 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Small and Imbalanced Medical Image Datasets Using Generative Models: A Comparative Study of DDPM and PGGANs with Random and Greedy K Sampling
Dec 17, 2024The development of accurate medical image classification models is often constrained by privacy concerns and data scarcity for certain conditions, leading to small and imbalanced datasets. To address these limitations, this study explores the use of generative models, such as Denoising Diffusion Probabilistic Models (DDPM) and Progressive Growing Generative Adversarial Networks (PGGANs), for dataset augmentation. The research introduces a framework to assess the impact of synthetic images generated by DDPM and PGGANs on the performance of four models: a custom CNN, Untrained VGG16, Pretrained VGG16, and Pretrained ResNet50. Experiments were conducted using Random Sampling and Greedy K Sampling to create small, imbalanced datasets. The synthetic images were evaluated using Frechet Inception Distance (FID) and compared to original datasets through classification metrics. The results show that DDPM consistently generated more realistic images with lower FID scores and significantly outperformed PGGANs in improving classification metrics across all models and datasets. Incorporating DDPM-generated images into the original datasets increased accuracy by up to 6%, enhancing model robustness and stability, particularly in imbalanced scenarios. Random Sampling demonstrated superior stability, while Greedy K Sampling offered diversity at the cost of higher FID scores. This study highlights the efficacy of DDPM in augmenting small, imbalanced medical image datasets, improving model performance by balancing the dataset and expanding its size.
Distance Correlation Sure Independence Screening for Accelerated Feature Selection in Parkinson's Disease Vocal Data
Jun 23, 2020
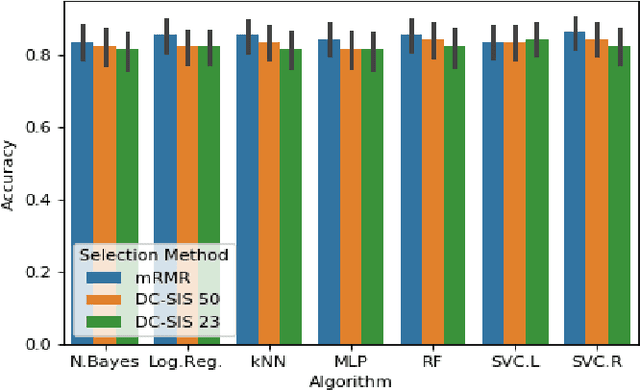
With the abundance of machine learning methods available and the temptation of using them all in an ensemble method, having a model-agnostic method of feature selection is incredibly alluring. Principal component analysis was developed in 1901 and has been a strong contender in this role since, but in the end is an unsupervised method. It offers no guarantee that the features that are selected have good predictive power because it does not know what is being predicted. To this end, Peng et al. developed the minimum redundancy-maximum relevance (mRMR) method in 2005. It uses the mutual information not only between predictors but also includes the mutual information with the response in its calculation. Estimating mutual information and entropy tend to be expensive and problematic endeavors, which leads to excessive processing times even for dataset that is approximately 750 by 750 in a Leave-One-Subject-Out jackknife situation. To remedy this, we use a method from 2012 called Distance Correlation Sure Independence Screening (DC-SIS) which uses the distance correlation measure of Sz\'ekely et al. to select features that have the greatest dependence with the response. We show that this method produces statistically indistinguishable results to the mRMR selection method on Parkinson's Disease vocal diagnosis data 90 times faster.
Particle Swarm Optimized Power Consumption of Trilateration
Feb 08, 2016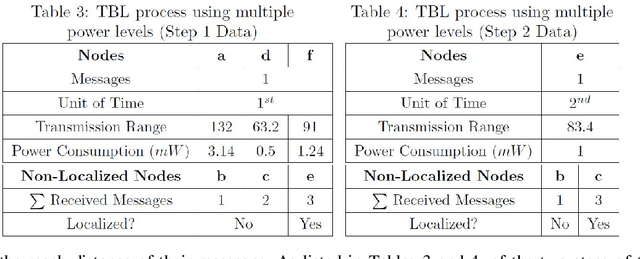

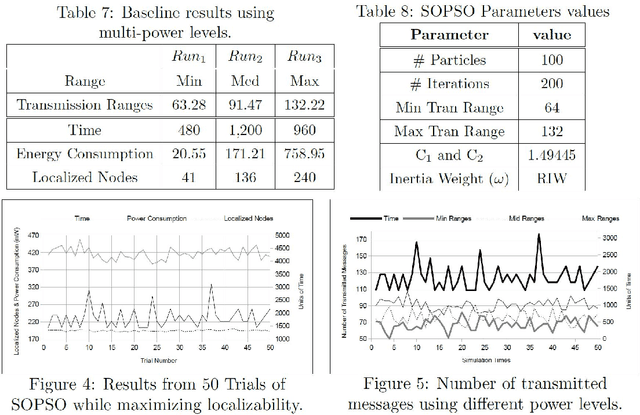
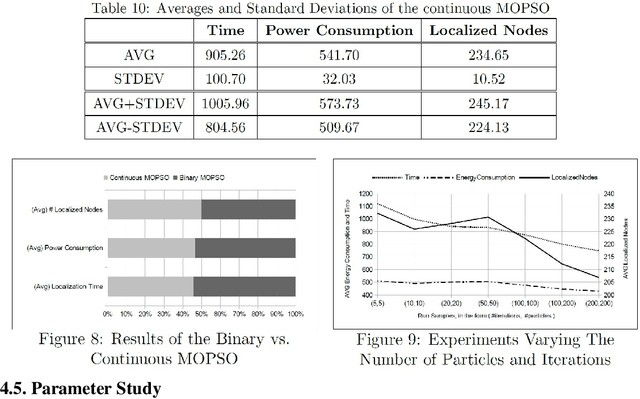
Trilateration-based localization (TBL) has become a corner stone of modern technology. This study formulates the concern on how wireless sensor networks can take advantage of the computational intelligent techniques using both single- and multi-objective particle swarm optimization (PSO) with an overall aim of concurrently minimizing the required time for localization, minimizing energy consumed during localization, and maximizing the number of nodes fully localized through the adjustment of wireless sensor transmission ranges while using TBL process. A parameter-study of the applied PSO variants is performed, leading to results that show algorithmic improvements of up to 32% in the evaluated objectives.
* 19 Pages, 13 Figures, 10 Tables, Journal