 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering of Pain Dynamics in Sickle Cell Disease from Sparse, Uneven Samples
Aug 31, 2021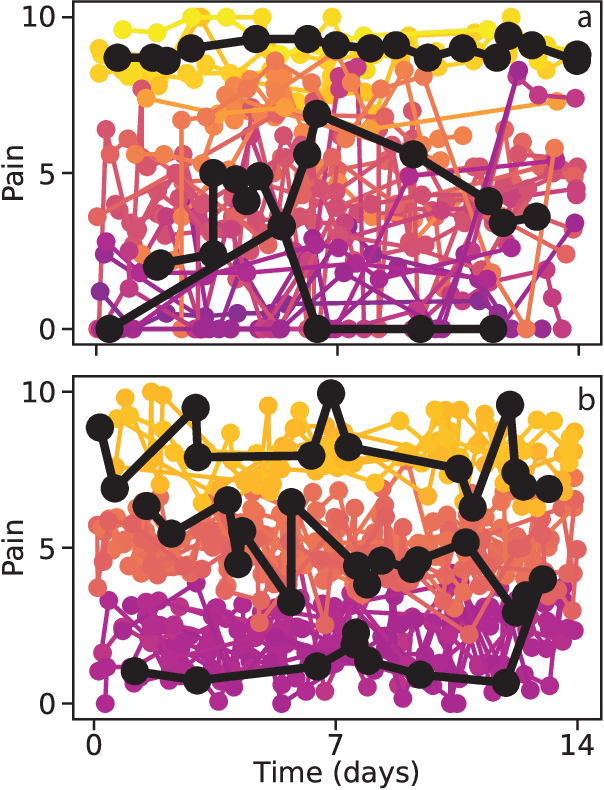

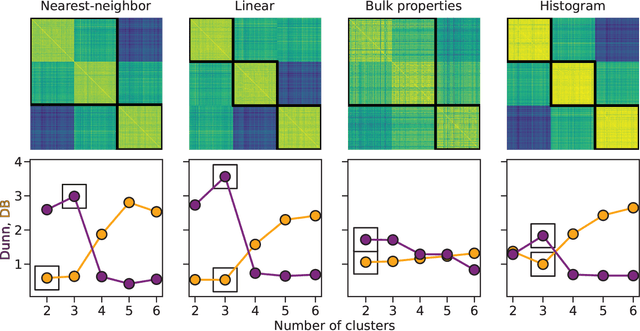
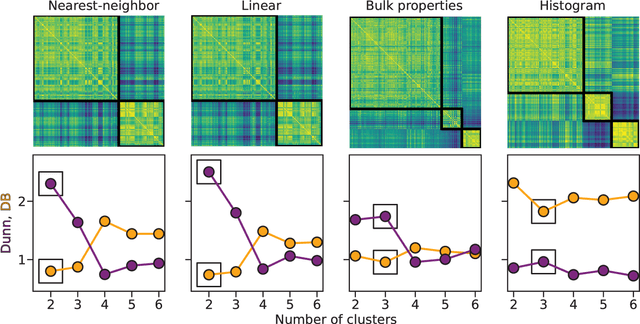
Irregularly sampled time series data are common in a variety of fields. Many typical methods for drawing insight from data fail in this case. Here we attempt to generalize methods for clustering trajectories to irregularly and sparsely sampled data. We first construct synthetic data sets, then propose and assess four methods of data alignment to allow for application of spectral clustering. We also repeat the same process for real data drawn from medical records of patients with sickle cell disease -- patients whose subjective experiences of pain were tracked for several months via a mobile app. We find that different methods for aligning irregularly sampled sparse data sets can lead to different optimal numbers of clusters, even for synthetic data with known properties. For the case of sickle cell disease, we find that three clusters is a reasonable choice, and these appear to correspond to (1) a low pain group with occasionally acute pain, (2) a group which experiences moderate mean pain that fluctuates often from low to high, and (3) a group that experiences persistent high levels of pain. Our results may help physicians and patients better understand and manage patients' pain levels over time, and we expect that the methods we develop will apply to a wide range of other data sources in medicine and beyond.
Pain Intensity Assessment in Sickle Cell Disease patients using Vital Signs during Hospital Visits
Nov 24, 2020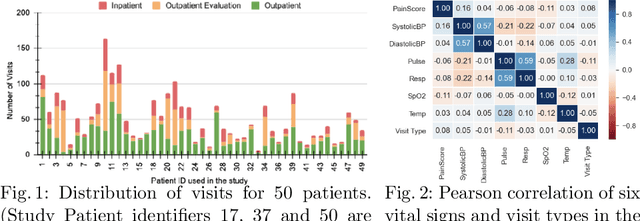
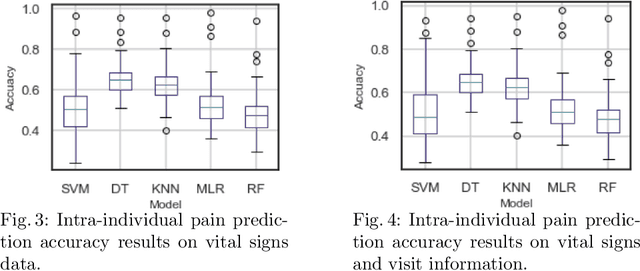
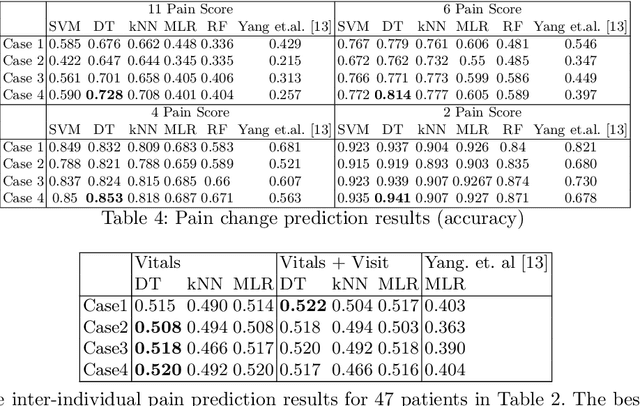
Pain in sickle cell disease (SCD) is often associated with increased morbidity, mortality, and high healthcare costs. The standard method for predicting the absence, presence, and intensity of pain has long been self-report. However, medical providers struggle to manage patients based on subjective pain reports correctly and pain medications often lead to further difficulties in patient communication as they may cause sedation and sleepiness. Recent studies have shown that objective physiological measures can predict subjective self-reported pain scores for inpatient visits using machine learning (ML) techniques. In this study, we evaluate the generalizability of ML techniques to data collected from 50 patients over an extended period across three types of hospital visits (i.e., inpatient, outpatient and outpatient evaluation). We compare five classification algorithms for various pain intensity levels at both intra-individual (within each patient) and inter-individual (between patients) level. While all the tested classifiers perform much better than chance, a Decision Tree (DT) model performs best at predicting pain on an 11-point severity scale (from 0-10) with an accuracy of 0.728 at an inter-individual level and 0.653 at an intra-individual level. The accuracy of DT significantly improves to 0.941 on a 2-point rating scale (i.e., no/mild pain: 0-5, severe pain: 6-10) at an intra-individual level. Our experimental results demonstrate that ML techniques can provide an objective and quantitative evaluation of pain intensity levels for all three types of hospital visits.