 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Data Mapping of Online Hate Speech, Misinformation, and General Mental Health: A Large Language Model Based Study
Sep 22, 2023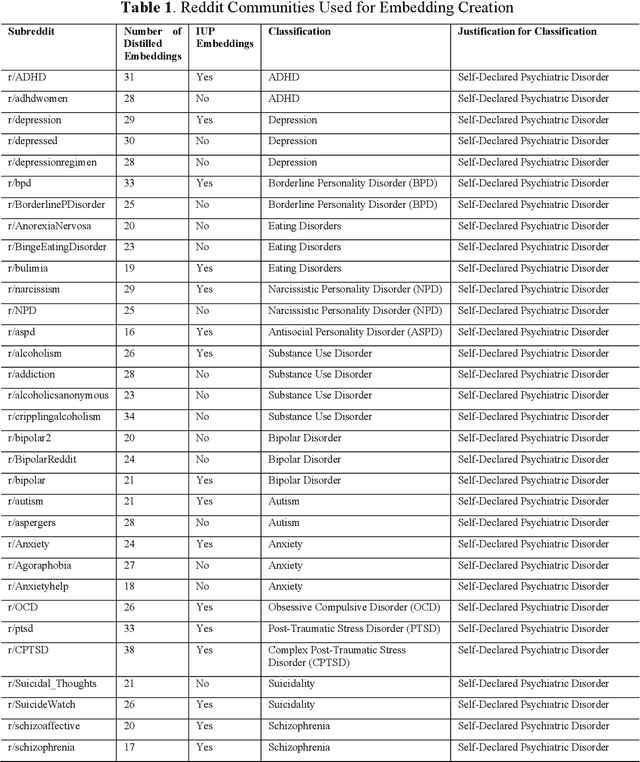
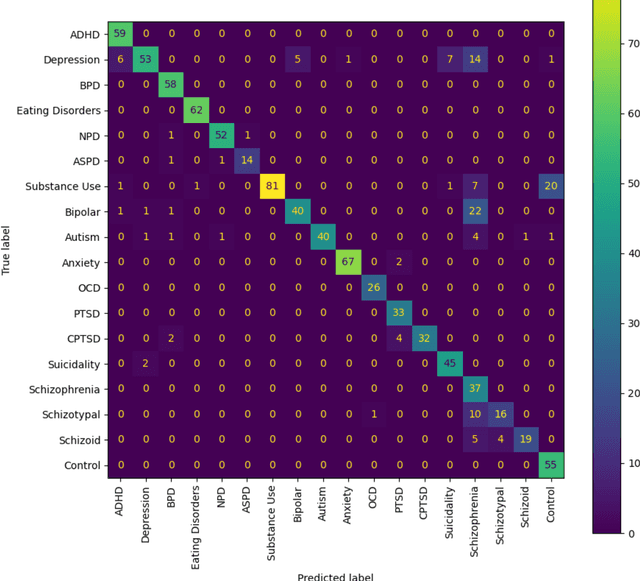
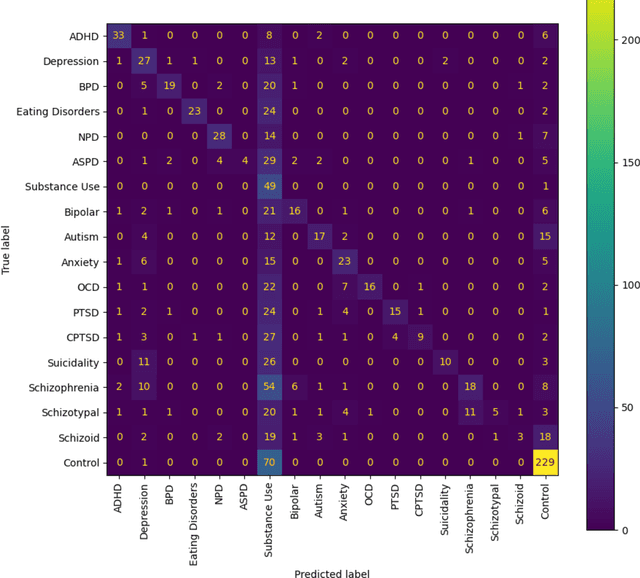
The advent of social media has led to an increased concern over its potential to propagate hate speech and misinformation, which, in addition to contributing to prejudice and discrimination, has been suspected of playing a role in increasing social violence and crimes in the United States. While literature has shown the existence of an association between posting hate speech and misinformation online and certain personality traits of posters, the general relationship and relevance of online hate speech/misinformation in the context of overall psychological wellbeing of posters remain elusive. One difficulty lies in the lack of adequate data analytics tools capable of adequately analyzing the massive amount of social media posts to uncover the underlying hidden links. Recent progresses in machine learning and large language models such as ChatGPT have made such an analysis possible. In this study, we collected thousands of posts from carefully selected communities on the social media site Reddit. We then utilized OpenAI's GPT3 to derive embeddings of these posts, which are high-dimensional real-numbered vectors that presumably represent the hidden semantics of posts. We then performed various machine-learning classifications based on these embeddings in order to understand the role of hate speech/misinformation in various communities. Finally, a topological data analysis (TDA) was applied to the embeddings to obtain a visual map connecting online hate speech, misinformation, various psychiatric disorders, and general mental health.
SURF: Improving classifiers in production by learning from busy and noisy end users
Oct 12, 2020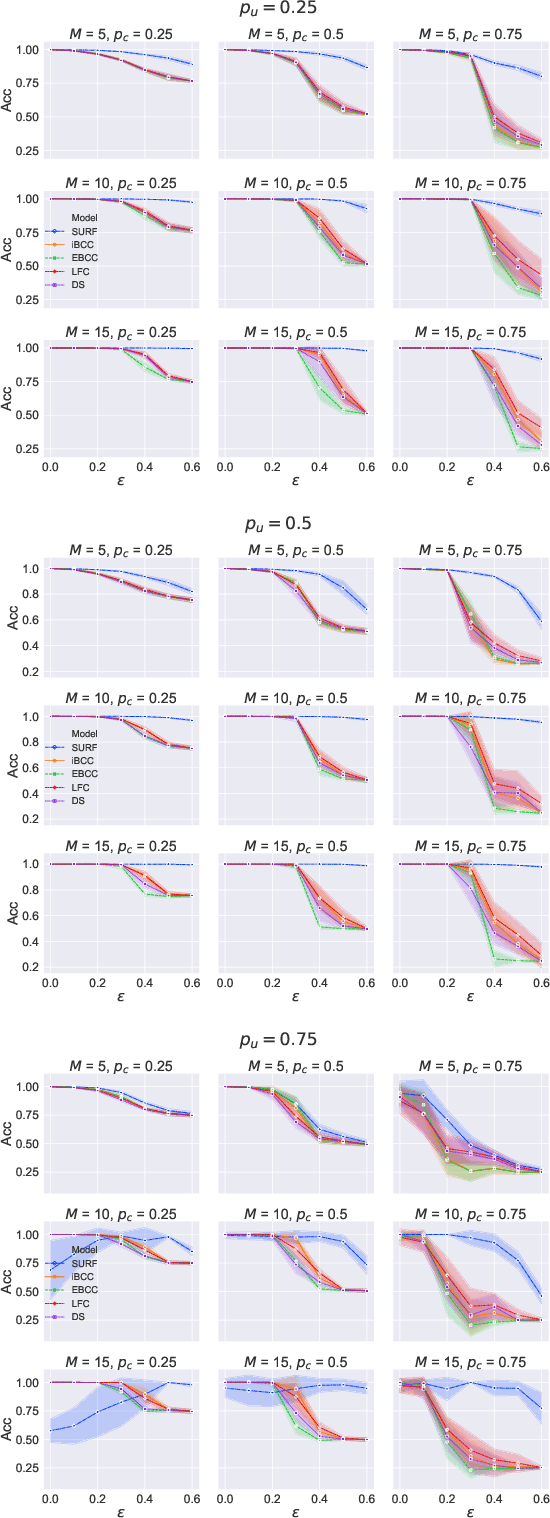
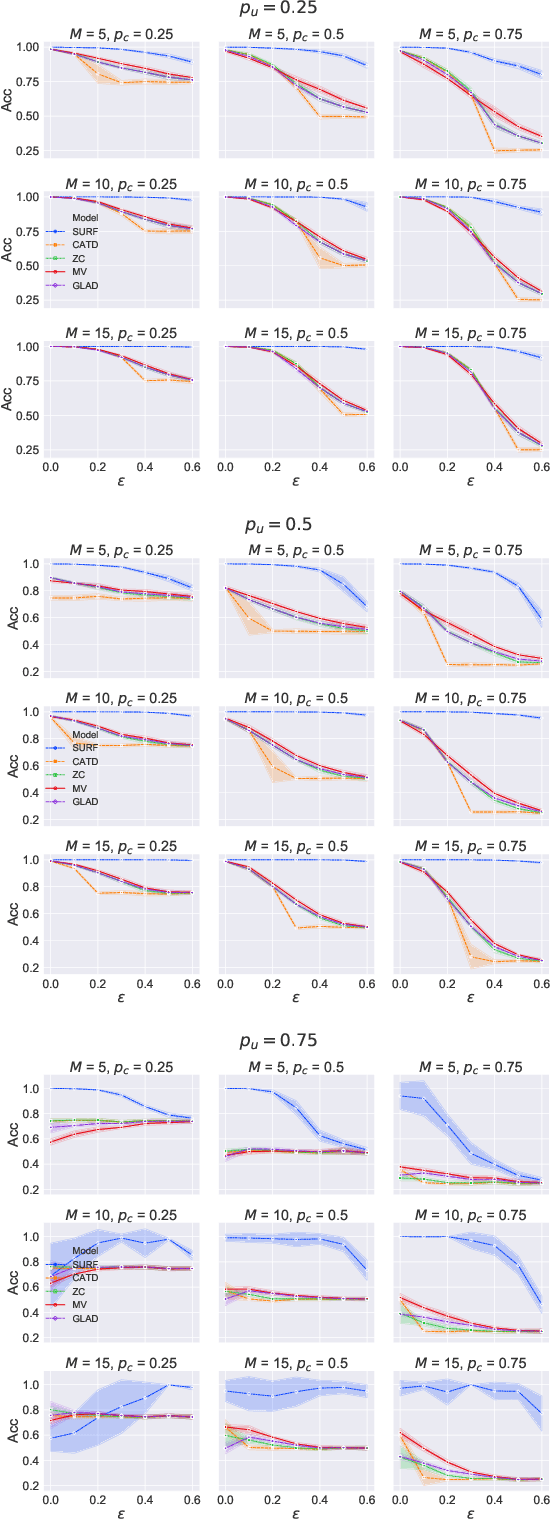
Supervised learning classifiers inevitably make mistakes in production, perhaps mis-labeling an email, or flagging an otherwise routine transaction as fraudulent. It is vital that the end users of such a system are provided with a means of relabeling data points that they deem to have been mislabeled. The classifier can then be retrained on the relabeled data points in the hope of performance improvement. To reduce noise in this feedback data, well known algorithms from the crowdsourcing literature can be employed. However, the feedback setting provides a new challenge: how do we know what to do in the case of user non-response? If a user provides us with no feedback on a label then it can be dangerous to assume they implicitly agree: a user can be busy, lazy, or no longer a user of the system! We show that conventional crowdsourcing algorithms struggle in this user feedback setting, and present a new algorithm, SURF, that can cope with this non-response ambiguity.