 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regularized Actor-Critic Algorithm for Bi-Level Reinforcement Learning
Jan 26, 2026We study a structured bi-level optimization problem where the upper-level objective is a smooth function and the lower-level problem is policy optimization in a Markov decision process (MDP). The upper-level decision variable parameterizes the reward of the lower-level MDP, and the upper-level objective depends on the optimal induced policy. Existing methods for bi-level optimization and RL often require second-order information, impose strong regularization at the lower level, or inefficiently use samples through nested-loop procedures. In this work, we propose a single-loop, first-order actor-critic algorithm that optimizes the bi-level objective via a penalty-based reformulation. We introduce into the lower-level RL objective an attenuating entropy regularization, which enables asymptotically unbiased upper-level hyper-gradient estimation without solving the unregularized RL problem exactly. We establish the finite-time and finite-sample convergence of the proposed algorithm to a stationary point of the original, unregularized bi-level optimization problem through a novel lower-level residual analysis under a special type of Polyak-Lojasiewicz condition. We validate the performance of our method through experiments on a GridWorld goal position problem and on happy tweet generation through reinforcement learning from human feedback (RLHF).
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Learning in Stackelberg Mean Field Games: A Non-Asymptotic Analysis
Sep 18, 2025We study policy optimization in Stackelberg mean field games (MFGs), a hierarchical framework for modeling the strategic interaction between a single leader and an infinitely large population of homogeneous followers. The objective can be formulated as a structured bi-level optimization problem, in which the leader needs to learn a policy maximizing its reward, anticipating the response of the followers. Existing methods for solving these (and related) problems often rely on restrictive independence assumptions between the leader's and followers' objectives, use samples inefficiently due to nested-loop algorithm structure, and lack finite-time convergence guarantees. To address these limitations, we propose AC-SMFG, a single-loop actor-critic algorithm that operates on continuously generated Markovian samples. The algorithm alternates between (semi-)gradient updates for the leader, a representative follower, and the mean field, and is simple to implement in practice. We establish the finite-time and finite-sample convergence of the algorithm to a stationary point of the Stackelberg objective. To our knowledge, this is the first Stackelberg MFG algorithm with non-asymptotic convergence guarantees. Our key assumption is a "gradient alignment" condition, which requires that the full policy gradient of the leader can be approximated by a partial component of it, relaxing the existing leader-follower independence assumption. Simulation results in a range of well-established economics environments demonstrate that AC-SMFG outperforms existing multi-agent and MFG learning baselines in policy quality and convergence speed.
Accelerating Multi-Task Temporal Difference Learning under Low-Rank Representation
Mar 03, 2025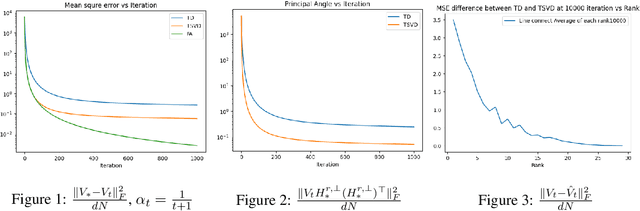
We study policy evaluation problems in multi-task reinforcement learning (RL) under a low-rank representation setting. In this setting, we are given $N$ learning tasks where the corresponding value function of these tasks lie in an $r$-dimensional subspace, with $r<N$. One can apply the classic temporal-difference (TD) learning method for solving these problems where this method learns the value function of each task independently. In this paper, we are interested in understanding whether one can exploit the low-rank structure of the multi-task setting to accelerate the performance of TD learning. To answer this question, we propose a new variant of TD learning method, where we integrate the so-called truncated singular value decomposition step into the update of TD learning. This additional step will enable TD learning to exploit the dominant directions due to the low rank structure to update the iterates, therefore, improving its performance. Our empirical results show that the proposed method significantly outperforms the classic TD learning, where the performance gap increases as the rank $r$ decreases. From the theoretical point of view, introducing the truncated singular value decomposition step into TD learning might cause an instability on the updates. We provide a theoretical result showing that the instability does not happen. Specifically, we prove that the proposed method converges at a rate $\mathcal{O}(\frac{\ln(t)}{t})$, where $t$ is the number of iterations. This rate matches that of the standard TD learning.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
ADAGE: A generic two-layer framework for adaptive agent based modelling
Jan 16, 2025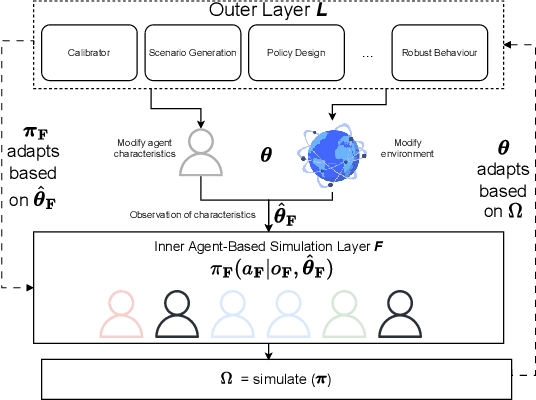


Agent-based models (ABMs) are valuable for modelling complex, potentially out-of-equilibria scenarios. However, ABMs have long suffered from the Lucas critique, stating that agent behaviour should adapt to environmental changes. Furthermore, the environment itself often adapts to these behavioural changes, creating a complex bi-level adaptation problem. Recent progress integrating multi-agent reinforcement learning into ABMs introduces adaptive agent behaviour, beginning to address the first part of this critique, however, the approaches are still relatively ad hoc, lacking a general formulation, and furthermore, do not tackle the second aspect of simultaneously adapting environmental level characteristics in addition to the agent behaviours. In this work, we develop a generic two-layer framework for ADaptive AGEnt based modelling (ADAGE) for addressing these problems. This framework formalises the bi-level problem as a Stackelberg game with conditional behavioural policies, providing a consolidated framework for adaptive agent-based modelling based on solving a coupled set of non-linear equations. We demonstrate how this generic approach encapsulates several common (previously viewed as distinct) ABM tasks, such as policy design, calibration, scenario generation, and robust behavioural learning under one unified framework. We provide example simulations on multiple complex economic and financial environments, showing the strength of the novel framework under these canonical settings, addressing long-standing critiques of traditional ABMs.
Regularized Proportional Fairness Mechanism for Resource Allocation Without Money
Jan 02, 2025



Mechanism design in resource allocation studies dividing limited resources among self-interested agents whose satisfaction with the allocation depends on privately held utilities. We consider the problem in a payment-free setting, with the aim of maximizing social welfare while enforcing incentive compatibility (IC), i.e., agents cannot inflate allocations by misreporting their utilities. The well-known proportional fairness (PF) mechanism achieves the maximum possible social welfare but incurs an undesirably high exploitability (the maximum unilateral inflation in utility from misreport and a measure of deviation from IC). In fact, it is known that no mechanism can achieve the maximum social welfare and exact incentive compatibility (IC) simultaneously without the use of monetary incentives (Cole et al., 2013). Motivated by this fact, we propose learning an approximate mechanism that desirably trades off the competing objectives. Our main contribution is to design an innovative neural network architecture tailored to the resource allocation problem, which we name Regularized Proportional Fairness Network (RPF-Net). RPF-Net regularizes the output of the PF mechanism by a learned function approximator of the most exploitable allocation, with the aim of reducing the incentive for any agent to misreport. We derive generalization bounds that guarantee the mechanism performance when trained under finite and out-of-distribution samples and experimentally demonstrate the merits of the proposed mechanism compared to the state-of-the-art.
Approximate Equivariance in Reinforcement Learning
Nov 06, 2024Equivariant neural networks have shown great success in reinforcement learning, improving sample efficiency and generalization when there is symmetry in the task. However, in many problems, only approximate symmetry is present, which makes imposing exact symmetry inappropriate. Recently, approximately equivariant networks have been proposed for supervised classification and modeling physical systems. In this work, we develop approximately equivariant algorithms in reinforcement learning (RL). We define approximately equivariant MDPs and theoretically characterize the effect of approximate equivariance on the optimal Q function. We propose novel RL architectures using relaxed group convolutions and experiment on several continuous control domains and stock trading with real financial data. Our results demonstrate that approximate equivariance matches prior work when exact symmetries are present, and outperforms them when domains exhibit approximate symmetry. As an added byproduct of these techniques, we observe increased robustness to noise at test time.
Partially Observable Contextual Bandits with Linear Payoffs
Sep 17, 2024The standard contextual bandit framework assumes fully observable and actionable contexts. In this work, we consider a new bandit setting with partially observable, correlated contexts and linear payoffs, motivated by the applications in finance where decision making is based on market information that typically displays temporal correlation and is not fully observed. We make the following contributions marrying ideas from statistical signal processing with bandits: (i) We propose an algorithmic pipeline named EMKF-Bandit, which integrates system identification, filtering, and classic contextual bandit algorithms into an iterative method alternating between latent parameter estimation and decision making. (ii) We analyze EMKF-Bandit when we select Thompson sampling as the bandit algorithm and show that it incurs a sub-linear regret under conditions on filtering. (iii) We conduct numerical simulations that demonstrate the benefits and practical applicability of the proposed pipeline.
Fast Two-Time-Scale Stochastic Gradient Method with Applications in Reinforcement Learning
May 15, 2024

Two-time-scale optimization is a framework introduced in Zeng et al. (2024) that abstracts a range of policy evaluation and policy optimization problems in reinforcement learning (RL). Akin to bi-level optimization under a particular type of stochastic oracle, the two-time-scale optimization framework has an upper level objective whose gradient evaluation depends on the solution of a lower level problem, which is to find the root of a strongly monotone operator. In this work, we propose a new method for solving two-time-scale optimization that achieves significantly faster convergence than the prior arts. The key idea of our approach is to leverage an averaging step to improve the estimates of the operators in both lower and upper levels before using them to update the decision variables. These additional averaging steps eliminate the direct coupling between the main variables, enabling the accelerated performance of our algorithm. We characterize the finite-time convergence rates of the proposed algorithm under various conditions of the underlying objective function, including strong convexity, convexity, Polyak-Lojasiewicz condition, and general non-convexity. These rates significantly improve over the best-known complexity of the standard two-time-scale stochastic approximation algorithm. When applied to RL, we show how the proposed algorithm specializes to novel online sample-based methods that surpass or match the performance of the existing state of the art. Finally, we support our theoretical results with numerical simulations in RL.