 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-Centered Data-Driven Planner-Actor-Critic Architecture via Logic Programming
Sep 18, 2019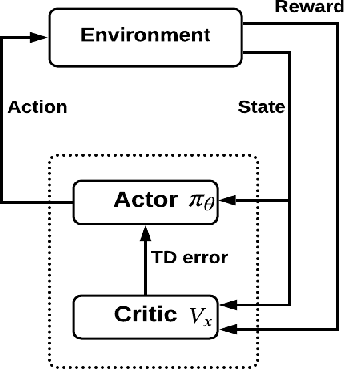
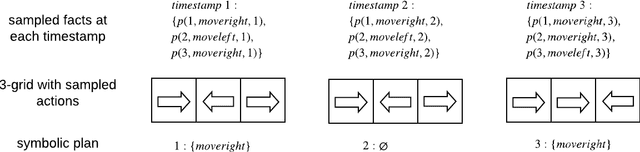
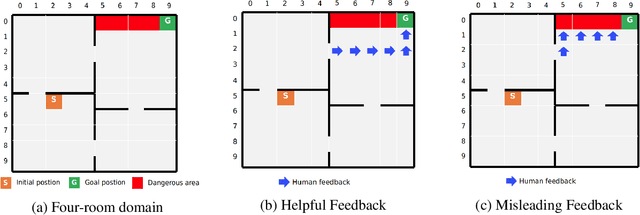
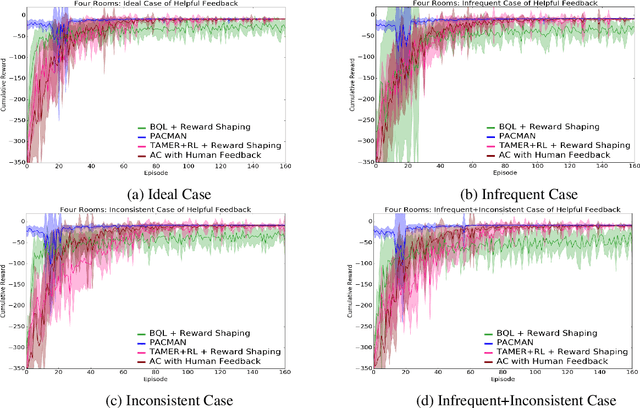
Recent successes of Reinforcement Learning (RL) allow an agent to learn policies that surpass human experts but suffers from being time-hungry and data-hungry. By contrast, human learning is significantly faster because prior and general knowledge and multiple information resources are utilized. In this paper, we propose a Planner-Actor-Critic architecture for huMAN-centered planning and learning (PACMAN), where an agent uses its prior, high-level, deterministic symbolic knowledge to plan for goal-directed actions, and also integrates the Actor-Critic algorithm of RL to fine-tune its behavior towards both environmental rewards and human feedback. This work is the first unified framework where knowledge-based planning, RL, and human teaching jointly contribute to the policy learning of an agent. Our experiments demonstrate that PACMAN leads to a significant jump-start at the early stage of learning, converges rapidly and with small variance, and is robust to inconsistent, infrequent, and misleading feedback.
* In Proceedings ICLP 2019, arXiv:1909.07646. arXiv admin note: significant text overlap with arXiv:1906.07268
PACMAN: A Planner-Actor-Critic Architecture for Human-Centered Planning and Learning
Aug 01, 2019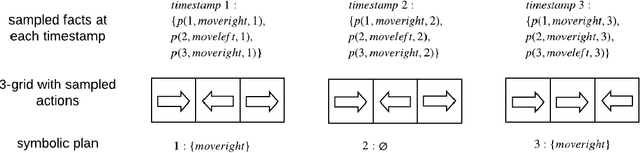
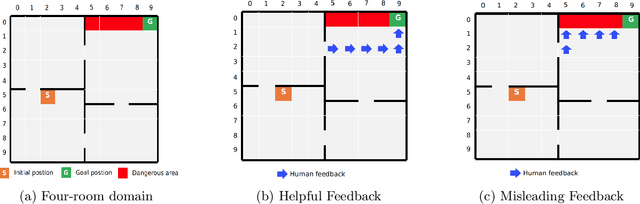
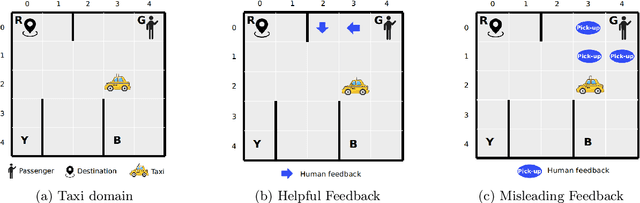
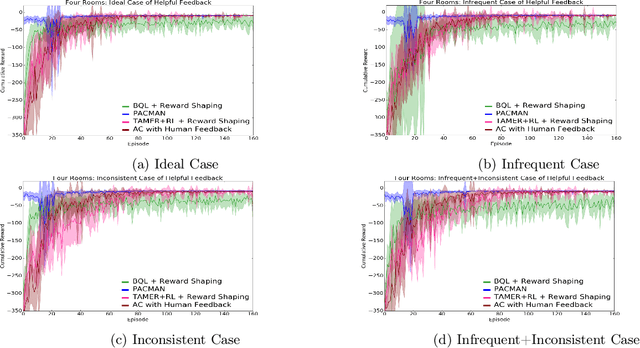
Conventional reinforcement learning (RL) allows an agent to learn policies via environmental rewards only, with a long and slow learning curve at the beginning stage. On the contrary, human learning is usually much faster because prior and general knowledge and multiple information resources are utilized. In this paper, we propose a \textbf{P}lanner-\textbf{A}ctor-\textbf{C}ritic architecture for hu\textbf{MAN}-centered planning and learning (\textbf{PACMAN}), where an agent uses its prior, high-level, deterministic symbolic knowledge to plan for goal-directed actions, while integrates Actor-Critic algorithm of RL to fine-tune its behaviors towards both environmental rewards and human feedback. This is the first unified framework where knowledge-based planning, RL, and human teaching jointly contribute to the policy learning of an agent. Our experiments demonstrate that PACMAN leads to a significant jump start at the early stage of learning, converges rapidly and with small variance, and is robust to inconsistent, infrequent and misleading feedback.
Interpretable Automated Machine Learning in Maana(TM) Knowledge Platform
May 06, 2019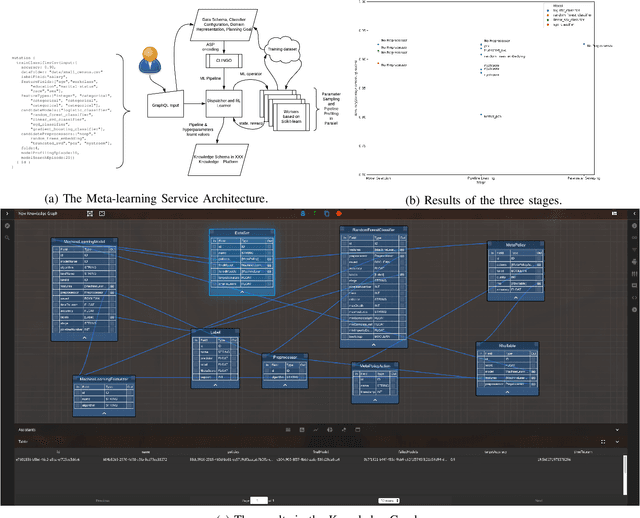

Machine learning is becoming an essential part of developing solutions for many industrial applications, but the lack of interpretability hinders wide industry adoption to rapidly build, test, deploy and validate machine learning models, in the sense that the insight of developing machine learning solutions are not structurally encoded, justified and transferred. In this paper we describe Maana Meta-learning Service, an interpretable and interactive automated machine learning service residing in Maana Knowledge Platform that performs machine-guided, user assisted pipeline search and hyper-parameter tuning and generates structured knowledge about decisions for pipeline profiling and selection. The service is shipped with Maana Knowledge Platform and is validated using benchmark dataset. Furthermore, its capability of deriving knowledge from pipeline search facilitates various inference tasks and transferring to similar data science projects.
SDRL: Interpretable and Data-efficient Deep Reinforcement Learning Leveraging Symbolic Planning
Nov 05, 2018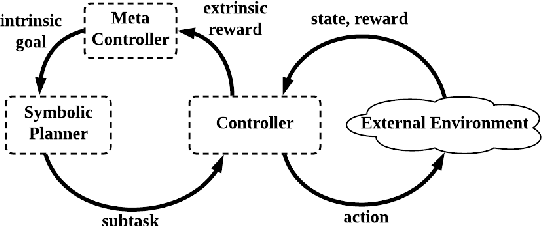

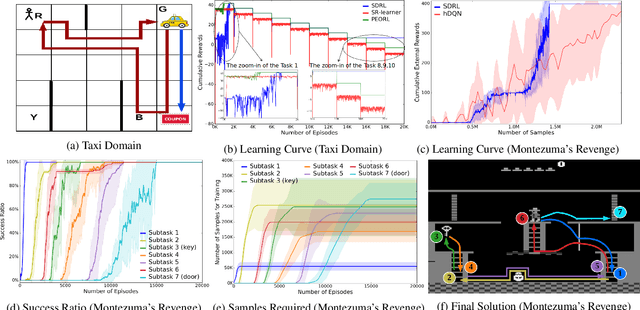
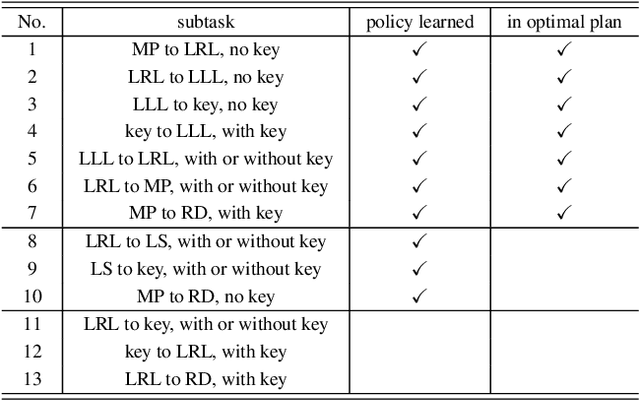
Deep reinforcement learning (DRL) has gained great success by learning directly from high-dimensional sensory inputs, yet is notorious for the lack of interpretability. Interpretability of the subtasks is critical in hierarchical decision-making as it increases the transparency of black-box-style DRL approach and helps the RL practitioners to understand the high-level behavior of the system better. In this paper, we introduce symbolic planning into DRL and propose a framework of Symbolic Deep Reinforcement Learning (SDRL) that can handle both high-dimensional sensory inputs and symbolic planning. The task-level interpretability is enabled by relating symbolic actions to options.This framework features a planner -- controller -- meta-controller architecture, which takes charge of subtask scheduling, data-driven subtask learning, and subtask evaluation, respectively. The three components cross-fertilize each other and eventually converge to an optimal symbolic plan along with the learned subtasks, bringing together the advantages of long-term planning capability with symbolic knowledge and end-to-end reinforcement learning directly from a high-dimensional sensory input. Experimental results validate the interpretability of subtasks, along with improved data efficiency compared with state-of-the-art approaches.
A Practical Incremental Learning Framework For Sparse Entity Extraction
Jun 26, 2018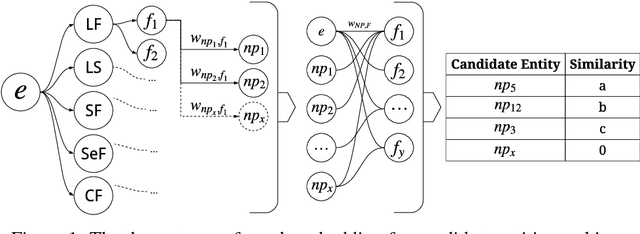
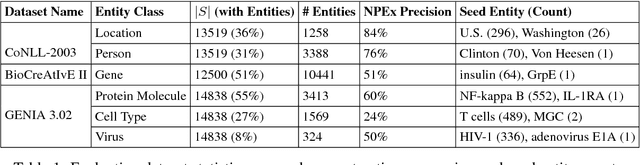
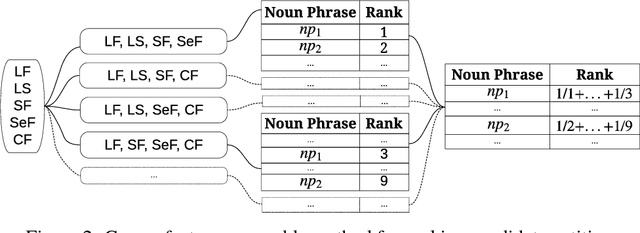
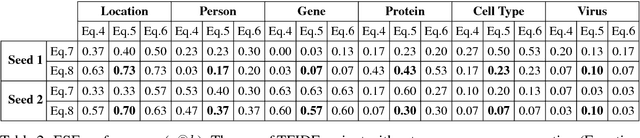
This work addresses challenges arising from extracting entities from textual data, including the high cost of data annotation, model accuracy, selecting appropriate evaluation criteria, and the overall quality of annotation. We present a framework that integrates Entity Set Expansion (ESE) and Active Learning (AL) to reduce the annotation cost of sparse data and provide an online evaluation method as feedback. This incremental and interactive learning framework allows for rapid annotation and subsequent extraction of sparse data while maintaining high accuracy. We evaluate our framework on three publicly available datasets and show that it drastically reduces the cost of sparse entity annotation by an average of 85% and 45% to reach 0.9 and 1.0 F-Scores respectively. Moreover, the method exhibited robust performance across all datasets.
PEORL: Integrating Symbolic Planning and Hierarchical Reinforcement Learning for Robust Decision-Making
Jun 05, 2018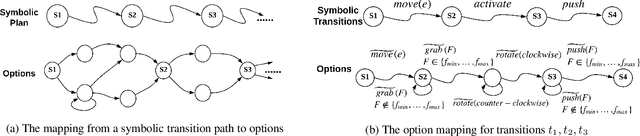
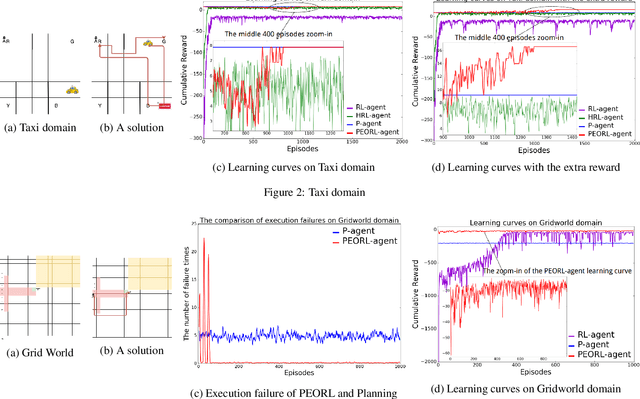
Reinforcement learning and symbolic planning have both been used to build intelligent autonomous agents. Reinforcement learning relies on learning from interactions with real world, which often requires an unfeasibly large amount of experience. Symbolic planning relies on manually crafted symbolic knowledge, which may not be robust to domain uncertainties and changes. In this paper we present a unified framework {\em PEORL} that integrates symbolic planning with hierarchical reinforcement learning (HRL) to cope with decision-making in a dynamic environment with uncertainties. Symbolic plans are used to guide the agent's task execution and learning, and the learned experience is fed back to symbolic knowledge to improve planning. This method leads to rapid policy search and robust symbolic plans in complex domains. The framework is tested on benchmark domains of HRL.