 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Visual, Textual and Connectivity Clues for Studying Mental Health
Feb 19, 2019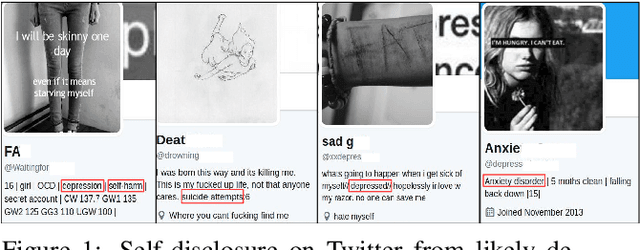
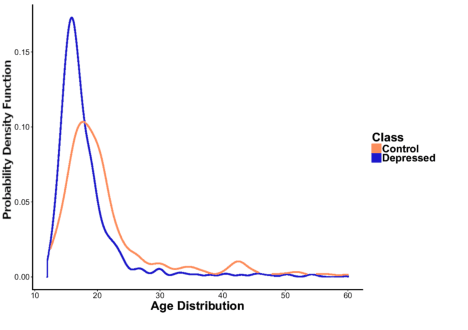
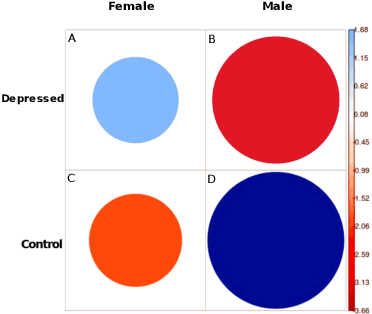
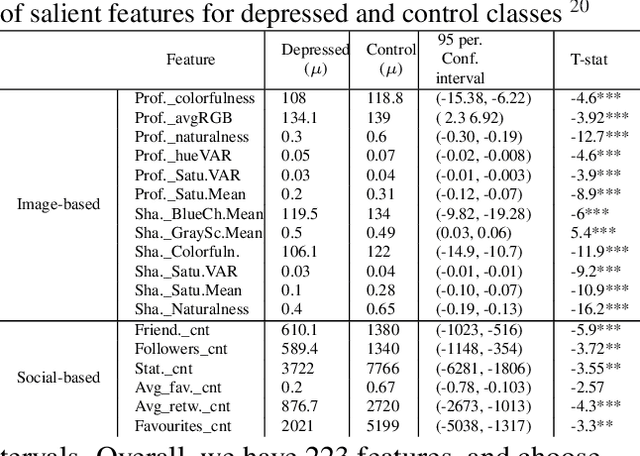
With ubiquity of social media platforms, millions of people are sharing their online persona by expressing their thoughts, moods, emotions, feelings, and even their daily struggles with mental health issues voluntarily and publicly on social media. Unlike the most existing efforts which study depression by analyzing textual content, we examine and exploit multimodal big data to discern depressive behavior using a wide variety of features including individual-level demographics. By developing a multimodal framework and employing statistical techniques for fusing heterogeneous sets of features obtained by processing visual, textual and user interaction data, we significantly enhance the current state-of-the-art approaches for identifying depressed individuals on Twitter (improving the average F1-Score by 5 percent) as well as facilitate demographic inference from social media for broader applications. Besides providing insights into the relationship between demographics and mental health, our research assists in the design of a new breed of demographic-aware health interventions.
Semi-Supervised Approach to Monitoring Clinical Depressive Symptoms in Social Media
Oct 16, 2017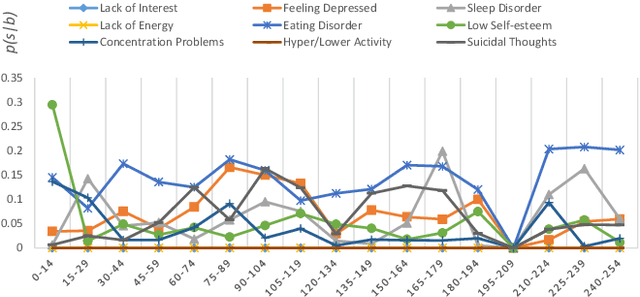
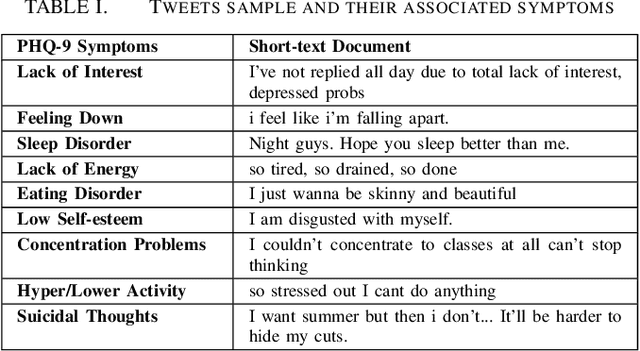
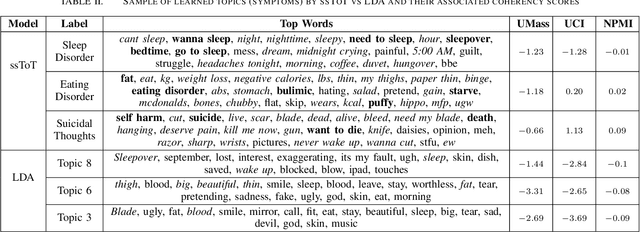
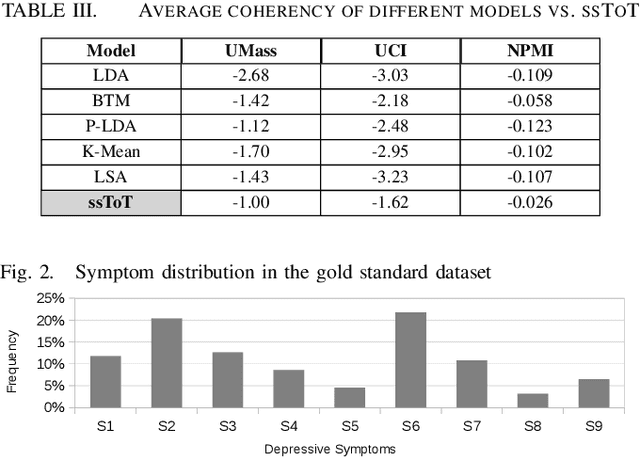
With the rise of social media, millions of people are routinely expressing their moods, feelings, and daily struggles with mental health issues on social media platforms like Twitter. Unlike traditional observational cohort studies conducted through questionnaires and self-reported surveys, we explore the reliable detection of clinical depression from tweets obtained unobtrusively. Based on the analysis of tweets crawled from users with self-reported depressive symptoms in their Twitter profiles, we demonstrate the potential for detecting clinical depression symptoms which emulate the PHQ-9 questionnaire clinicians use today. Our study uses a semi-supervised statistical model to evaluate how the duration of these symptoms and their expression on Twitter (in terms of word usage patterns and topical preferences) align with the medical findings reported via the PHQ-9. Our proactive and automatic screening tool is able to identify clinical depressive symptoms with an accuracy of 68% and precision of 72%.
On the Challenges of Sentiment Analysis for Dynamic Events
Oct 06, 2017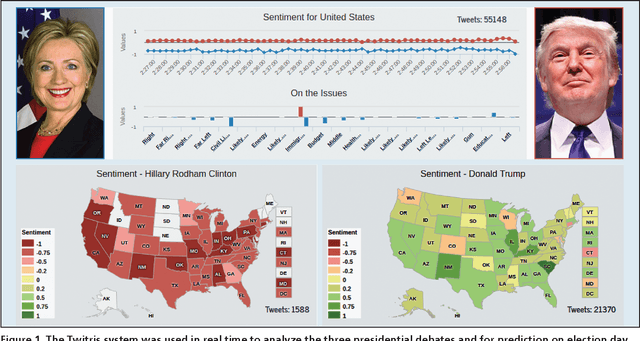
With the proliferation of social media over the last decade, determining people's attitude with respect to a specific topic, document, interaction or events has fueled research interest in natural language processing and introduced a new channel called sentiment and emotion analysis. For instance, businesses routinely look to develop systems to automatically understand their customer conversations by identifying the relevant content to enhance marketing their products and managing their reputations. Previous efforts to assess people's sentiment on Twitter have suggested that Twitter may be a valuable resource for studying political sentiment and that it reflects the offline political landscape. According to a Pew Research Center report, in January 2016 44 percent of US adults stated having learned about the presidential election through social media. Furthermore, 24 percent reported use of social media posts of the two candidates as a source of news and information, which is more than the 15 percent who have used both candidates' websites or emails combined. The first presidential debate between Trump and Hillary was the most tweeted debate ever with 17.1 million tweets.
Fuzzy Based Implicit Sentiment Analysis on Quantitative Sentences
Jan 03, 2017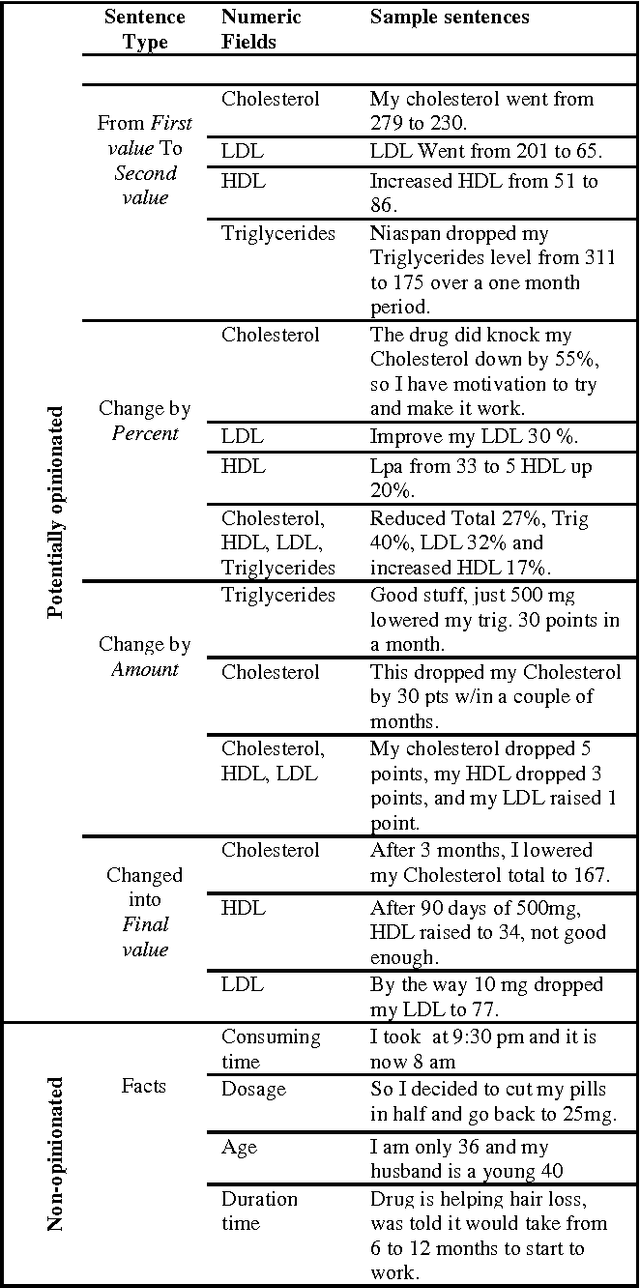
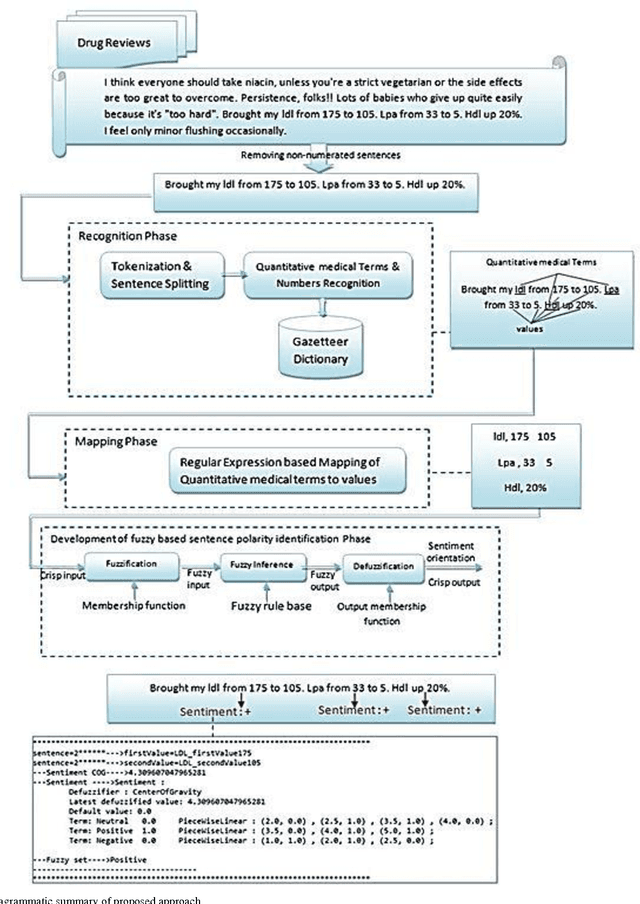
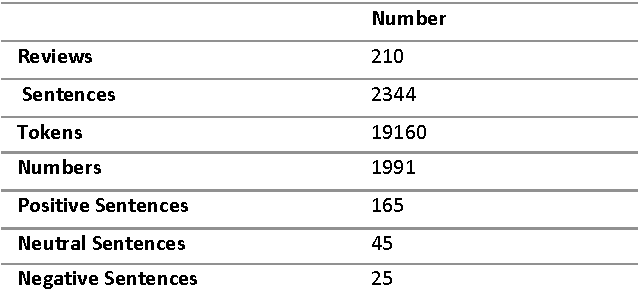
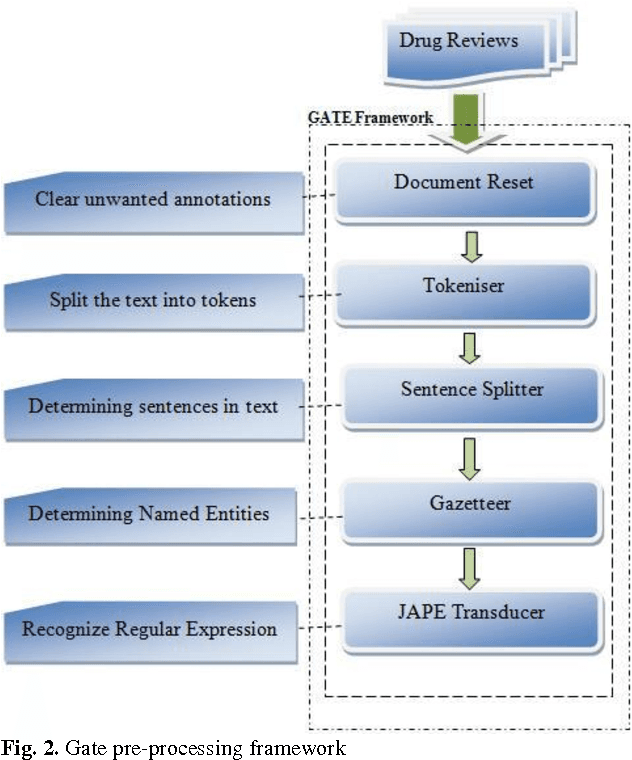
With the rapid growth of social media on the web, emotional polarity computation has become a flourishing frontier in the text mining community. However, it is challenging to understand the latest trends and summarize the state or general opinions about products due to the big diversity and size of social media data and this creates the need of automated and real time opinion extraction and mining. On the other hand, the bulk of current research has been devoted to study the subjective sentences which contain opinion keywords and limited work has been reported for objective statements that imply sentiment. In this paper, fuzzy based knowledge engineering model has been developed for sentiment classification of special group of such sentences including the change or deviation from desired range or value. Drug reviews are the rich source of such statements. Therefore, in this research, some experiments were carried out on patient's reviews on several different cholesterol lowering drugs to determine their sentiment polarity. The main conclusion through this study is, in order to increase the accuracy level of existing drug opinion mining systems, objective sentences which imply opinion should be taken into account. Our experimental results demonstrate that our proposed model obtains over 72 percent F1 value.