 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Islamist Extremist Communications on Social Media using Contextual Dimensions: Religion, Ideology, and Hate
Paper and Code
Aug 20, 2019
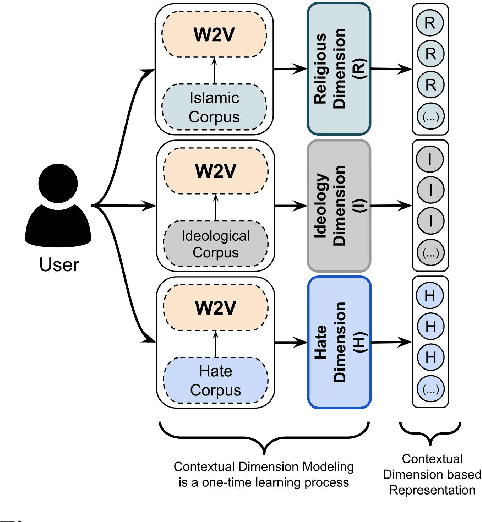
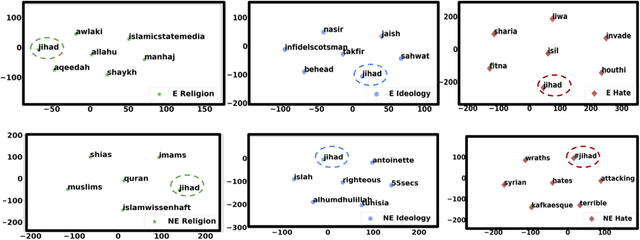
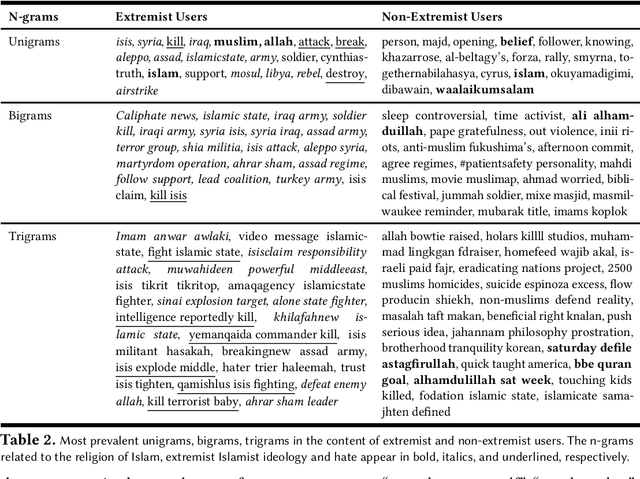
Terror attacks have been linked in part to online extremist content. Although tens of thousands of Islamist extremism supporters consume such content, they are a small fraction relative to peaceful Muslims. The efforts to contain the ever-evolving extremism on social media platforms have remained inadequate and mostly ineffective. Divergent extremist and mainstream contexts challenge machine interpretation, with a particular threat to the precision of classification algorithms. Our context-aware computational approach to the analysis of extremist content on Twitter breaks down this persuasion process into building blocks that acknowledge inherent ambiguity and sparsity that likely challenge both manual and automated classification. We model this process using a combination of three contextual dimensions -- religion, ideology, and hate -- each elucidating a degree of radicalization and highlighting independent features to render them computationally accessible. We utilize domain-specific knowledge resources for each of these contextual dimensions such as Qur'an for religion, the books of extremist ideologues and preachers for political ideology and a social media hate speech corpus for hate. Our study makes three contributions to reliable analysis: (i) Development of a computational approach rooted in the contextual dimensions of religion, ideology, and hate that reflects strategies employed by online Islamist extremist groups, (ii) An in-depth analysis of relevant tweet datasets with respect to these dimensions to exclude likely mislabeled users, and (iii) A framework for understanding online radicalization as a process to assist counter-programming. Given the potentially significant social impact, we evaluate the performance of our algorithms to minimize mislabeling, where our approach outperforms a competitive baseline by 10.2% in precision.