 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation Intelligence: Towards a New Generation of Scientific Methods
Dec 06, 2021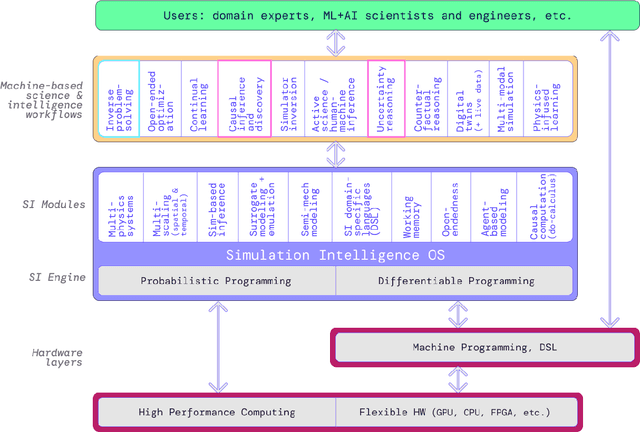
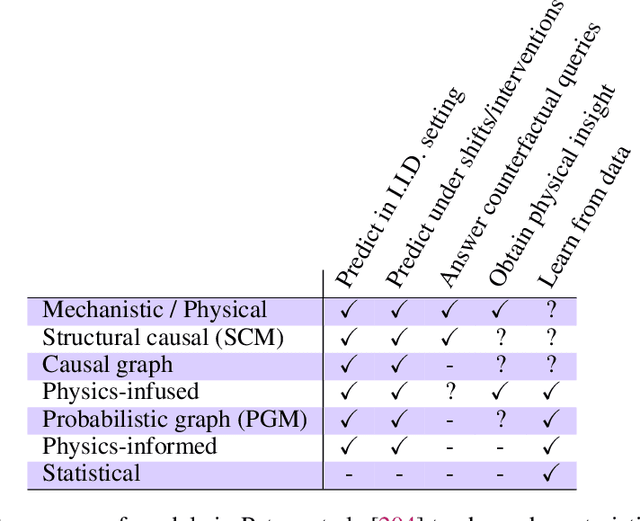
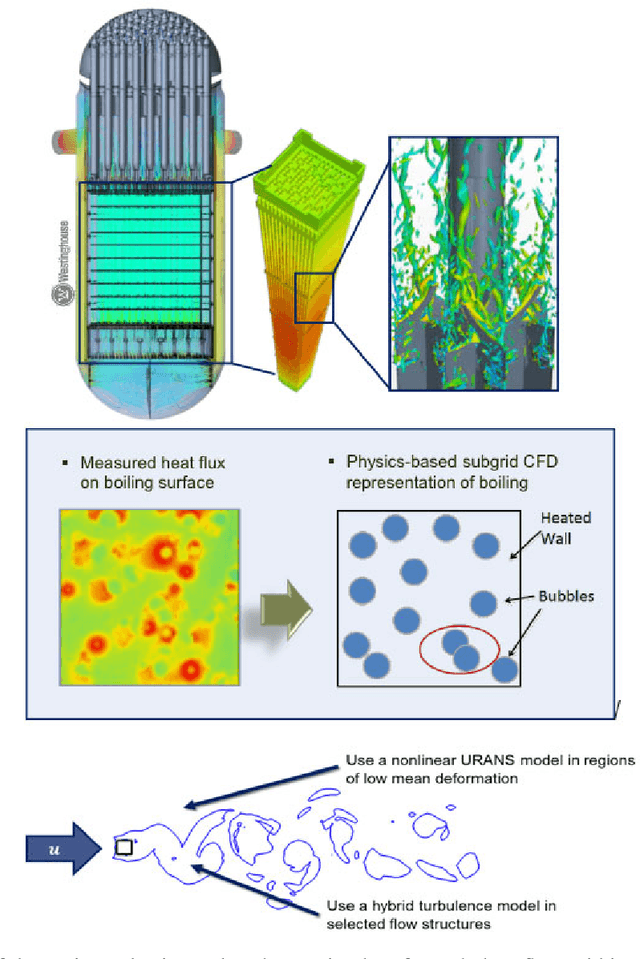
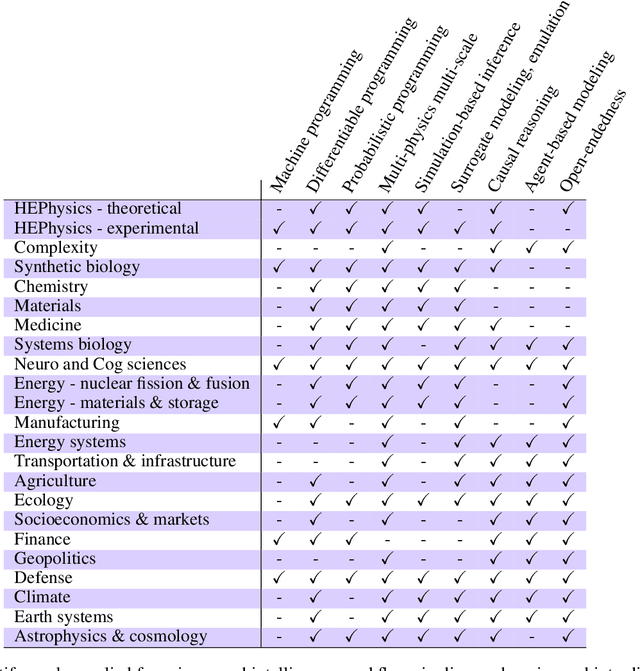
The original "Seven Motifs" set forth a roadmap of essential methods for the field of scientific computing, where a motif is an algorithmic method that captures a pattern of computation and data movement. We present the "Nine Motifs of Simulation Intelligence", a roadmap for the development and integration of the essential algorithms necessary for a merger of scientific computing, scientific simulation, and artificial intelligence. We call this merger simulation intelligence (SI), for short. We argue the motifs of simulation intelligence are interconnected and interdependent, much like the components within the layers of an operating system. Using this metaphor, we explore the nature of each layer of the simulation intelligence operating system stack (SI-stack) and the motifs therein: (1) Multi-physics and multi-scale modeling; (2) Surrogate modeling and emulation; (3) Simulation-based inference; (4) Causal modeling and inference; (5) Agent-based modeling; (6) Probabilistic programming; (7) Differentiable programming; (8) Open-ended optimization; (9) Machine programming. We believe coordinated efforts between motifs offers immense opportunity to accelerate scientific discovery, from solving inverse problems in synthetic biology and climate science, to directing nuclear energy experiments and predicting emergent behavior in socioeconomic settings. We elaborate on each layer of the SI-stack, detailing the state-of-art methods, presenting examples to highlight challenges and opportunities, and advocating for specific ways to advance the motifs and the synergies from their combinations. Advancing and integrating these technologies can enable a robust and efficient hypothesis-simulation-analysis type of scientific method, which we introduce with several use-cases for human-machine teaming and automated science.
Tradeoffs in Streaming Binary Classification under Limited Inspection Resources
Oct 05, 2021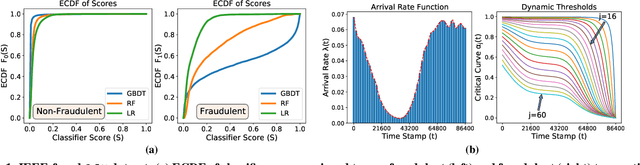
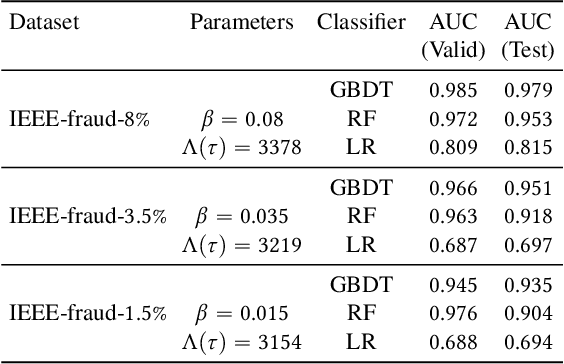
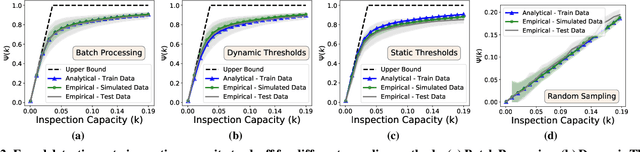
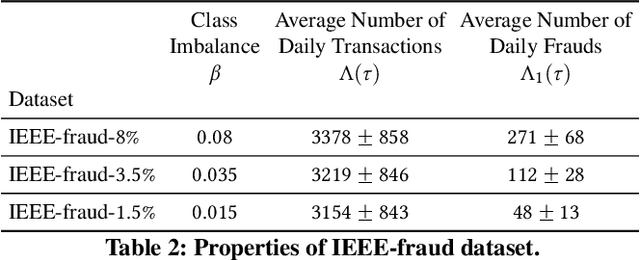
Institutions are increasingly relying on machine learning models to identify and alert on abnormal events, such as fraud, cyber attacks and system failures. These alerts often need to be manually investigated by specialists. Given the operational cost of manual inspections, the suspicious events are selected by alerting systems with carefully designed thresholds. In this paper, we consider an imbalanced binary classification problem, where events arrive sequentially and only a limited number of suspicious events can be inspected. We model the event arrivals as a non-homogeneous Poisson process, and compare various suspicious event selection methods including those based on static and adaptive thresholds. For each method, we analytically characterize the tradeoff between the minority-class detection rate and the inspection capacity as a function of the data class imbalance and the classifier confidence score densities. We implement the selection methods on a real public fraud detection dataset and compare the empirical results with analytical bounds. Finally, we investigate how class imbalance and the choice of classifier impact the tradeoff.
Non-Parametric Stochastic Sequential Assignment With Random Arrival Times
Jun 09, 2021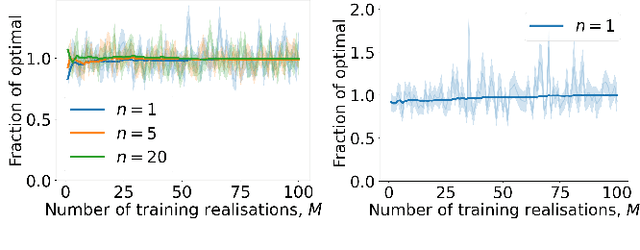

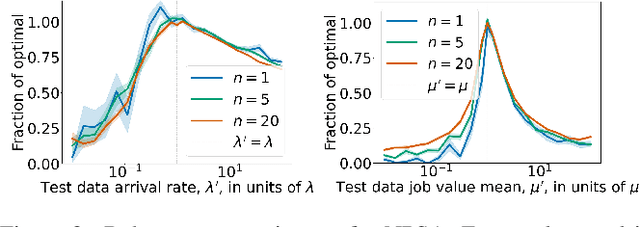

We consider a problem wherein jobs arrive at random times and assume random values. Upon each job arrival, the decision-maker must decide immediately whether or not to accept the job and gain the value on offer as a reward, with the constraint that they may only accept at most $n$ jobs over some reference time period. The decision-maker only has access to $M$ independent realisations of the job arrival process. We propose an algorithm, Non-Parametric Sequential Allocation (NPSA), for solving this problem. Moreover, we prove that the expected reward returned by the NPSA algorithm converges in probability to optimality as $M$ grows large. We demonstrate the effectiveness of the algorithm empirically on synthetic data and on public fraud-detection datasets, from where the motivation for this work is derived.
Copula Flows for Synthetic Data Generation
Jan 03, 2021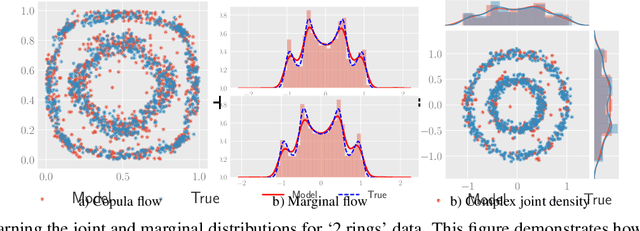
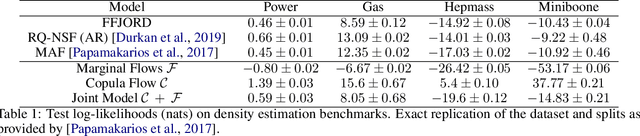
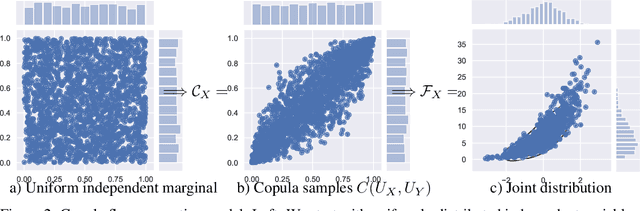
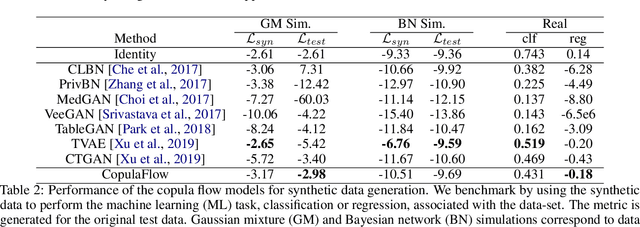
The ability to generate high-fidelity synthetic data is crucial when available (real) data is limited or where privacy and data protection standards allow only for limited use of the given data, e.g., in medical and financial data-sets. Current state-of-the-art methods for synthetic data generation are based on generative models, such as Generative Adversarial Networks (GANs). Even though GANs have achieved remarkable results in synthetic data generation, they are often challenging to interpret.Furthermore, GAN-based methods can suffer when used with mixed real and categorical variables.Moreover, loss function (discriminator loss) design itself is problem specific, i.e., the generative model may not be useful for tasks it was not explicitly trained for. In this paper, we propose to use a probabilistic model as a synthetic data generator. Learning the probabilistic model for the data is equivalent to estimating the density of the data. Based on the copula theory, we divide the density estimation task into two parts, i.e., estimating univariate marginals and estimating the multivariate copula density over the univariate marginals. We use normalising flows to learn both the copula density and univariate marginals. We benchmark our method on both simulated and real data-sets in terms of density estimation as well as the ability to generate high-fidelity synthetic data
SURF: Improving classifiers in production by learning from busy and noisy end users
Oct 12, 2020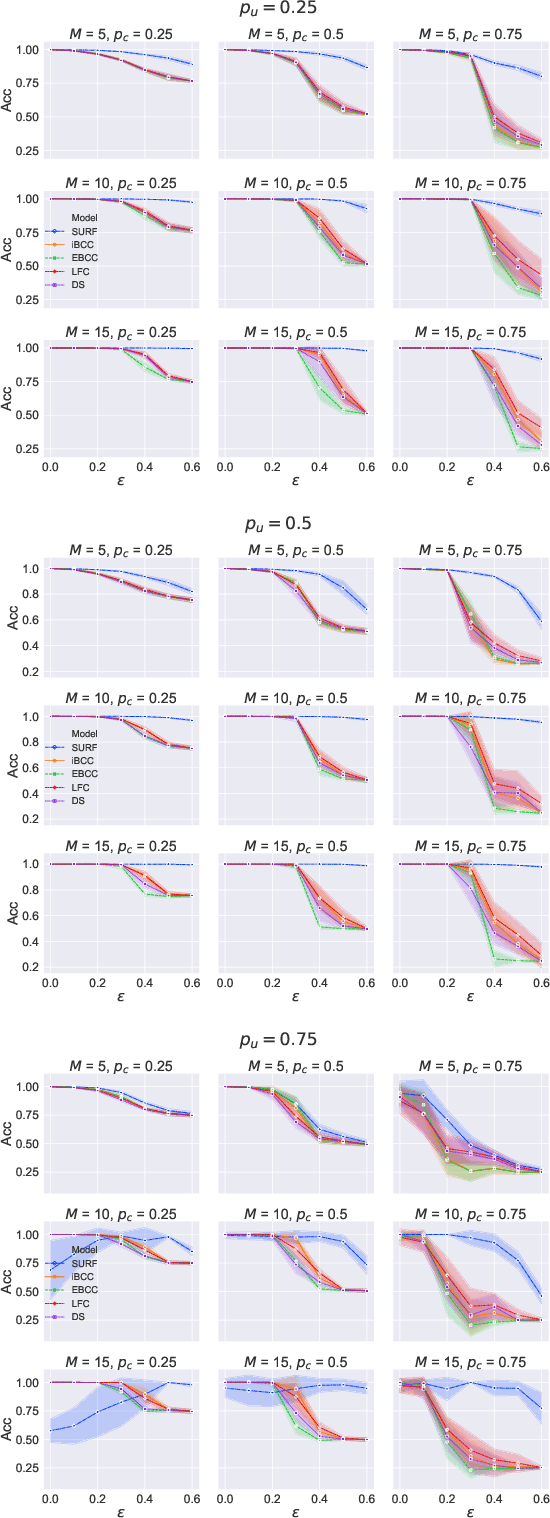
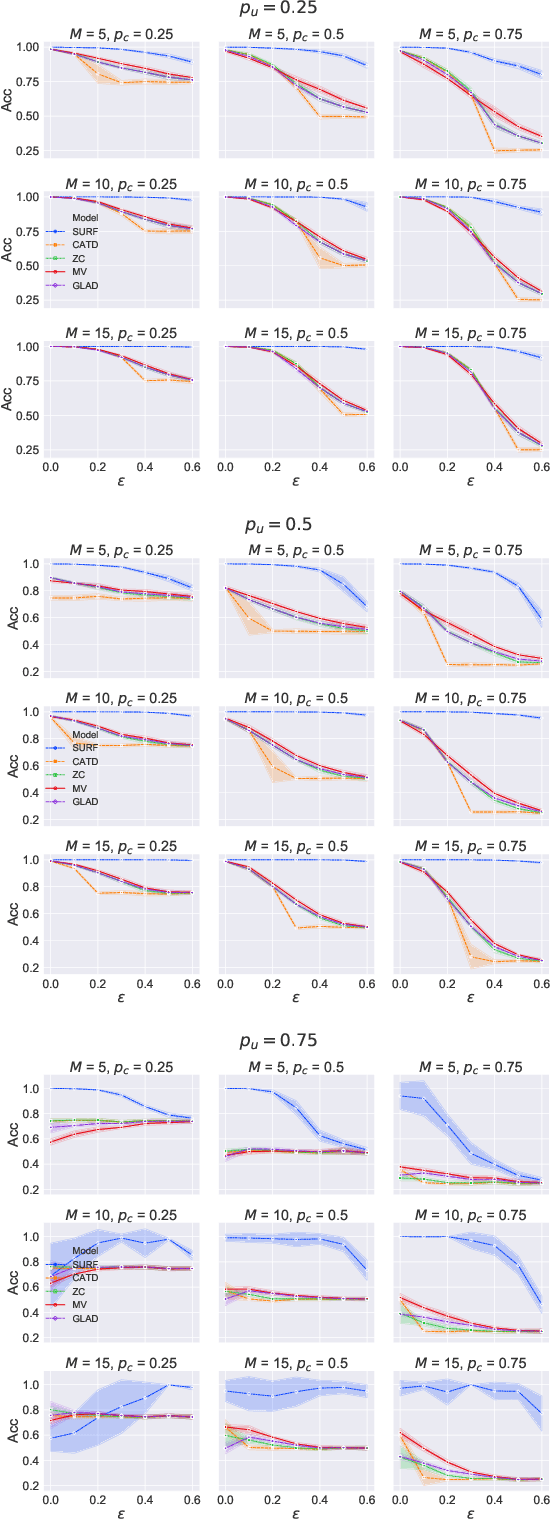
Supervised learning classifiers inevitably make mistakes in production, perhaps mis-labeling an email, or flagging an otherwise routine transaction as fraudulent. It is vital that the end users of such a system are provided with a means of relabeling data points that they deem to have been mislabeled. The classifier can then be retrained on the relabeled data points in the hope of performance improvement. To reduce noise in this feedback data, well known algorithms from the crowdsourcing literature can be employed. However, the feedback setting provides a new challenge: how do we know what to do in the case of user non-response? If a user provides us with no feedback on a label then it can be dangerous to assume they implicitly agree: a user can be busy, lazy, or no longer a user of the system! We show that conventional crowdsourcing algorithms struggle in this user feedback setting, and present a new algorithm, SURF, that can cope with this non-response ambiguity.
Some people aren't worth listening to: periodically retraining classifiers with feedback from a team of end users
Apr 27, 2020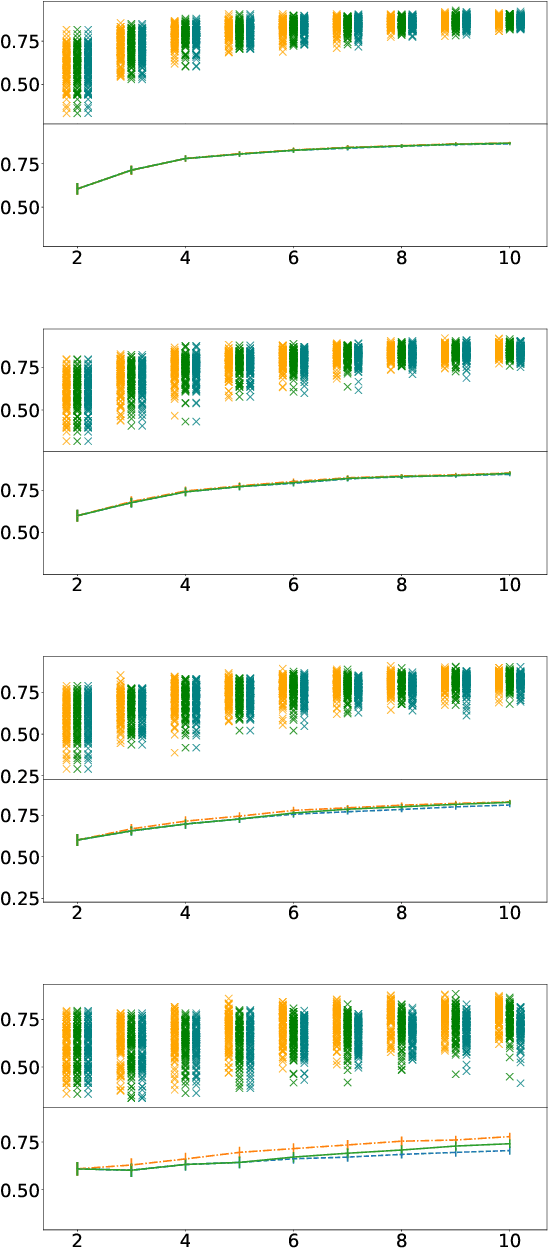
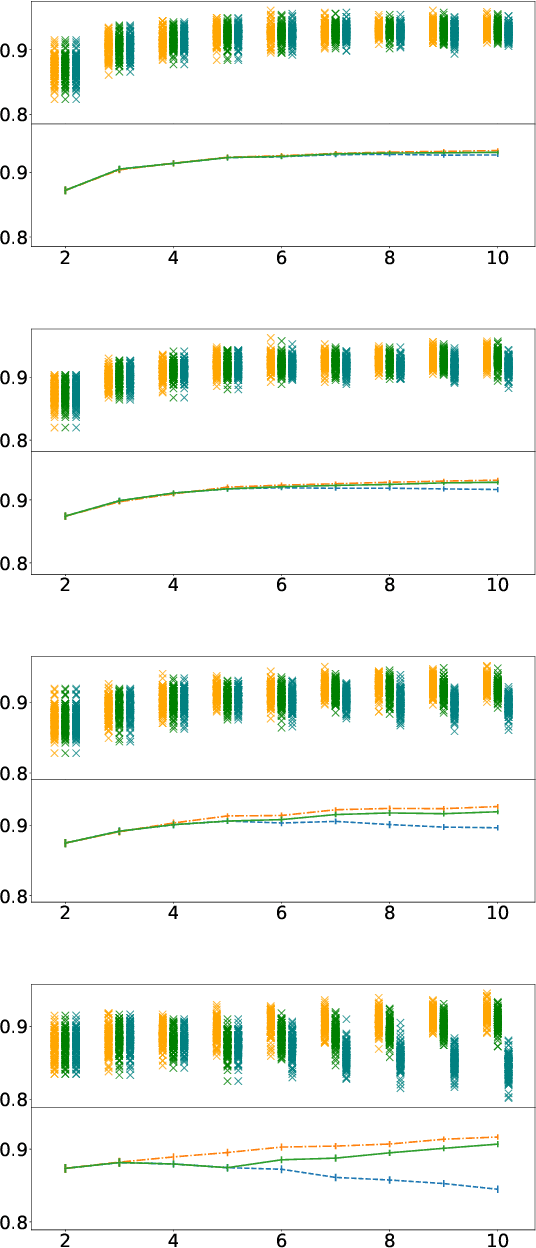
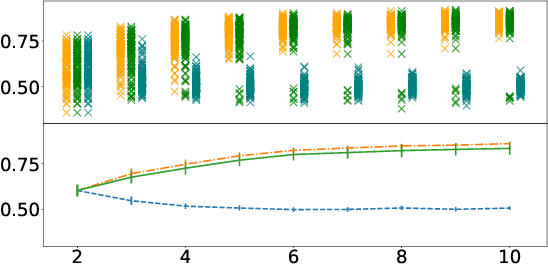
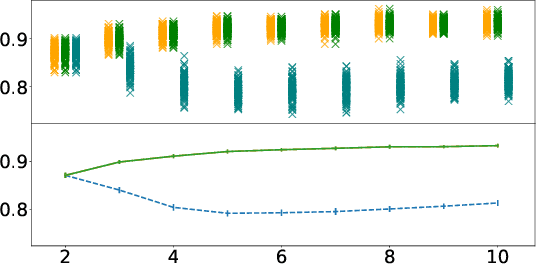
Document classification is ubiquitous in a business setting, but often the end users of a classifier are engaged in an ongoing feedback-retrain loop with the team that maintain it. We consider this feedback-retrain loop from a multi-agent point of view, considering the end users as autonomous agents that provide feedback on the labelled data provided by the classifier. This allows us to examine the effect on the classifier's performance of unreliable end users who provide incorrect feedback. We demonstrate a classifier that can learn which users tend to be unreliable, filtering their feedback out of the loop, thus improving performance in subsequent iterations.