 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebias-CLR: A Contrastive Learning Based Debiasing Method for Algorithmic Fairness in Healthcare Applications
Nov 20, 2024



Artificial intelligence based predictive models trained on the clinical notes can be demographically biased. This could lead to adverse healthcare disparities in predicting outcomes like length of stay of the patients. Thus, it is necessary to mitigate the demographic biases within these models. We proposed an implicit in-processing debiasing method to combat disparate treatment which occurs when the machine learning model predict different outcomes for individuals based on the sensitive attributes like gender, ethnicity, race, and likewise. For this purpose, we used clinical notes of heart failure patients and used diagnostic codes, procedure reports and physiological vitals of the patients. We used Clinical BERT to obtain feature embeddings within the diagnostic codes and procedure reports, and LSTM autoencoders to obtain feature embeddings within the physiological vitals. Then, we trained two separate deep learning contrastive learning frameworks, one for gender and the other for ethnicity to obtain debiased representations within those demographic traits. We called this debiasing framework Debias-CLR. We leveraged clinical phenotypes of the patients identified in the diagnostic codes and procedure reports in the previous study to measure fairness statistically. We found that Debias-CLR was able to reduce the Single-Category Word Embedding Association Test (SC-WEAT) effect size score when debiasing for gender and ethnicity. We further found that to obtain fair representations in the embedding space using Debias-CLR, the accuracy of the predictive models on downstream tasks like predicting length of stay of the patients did not get reduced as compared to using the un-debiased counterparts for training the predictive models. Hence, we conclude that our proposed approach, Debias-CLR is fair and representative in mitigating demographic biases and can reduce health disparities.
Fusing Visual, Textual and Connectivity Clues for Studying Mental Health
Feb 19, 2019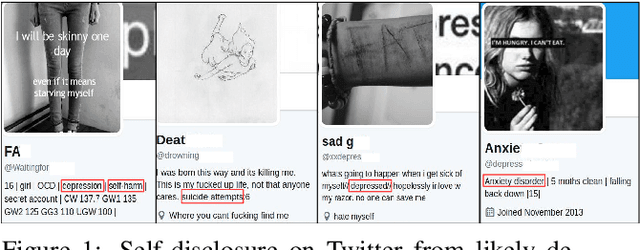
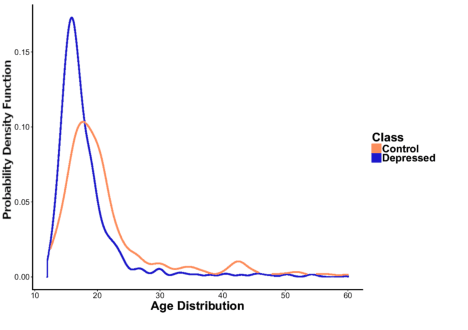
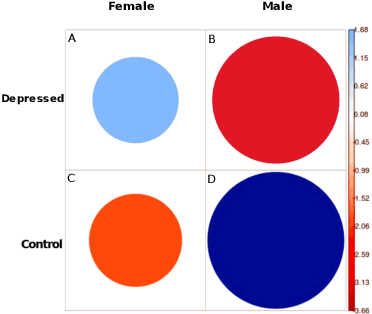
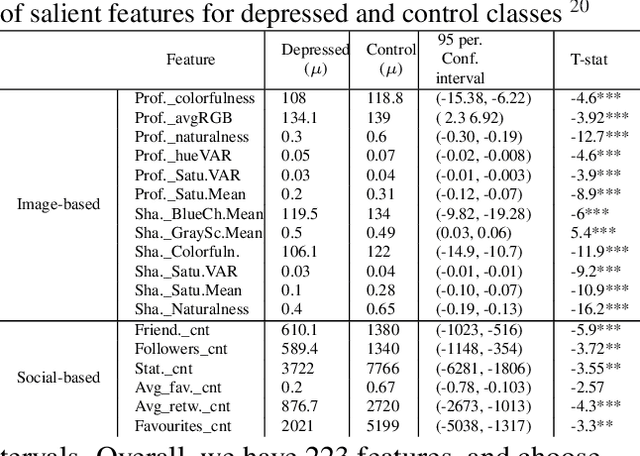
With ubiquity of social media platforms, millions of people are sharing their online persona by expressing their thoughts, moods, emotions, feelings, and even their daily struggles with mental health issues voluntarily and publicly on social media. Unlike the most existing efforts which study depression by analyzing textual content, we examine and exploit multimodal big data to discern depressive behavior using a wide variety of features including individual-level demographics. By developing a multimodal framework and employing statistical techniques for fusing heterogeneous sets of features obtained by processing visual, textual and user interaction data, we significantly enhance the current state-of-the-art approaches for identifying depressed individuals on Twitter (improving the average F1-Score by 5 percent) as well as facilitate demographic inference from social media for broader applications. Besides providing insights into the relationship between demographics and mental health, our research assists in the design of a new breed of demographic-aware health interventions.
Toward Sensor-based Sleep Monitoring with Electrodermal Activity Measures
Jan 31, 2019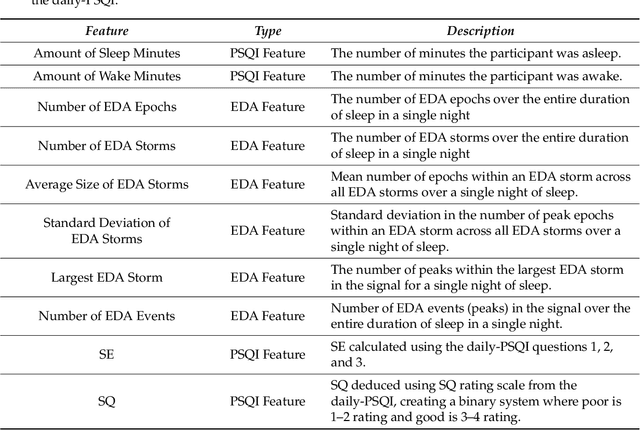
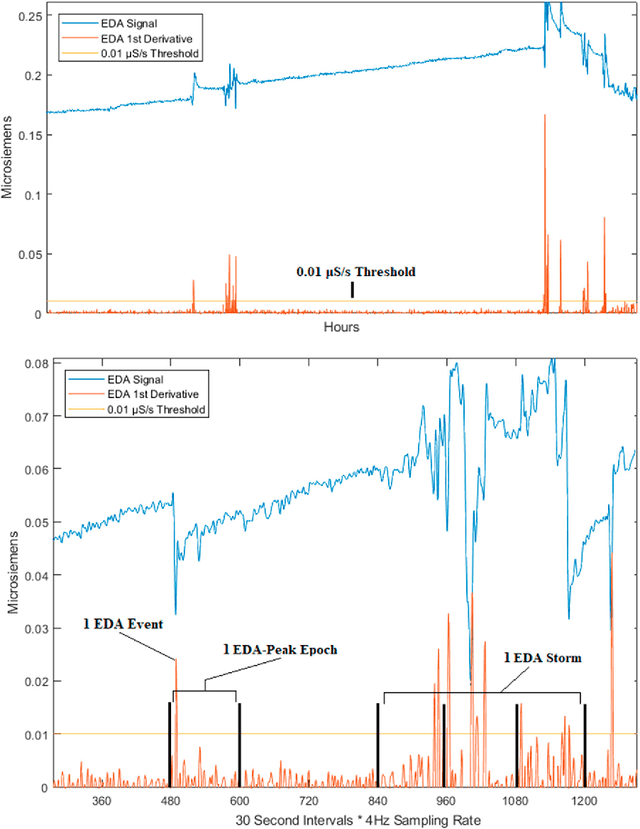
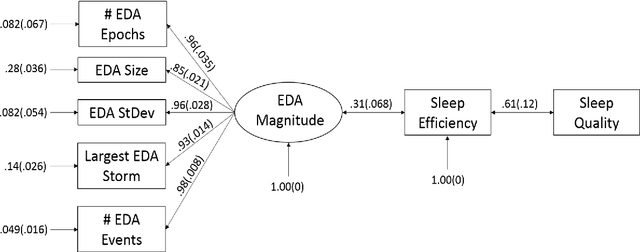
We use self-report and electrodermal activity (EDA) wearable sensor data from 77 nights of sleep on six participants to test the efficacy of EDA data for sleep monitoring. We used factor analysis to find latent factors in the EDA data, and causal model search to find the most probable graphical model accounting for self-reported sleep efficiency (SE), sleep quality (SQ), and the latent EDA factors. Structural equation modeling was used to confirm fit of the extracted graph. Based on the generated graph, logistic regression and naive Bayes models were used to test the efficacy of the EDA data in predicting SE and SQ. Six EDA features extracted from the total signal over a night's sleep could be explained by two latent factors, EDA Magnitude and EDA Storms. EDA Magnitude performed as a strong predictor for SE to aid detection of substantial changes in time asleep. The performance of EDA Magnitured and SE in classifying SQ showed promise for wearable sleep monitoring applications. However, our data suggest that obtaining a more accurate sensor-based measure of SE will be necessary before smaller changes in SQ can be detected from EDA sensor data alone.
Early Hospital Mortality Prediction using Vital Signals
Mar 18, 2018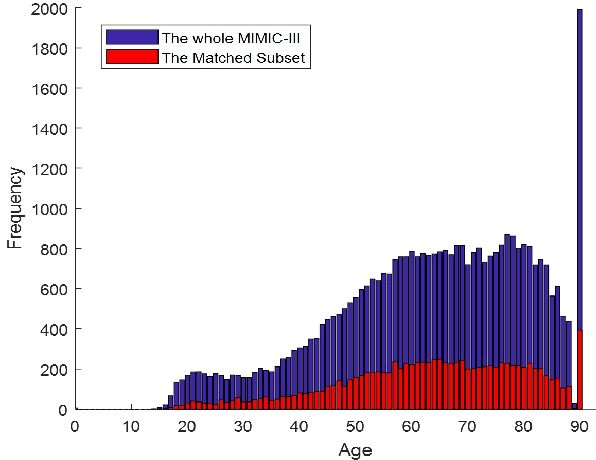
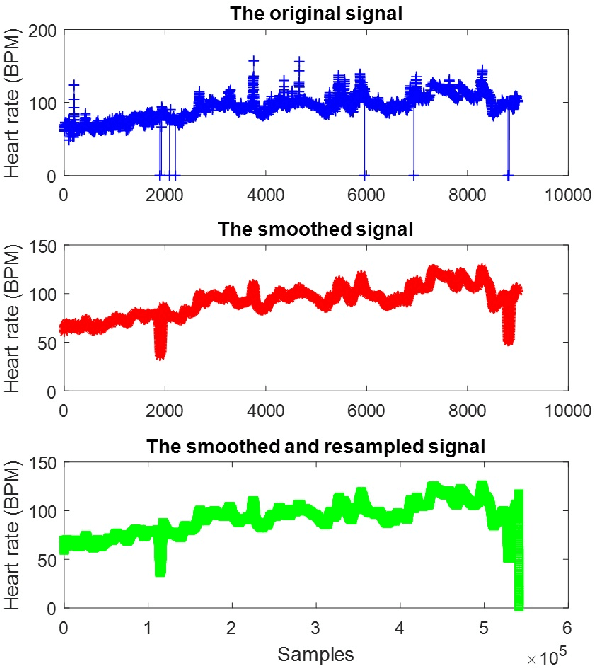
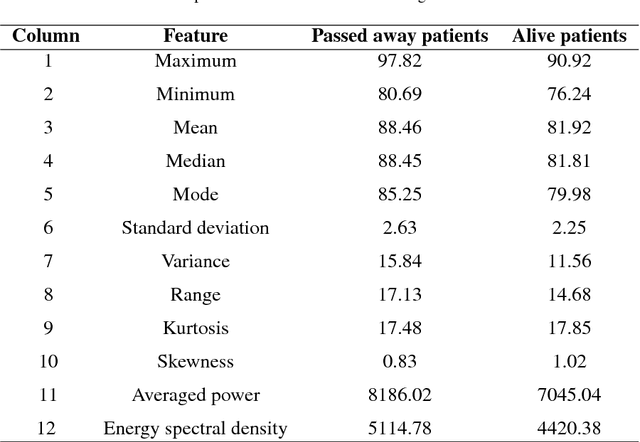
Early hospital mortality prediction is critical as intensivists strive to make efficient medical decisions about the severely ill patients staying in intensive care units. As a result, various methods have been developed to address this problem based on clinical records. However, some of the laboratory test results are time-consuming and need to be processed. In this paper, we propose a novel method to predict mortality using features extracted from the heart signals of patients within the first hour of ICU admission. In order to predict the risk, quantitative features have been computed based on the heart rate signals of ICU patients. Each signal is described in terms of 12 statistical and signal-based features. The extracted features are fed into eight classifiers: decision tree, linear discriminant, logistic regression, support vector machine (SVM), random forest, boosted trees, Gaussian SVM, and K-nearest neighborhood (K-NN). To derive insight into the performance of the proposed method, several experiments have been conducted using the well-known clinical dataset named Medical Information Mart for Intensive Care III (MIMIC-III). The experimental results demonstrate the capability of the proposed method in terms of precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC). The decision tree classifier satisfies both accuracy and interpretability better than the other classifiers, producing an F1-score and AUC equal to 0.91 and 0.93, respectively. It indicates that heart rate signals can be used for predicting mortality in patients in the ICU, achieving a comparable performance with existing predictions that rely on high dimensional features from clinical records which need to be processed and may contain missing information.