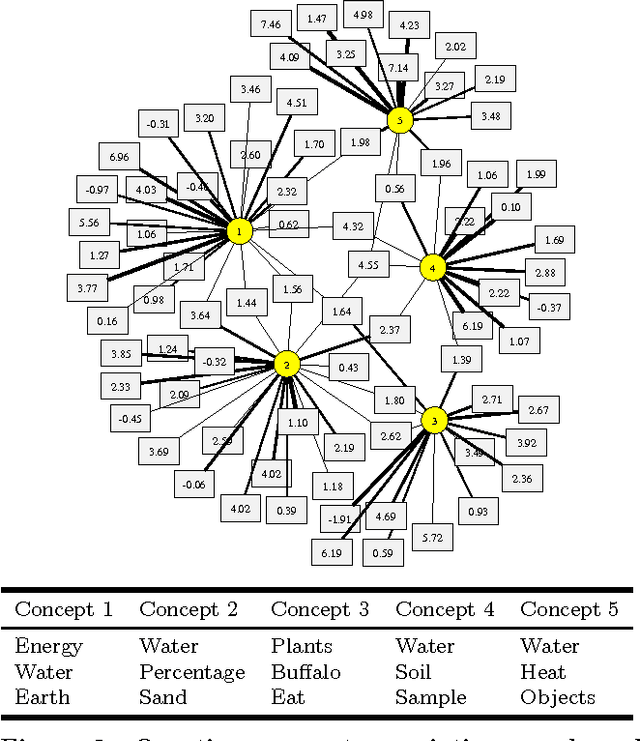
Modern machine learning methods are critical to the development of large-scale personalized learning systems that cater directly to the needs of individual learners. The recently developed SPARse Factor Analysis (SPARFA) framework provides a new statistical model and algorithms for machine learning-based learning analytics, which estimate a learner's knowledge of the latent concepts underlying a domain, and content analytics, which estimate the relationships among a collection of questions and the latent concepts. SPARFA estimates these quantities given only the binary-valued graded responses to a collection of questions. In order to better interpret the estimated latent concepts, SPARFA relies on a post-processing step that utilizes user-defined tags (e.g., topics or keywords) available for each question. In this paper, we relax the need for user-defined tags by extending SPARFA to jointly process both graded learner responses and the text of each question and its associated answer(s) or other feedback. Our purely data-driven approach (i) enhances the interpretability of the estimated latent concepts without the need of explicitly generating a set of tags or performing a post-processing step, (ii) improves the prediction performance of SPARFA, and (iii) scales to large test/assessments where human annotation would prove burdensome. We demonstrate the efficacy of the proposed approach on two real educational datasets.