 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPS: A Diagnostic Challenge Set for Arabic Linguistic & Pragmatic Reasoning
Feb 19, 2026While recent Arabic NLP benchmarks focus on scale, they often rely on synthetic or translated data which may benefit from deeper linguistic verification. We introduce ALPS (Arabic Linguistic & Pragmatic Suite), a native, expert-curated diagnostic challenge set probing Deep Semantics and Pragmatics, capabilities that complement specialized large-scale benchmarks. While broad-coverage benchmarks prioritize scale and multi-task coverage, ALPS targets the depth of linguistic understanding through 531 rigorously crafted questions across 15 tasks and 47 subtasks. We developed the dataset with deep expertise in Arabic linguistics, guaranteeing cultural authenticity and eliminating translation artifacts. Evaluating 23 diverse models (commercial, open-source, and Arabic-native) against a single-pass human performance (avg. 84.6% accuracy) and an expert-adjudicated oracle (99.2%), we reveal a critical dissociation: models achieve high fluency but fail on fundamental morpho-syntactic dependencies, with elevated error rates on morpho-syntactic dependencies (36.5% across diacritics-reliant tasks) compared to compositional semantics. While top commercial models (Gemini-3-flash at 94.2%) surpass the average single human, a substantial gap persists between commercial giants and Arabic-native models, with the best Arabic-specific model (Jais-2-70B at 83.6%) approaching but not matching human performance.
Towards Geocoding Spatial Expressions
Jun 12, 2019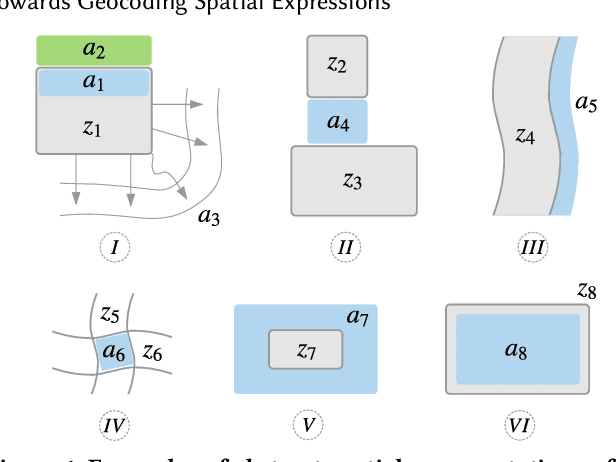
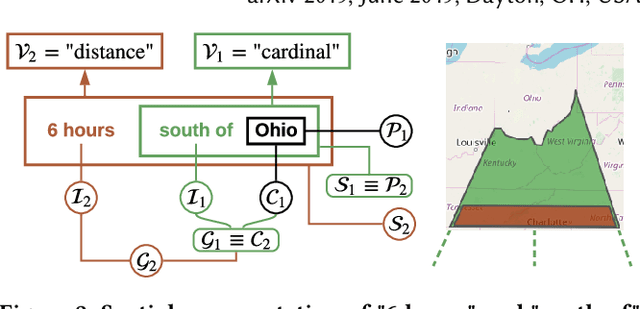
Imprecise composite location references formed using ad hoc spatial expressions in English text makes the geocoding task challenging for both inference and evaluation. Typically such spatial expressions fill in unestablished areas with new toponyms for finer spatial referents. For example, the spatial extent of the ad hoc spatial expression "north of" or "50 minutes away from" in relation to the toponym "Dayton, OH" refers to an ambiguous, imprecise area, requiring translation from this qualitative representation to a quantitative one with precise semantics using systems such as WGS84. Here we highlight the challenges of geocoding such referents and propose a formal representation that employs background knowledge, semantic approximations and rules, and fuzzy linguistic variables. We also discuss an appropriate evaluation technique for the task that is based on human contextualized and subjective judgment.
A Practical Incremental Learning Framework For Sparse Entity Extraction
Jun 26, 2018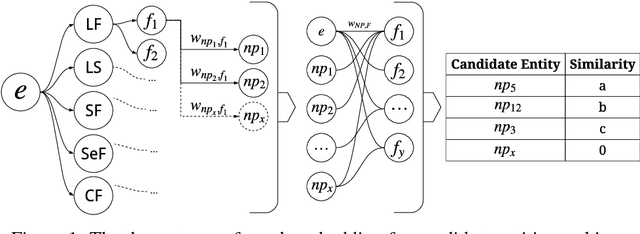
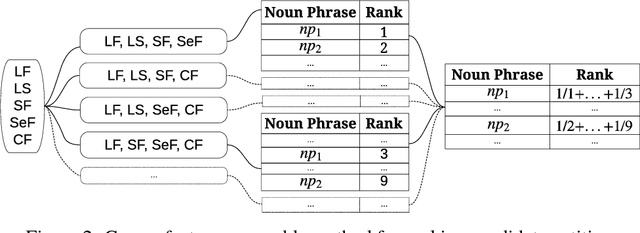
This work addresses challenges arising from extracting entities from textual data, including the high cost of data annotation, model accuracy, selecting appropriate evaluation criteria, and the overall quality of annotation. We present a framework that integrates Entity Set Expansion (ESE) and Active Learning (AL) to reduce the annotation cost of sparse data and provide an online evaluation method as feedback. This incremental and interactive learning framework allows for rapid annotation and subsequent extraction of sparse data while maintaining high accuracy. We evaluate our framework on three publicly available datasets and show that it drastically reduces the cost of sparse entity annotation by an average of 85% and 45% to reach 0.9 and 1.0 F-Scores respectively. Moreover, the method exhibited robust performance across all datasets.
Location Name Extraction from Targeted Text Streams using Gazetteer-based Statistical Language Models
Jun 07, 2018
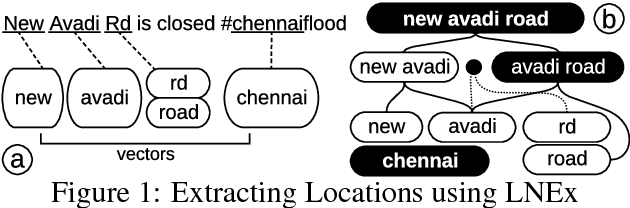

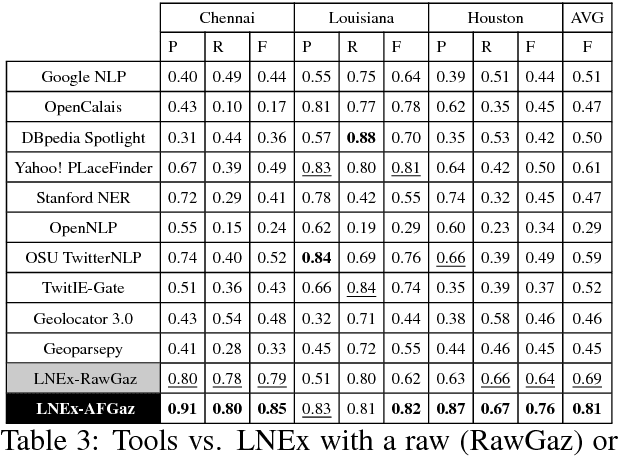
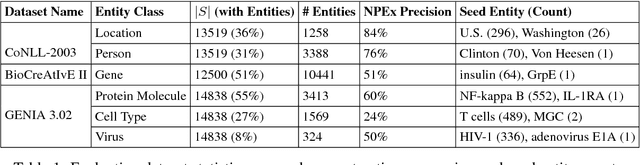
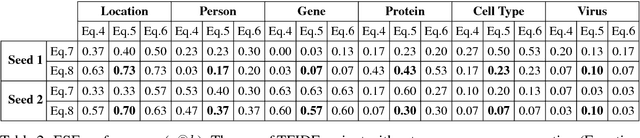
Extracting location names from informal and unstructured social media data requires the identification of referent boundaries and partitioning compound names. Variability, particularly systematic variability in location names (Carroll, 1983), challenges the identification task. Some of this variability can be anticipated as operations within a statistical language model, in this case drawn from gazetteers such as OpenStreetMap (OSM), Geonames, and DBpedia. This permits evaluation of an observed n-gram in Twitter targeted text as a legitimate location name variant from the same location-context. Using n-gram statistics and location-related dictionaries, our Location Name Extraction tool (LNEx) handles abbreviations and automatically filters and augments the location names in gazetteers (handling name contractions and auxiliary contents) to help detect the boundaries of multi-word location names and thereby delimit them in texts. We evaluated our approach on 4,500 event-specific tweets from three targeted streams to compare the performance of LNEx against that of ten state-of-the-art taggers that rely on standard semantic, syntactic and/or orthographic features. LNEx improved the average F-Score by 33-179%, outperforming all taggers. Further, LNEx is capable of stream processing.
Semi-Supervised Approach to Monitoring Clinical Depressive Symptoms in Social Media
Oct 16, 2017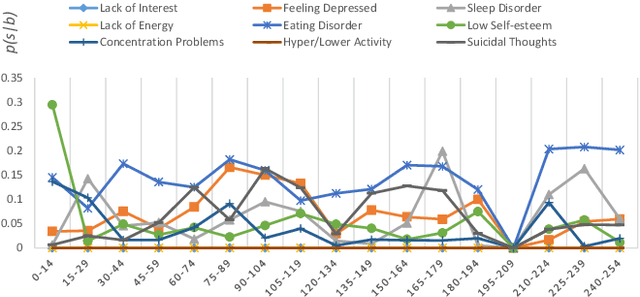
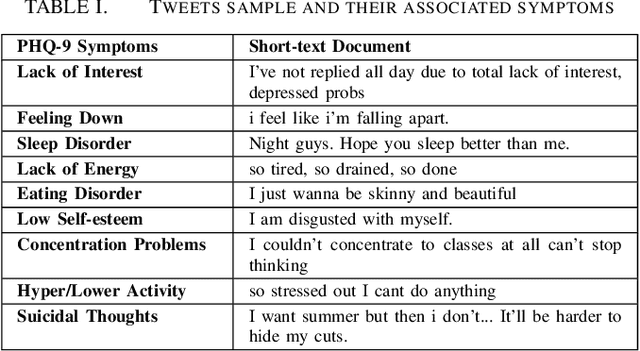
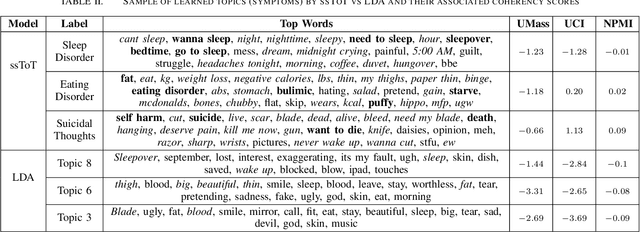
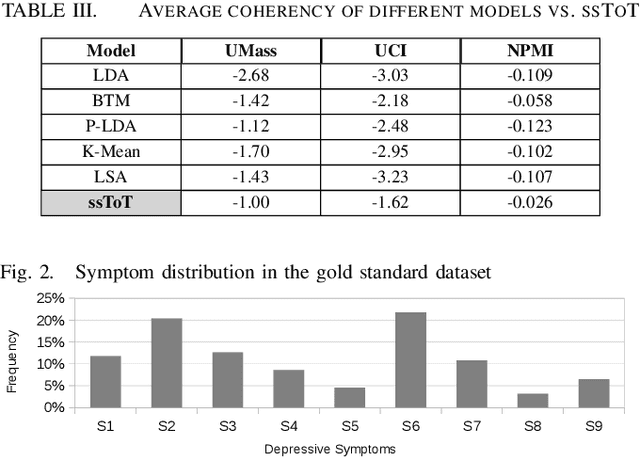
With the rise of social media, millions of people are routinely expressing their moods, feelings, and daily struggles with mental health issues on social media platforms like Twitter. Unlike traditional observational cohort studies conducted through questionnaires and self-reported surveys, we explore the reliable detection of clinical depression from tweets obtained unobtrusively. Based on the analysis of tweets crawled from users with self-reported depressive symptoms in their Twitter profiles, we demonstrate the potential for detecting clinical depression symptoms which emulate the PHQ-9 questionnaire clinicians use today. Our study uses a semi-supervised statistical model to evaluate how the duration of these symptoms and their expression on Twitter (in terms of word usage patterns and topical preferences) align with the medical findings reported via the PHQ-9. Our proactive and automatic screening tool is able to identify clinical depressive symptoms with an accuracy of 68% and precision of 72%.
Particle Swarm Optimized Power Consumption of Trilateration
Feb 08, 2016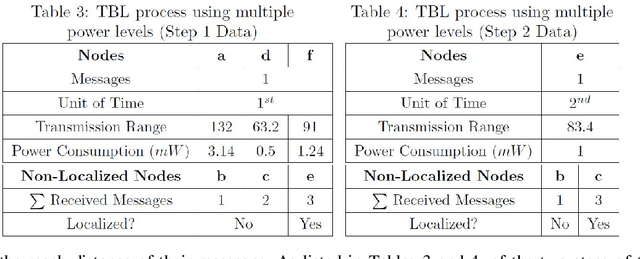

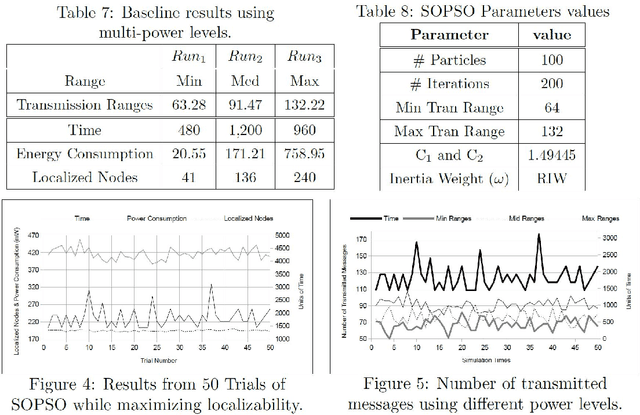
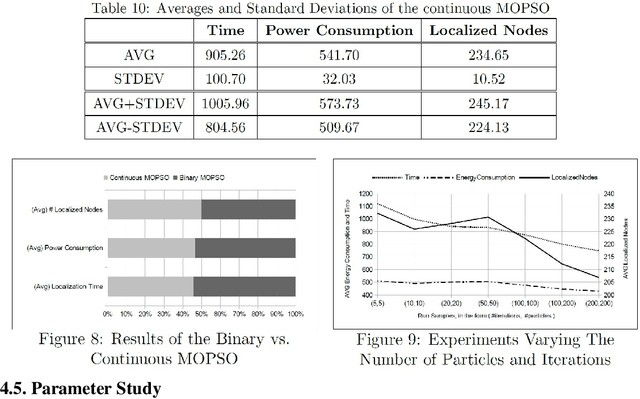
Trilateration-based localization (TBL) has become a corner stone of modern technology. This study formulates the concern on how wireless sensor networks can take advantage of the computational intelligent techniques using both single- and multi-objective particle swarm optimization (PSO) with an overall aim of concurrently minimizing the required time for localization, minimizing energy consumed during localization, and maximizing the number of nodes fully localized through the adjustment of wireless sensor transmission ranges while using TBL process. A parameter-study of the applied PSO variants is performed, leading to results that show algorithmic improvements of up to 32% in the evaluated objectives.
* 19 Pages, 13 Figures, 10 Tables, Journal