 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Set of Pragmatic Considerations in Conversational AI
Oct 27, 2023Despite considerable performance improvements, current conversational AI systems often fail to meet user expectations. We discuss several pragmatic limitations of current conversational AI systems. We illustrate pragmatic limitations with examples that are syntactically appropriate, but have clear pragmatic deficiencies. We label our complaints as "Turing Test Triggers" (TTTs) as they indicate where current conversational AI systems fall short compared to human behavior. We develop a taxonomy of pragmatic considerations intended to identify what pragmatic competencies a conversational AI system requires and discuss implications for the design and evaluation of conversational AI systems.
Evaluating the Deductive Competence of Large Language Models
Sep 11, 2023
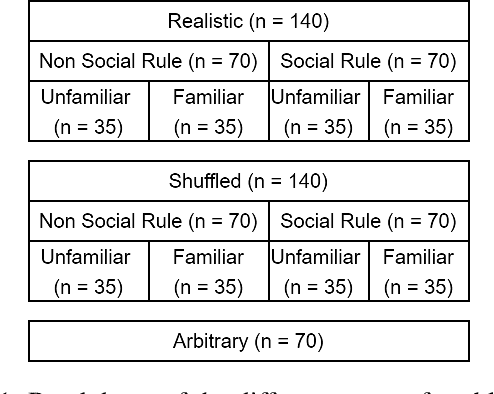
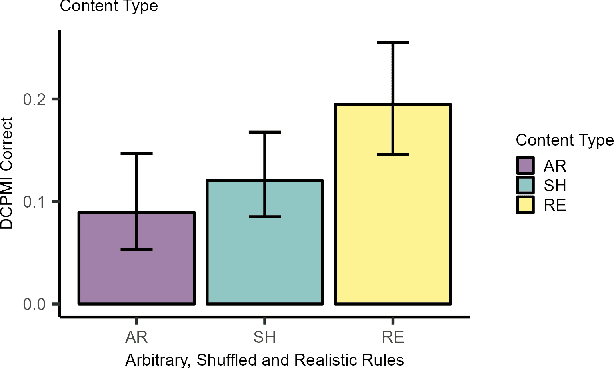
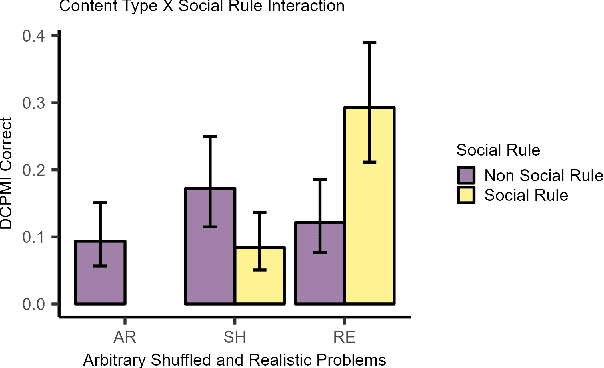
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance.
Long-form analogies generated by chatGPT lack human-like psycholinguistic properties
Jun 07, 2023Psycholinguistic analyses provide a means of evaluating large language model (LLM) output and making systematic comparisons to human-generated text. These methods can be used to characterize the psycholinguistic properties of LLM output and illustrate areas where LLMs fall short in comparison to human-generated text. In this work, we apply psycholinguistic methods to evaluate individual sentences from long-form analogies about biochemical concepts. We compare analogies generated by human subjects enrolled in introductory biochemistry courses to analogies generated by chatGPT. We perform a supervised classification analysis using 78 features extracted from Coh-metrix that analyze text cohesion, language, and readability (Graesser et. al., 2004). Results illustrate high performance for classifying student-generated and chatGPT-generated analogies. To evaluate which features contribute most to model performance, we use a hierarchical clustering approach. Results from this analysis illustrate several linguistic differences between the two sources.
Discourse over Discourse: The Need for an Expanded Pragmatic Focus in Conversational AI
Apr 27, 2023The summarization of conversation, that is, discourse over discourse, elevates pragmatic considerations as a pervasive limitation of both summarization and other applications of contemporary conversational AI. Building on impressive progress in both semantics and syntax, pragmatics concerns meaning in the practical sense. In this paper, we discuss several challenges in both summarization of conversations and other conversational AI applications, drawing on relevant theoretical work. We illustrate the importance of pragmatics with so-called star sentences, syntactically acceptable propositions that are pragmatically inappropriate in conversation or its summary. Because the baseline for quality of AI is indistinguishability from human behavior, we draw heavily on the psycho-linguistics literature, and label our complaints as "Turing Test Triggers" (TTTs). We discuss implications for the design and evaluation of conversation summarization methods and conversational AI applications like voice assistants and chatbots