 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-margin Analysis for Hidden Neuron Activation Labels
May 14, 2024



Understanding how high-level concepts are represented within artificial neural networks is a fundamental challenge in the field of artificial intelligence. While existing literature in explainable AI emphasizes the importance of labeling neurons with concepts to understand their functioning, they mostly focus on identifying what stimulus activates a neuron in most cases, this corresponds to the notion of recall in information retrieval. We argue that this is only the first-part of a two-part job, it is imperative to also investigate neuron responses to other stimuli, i.e., their precision. We call this the neuron labels error margin.
On the Value of Labeled Data and Symbolic Methods for Hidden Neuron Activation Analysis
Apr 21, 2024A major challenge in Explainable AI is in correctly interpreting activations of hidden neurons: accurate interpretations would help answer the question of what a deep learning system internally detects as relevant in the input, demystifying the otherwise black-box nature of deep learning systems. The state of the art indicates that hidden node activations can, in some cases, be interpretable in a way that makes sense to humans, but systematic automated methods that would be able to hypothesize and verify interpretations of hidden neuron activations are underexplored. This is particularly the case for approaches that can both draw explanations from substantial background knowledge, and that are based on inherently explainable (symbolic) methods. In this paper, we introduce a novel model-agnostic post-hoc Explainable AI method demonstrating that it provides meaningful interpretations. Our approach is based on using a Wikipedia-derived concept hierarchy with approximately 2 million classes as background knowledge, and utilizes OWL-reasoning-based Concept Induction for explanation generation. Additionally, we explore and compare the capabilities of off-the-shelf pre-trained multimodal-based explainable methods. Our results indicate that our approach can automatically attach meaningful class expressions as explanations to individual neurons in the dense layer of a Convolutional Neural Network. Evaluation through statistical analysis and degree of concept activation in the hidden layer show that our method provides a competitive edge in both quantitative and qualitative aspects compared to prior work.
A Modular Ontology for MODS -- Metadata Object Description Schema
Jul 31, 2023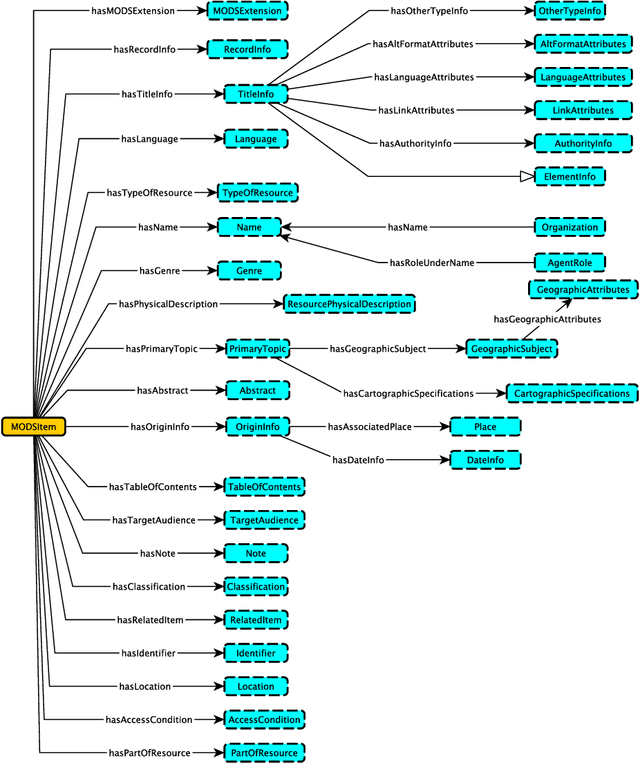
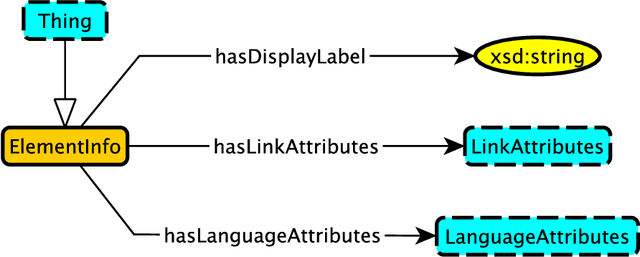
The Metadata Object Description Schema (MODS) was developed to describe bibliographic concepts and metadata and is maintained by the Library of Congress. Its authoritative version is given as an XML schema based on an XML mindset which means that it has significant limitations for use in a knowledge graphs context. We have therefore developed the Modular MODS Ontology (MMODS-O) which incorporates all elements and attributes of the MODS XML schema. In designing the ontology, we adopt the recent Modular Ontology Design Methodology (MOMo) with the intention to strike a balance between modularity and quality ontology design on the one hand, and conservative backward compatibility with MODS on the other.
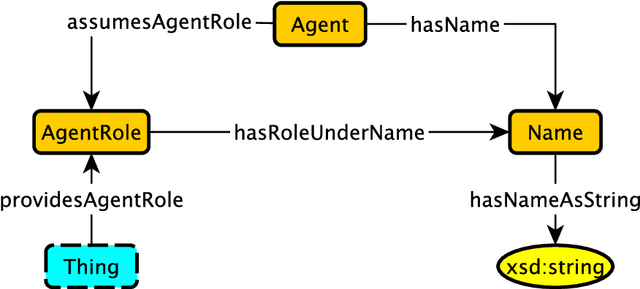
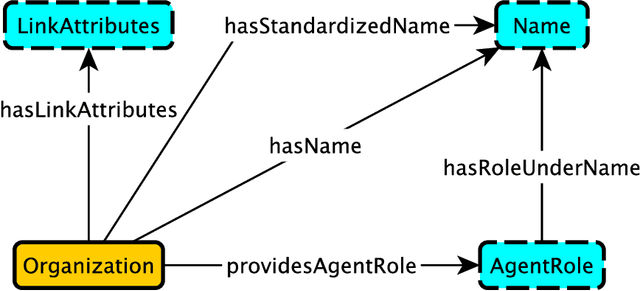
An Ontology Design Pattern for Role-Dependent Names
May 03, 2023We present an ontology design pattern for modeling Names as part of Roles, to capture scenarios where an Agent performs different Roles using different Names associated with the different Roles. Examples of an Agent performing a Role using different Names are rather ubiquitous, e.g., authors who write under different pseudonyms, or different legal names for citizens of more than one country. The proposed pattern is a modified merger of a standard Agent Role and a standard Name pattern stub.