 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACMAN: A Planner-Actor-Critic Architecture for Human-Centered Planning and Learning
Paper and Code
Aug 01, 2019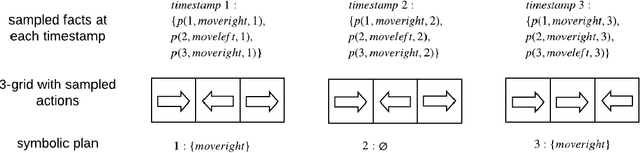
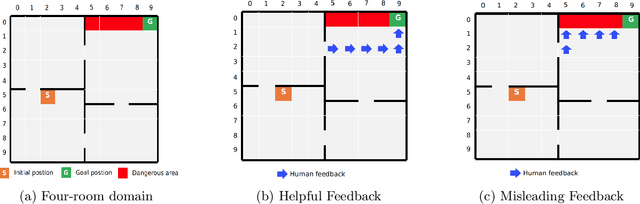
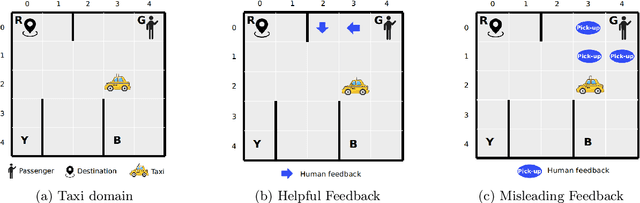
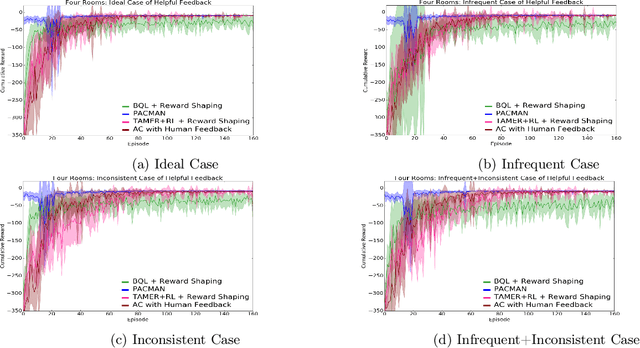
Conventional reinforcement learning (RL) allows an agent to learn policies via environmental rewards only, with a long and slow learning curve at the beginning stage. On the contrary, human learning is usually much faster because prior and general knowledge and multiple information resources are utilized. In this paper, we propose a \textbf{P}lanner-\textbf{A}ctor-\textbf{C}ritic architecture for hu\textbf{MAN}-centered planning and learning (\textbf{PACMAN}), where an agent uses its prior, high-level, deterministic symbolic knowledge to plan for goal-directed actions, while integrates Actor-Critic algorithm of RL to fine-tune its behaviors towards both environmental rewards and human feedback. This is the first unified framework where knowledge-based planning, RL, and human teaching jointly contribute to the policy learning of an agent. Our experiments demonstrate that PACMAN leads to a significant jump start at the early stage of learning, converges rapidly and with small variance, and is robust to inconsistent, infrequent and misleading feedback.