 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Correlation Sure Independence Screening for Accelerated Feature Selection in Parkinson's Disease Vocal Data
Paper and Code
Jun 23, 2020
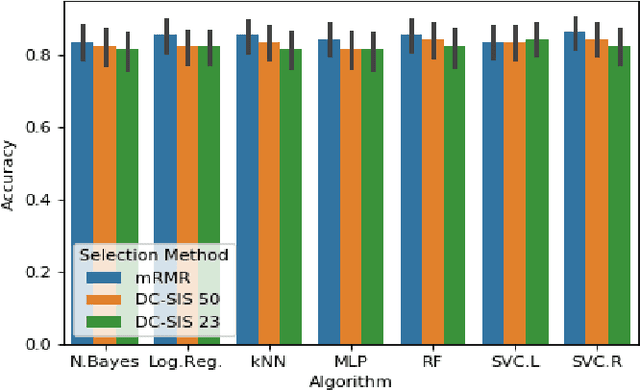
With the abundance of machine learning methods available and the temptation of using them all in an ensemble method, having a model-agnostic method of feature selection is incredibly alluring. Principal component analysis was developed in 1901 and has been a strong contender in this role since, but in the end is an unsupervised method. It offers no guarantee that the features that are selected have good predictive power because it does not know what is being predicted. To this end, Peng et al. developed the minimum redundancy-maximum relevance (mRMR) method in 2005. It uses the mutual information not only between predictors but also includes the mutual information with the response in its calculation. Estimating mutual information and entropy tend to be expensive and problematic endeavors, which leads to excessive processing times even for dataset that is approximately 750 by 750 in a Leave-One-Subject-Out jackknife situation. To remedy this, we use a method from 2012 called Distance Correlation Sure Independence Screening (DC-SIS) which uses the distance correlation measure of Sz\'ekely et al. to select features that have the greatest dependence with the response. We show that this method produces statistically indistinguishable results to the mRMR selection method on Parkinson's Disease vocal diagnosis data 90 times faster.