 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Stackelberg Mean Field Games: A Non-Asymptotic Analysis
Sep 18, 2025We study policy optimization in Stackelberg mean field games (MFGs), a hierarchical framework for modeling the strategic interaction between a single leader and an infinitely large population of homogeneous followers. The objective can be formulated as a structured bi-level optimization problem, in which the leader needs to learn a policy maximizing its reward, anticipating the response of the followers. Existing methods for solving these (and related) problems often rely on restrictive independence assumptions between the leader's and followers' objectives, use samples inefficiently due to nested-loop algorithm structure, and lack finite-time convergence guarantees. To address these limitations, we propose AC-SMFG, a single-loop actor-critic algorithm that operates on continuously generated Markovian samples. The algorithm alternates between (semi-)gradient updates for the leader, a representative follower, and the mean field, and is simple to implement in practice. We establish the finite-time and finite-sample convergence of the algorithm to a stationary point of the Stackelberg objective. To our knowledge, this is the first Stackelberg MFG algorithm with non-asymptotic convergence guarantees. Our key assumption is a "gradient alignment" condition, which requires that the full policy gradient of the leader can be approximated by a partial component of it, relaxing the existing leader-follower independence assumption. Simulation results in a range of well-established economics environments demonstrate that AC-SMFG outperforms existing multi-agent and MFG learning baselines in policy quality and convergence speed.
ADAGE: A generic two-layer framework for adaptive agent based modelling
Jan 16, 2025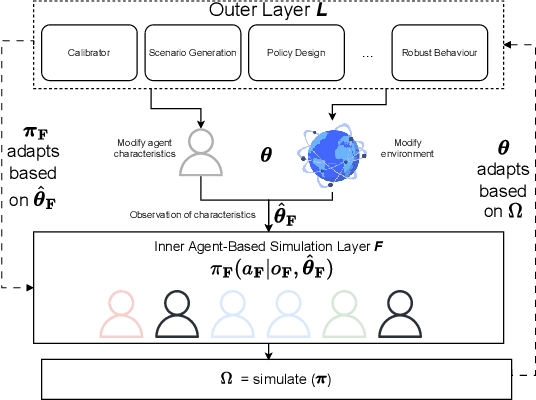


Agent-based models (ABMs) are valuable for modelling complex, potentially out-of-equilibria scenarios. However, ABMs have long suffered from the Lucas critique, stating that agent behaviour should adapt to environmental changes. Furthermore, the environment itself often adapts to these behavioural changes, creating a complex bi-level adaptation problem. Recent progress integrating multi-agent reinforcement learning into ABMs introduces adaptive agent behaviour, beginning to address the first part of this critique, however, the approaches are still relatively ad hoc, lacking a general formulation, and furthermore, do not tackle the second aspect of simultaneously adapting environmental level characteristics in addition to the agent behaviours. In this work, we develop a generic two-layer framework for ADaptive AGEnt based modelling (ADAGE) for addressing these problems. This framework formalises the bi-level problem as a Stackelberg game with conditional behavioural policies, providing a consolidated framework for adaptive agent-based modelling based on solving a coupled set of non-linear equations. We demonstrate how this generic approach encapsulates several common (previously viewed as distinct) ABM tasks, such as policy design, calibration, scenario generation, and robust behavioural learning under one unified framework. We provide example simulations on multiple complex economic and financial environments, showing the strength of the novel framework under these canonical settings, addressing long-standing critiques of traditional ABMs.
Simulate and Optimise: A two-layer mortgage simulator for designing novel mortgage assistance products
Nov 01, 2024



We develop a novel two-layer approach for optimising mortgage relief products through a simulated multi-agent mortgage environment. While the approach is generic, here the environment is calibrated to the US mortgage market based on publicly available census data and regulatory guidelines. Through the simulation layer, we assess the resilience of households to exogenous income shocks, while the optimisation layer explores strategies to improve the robustness of households to these shocks by making novel mortgage assistance products available to households. Households in the simulation are adaptive, learning to make mortgage-related decisions (such as product enrolment or strategic foreclosures) that maximize their utility, balancing their available liquidity and equity. We show how this novel two-layer simulation approach can successfully design novel mortgage assistance products to improve household resilience to exogenous shocks, and balance the costs of providing such products through post-hoc analysis. Previously, such analysis could only be conducted through expensive pilot studies involving real participants, demonstrating the benefit of the approach for designing and evaluating financial products.
Learning and Calibrating Heterogeneous Bounded Rational Market Behaviour with Multi-Agent Reinforcement Learning
Feb 01, 2024Agent-based models (ABMs) have shown promise for modelling various real world phenomena incompatible with traditional equilibrium analysis. However, a critical concern is the manual definition of behavioural rules in ABMs. Recent developments in multi-agent reinforcement learning (MARL) offer a way to address this issue from an optimisation perspective, where agents strive to maximise their utility, eliminating the need for manual rule specification. This learning-focused approach aligns with established economic and financial models through the use of rational utility-maximising agents. However, this representation departs from the fundamental motivation for ABMs: that realistic dynamics emerging from bounded rationality and agent heterogeneity can be modelled. To resolve this apparent disparity between the two approaches, we propose a novel technique for representing heterogeneous processing-constrained agents within a MARL framework. The proposed approach treats agents as constrained optimisers with varying degrees of strategic skills, permitting departure from strict utility maximisation. Behaviour is learnt through repeated simulations with policy gradients to adjust action likelihoods. To allow efficient computation, we use parameterised shared policy learning with distributions of agent skill levels. Shared policy learning avoids the need for agents to learn individual policies yet still enables a spectrum of bounded rational behaviours. We validate our model's effectiveness using real-world data on a range of canonical $n$-agent settings, demonstrating significantly improved predictive capability.
Bounded rationality for relaxing best response and mutual consistency: An information-theoretic model of partial self-reference
Jun 30, 2021
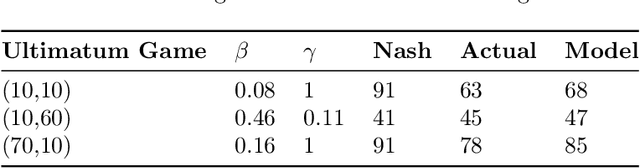

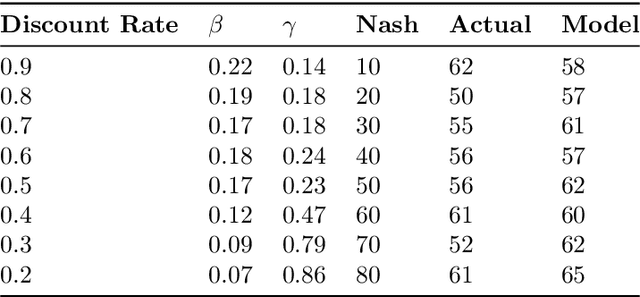
While game theory has been transformative for decision-making, the assumptions made can be overly restrictive in certain instances. In this work, we focus on some of the assumptions underlying rationality such as mutual consistency and best-response, and consider ways to relax these assumptions using concepts from level-$k$ reasoning and quantal response equilibrium (QRE) respectively. Specifically, we provide an information-theoretic two-parameter model that can relax both mutual consistency and best-response, but can recover approximations of level-$k$, QRE, or typical Nash equilibrium behaviour in the limiting cases. The proposed approach is based on a recursive form of the variational free energy principle, representing self-referential games as (pseudo) sequential decisions. Bounds in player processing abilities are captured as information costs, where future chains of reasoning are discounted, implying a hierarchy of players where lower-level players have fewer processing resources.
A maximum entropy model of bounded rational decision-making with prior beliefs and market feedback
Feb 18, 2021

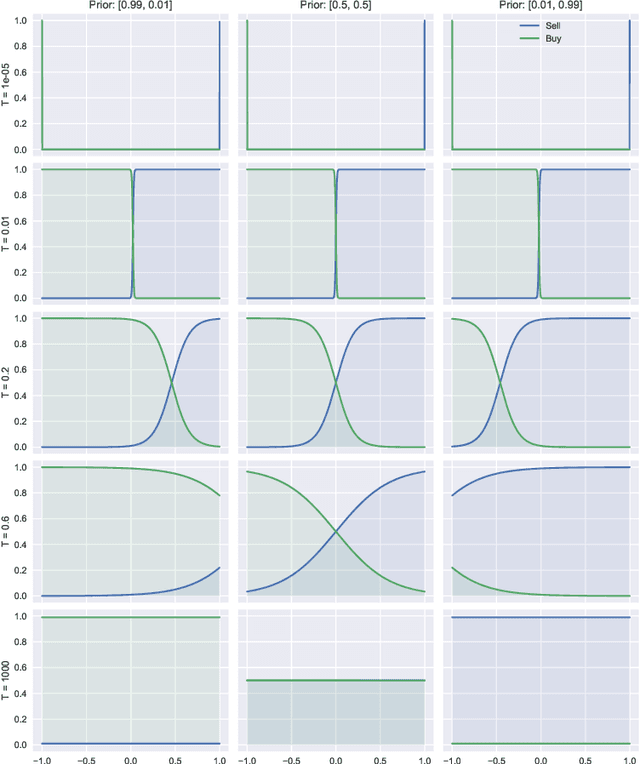
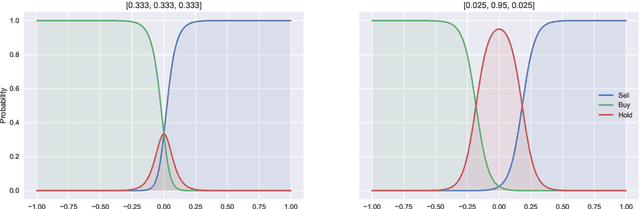
Bounded rationality is an important consideration stemming from the fact that agents often have limits on their processing abilities, making the assumption of perfect rationality inapplicable to many real tasks. We propose an information-theoretic approach to the inference of agent decisions under Smithian competition. The model explicitly captures the boundedness of agents (limited in their information-processing capacity) as the cost of information acquisition for expanding their prior beliefs. The expansion is measured as the Kullblack-Leibler divergence between posterior decisions and prior beliefs. When information acquisition is free, the \textit{homo economicus} agent is recovered, while in cases when information acquisition becomes costly, agents instead revert to their prior beliefs. The maximum entropy principle is used to infer least-biased decisions, based upon the notion of Smithian competition formalised within the Quantal Response Statistical Equilibrium framework. The incorporation of prior beliefs into such a framework allowed us to systematically explore the effects of prior beliefs on decision-making, in the presence of market feedback. We verified the proposed model using Australian housing market data, showing how the incorporation of prior knowledge alters the resulting agent decisions. Specifically, it allowed for the separation (and analysis) of past beliefs and utility maximisation behaviour of the agent.
An Adaptive and Near Parameter-free Evolutionary Computation Approach Towards True Automation in AutoML
Jan 28, 2020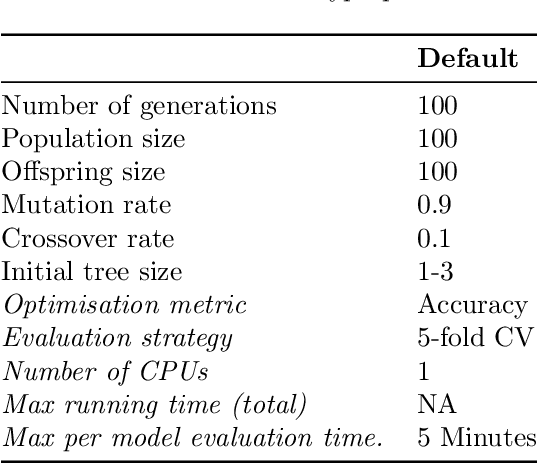


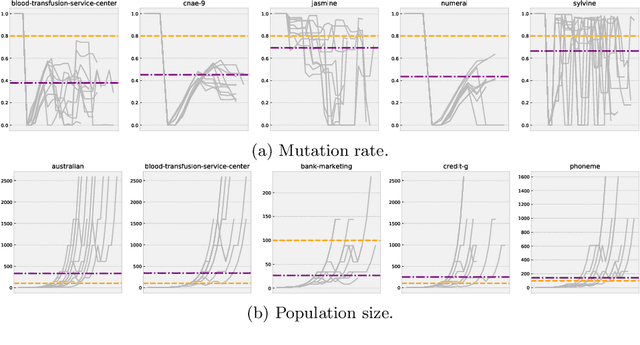
A common claim of evolutionary computation methods is that they can achieve good results without the need for human intervention. However, one criticism of this is that there are still hyperparameters which must be tuned in order to achieve good performance. In this work, we propose a near "parameter-free" genetic programming approach, which adapts the hyperparameter values throughout evolution without ever needing to be specified manually. We apply this to the area of automated machine learning (by extending TPOT), to produce pipelines which can effectively be claimed to be free from human input, and show that the results are competitive with existing state-of-the-art which use hand-selected hyperparameter values. Pipelines begin with a randomly chosen estimator and evolve to competitive pipelines automatically. This work moves towards a truly automatic approach to AutoML.
Improving generalisation of AutoML systems with dynamic fitness evaluations
Jan 23, 2020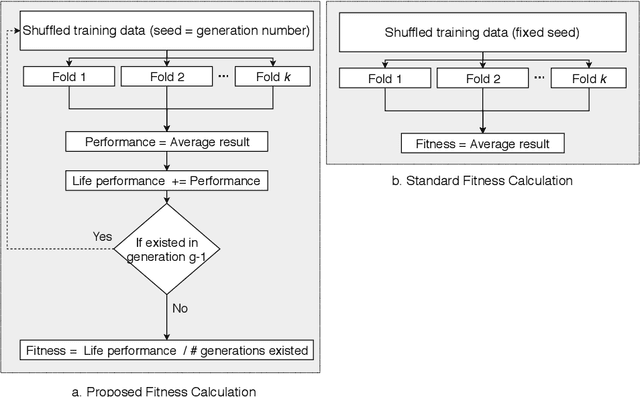


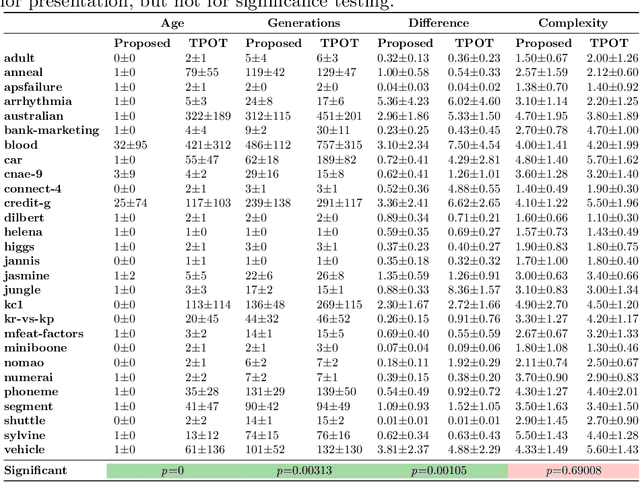
A common problem machine learning developers are faced with is overfitting, that is, fitting a pipeline too closely to the training data that the performance degrades for unseen data. Automated machine learning aims to free (or at least ease) the developer from the burden of pipeline creation, but this overfitting problem can persist. In fact, this can become more of a problem as we look to iteratively optimise the performance of an internal cross-validation (most often \textit{k}-fold). While this internal cross-validation hopes to reduce this overfitting, we show we can still risk overfitting to the particular folds used. In this work, we aim to remedy this problem by introducing dynamic fitness evaluations which approximate repeated \textit{k}-fold cross-validation, at little extra cost over single \textit{k}-fold, and far lower cost than typical repeated \textit{k}-fold. The results show that when time equated, the proposed fitness function results in significant improvement over the current state-of-the-art baseline method which uses an internal single \textit{k}-fold. Furthermore, the proposed extension is very simple to implement on top of existing evolutionary computation methods, and can provide essentially a free boost in generalisation/testing performance.
Genetic Programming and Gradient Descent: A Memetic Approach to Binary Image Classification
Sep 28, 2019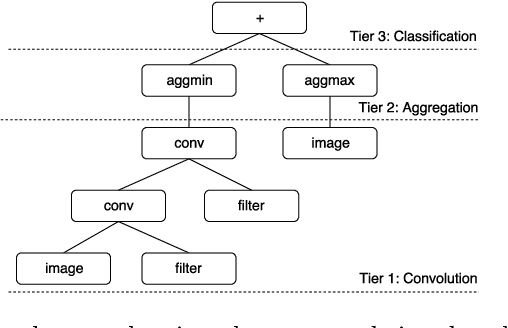
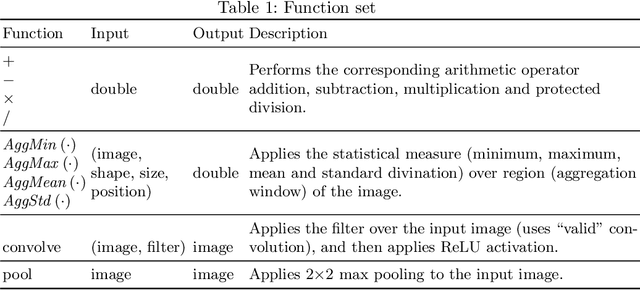
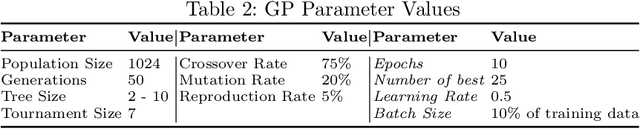
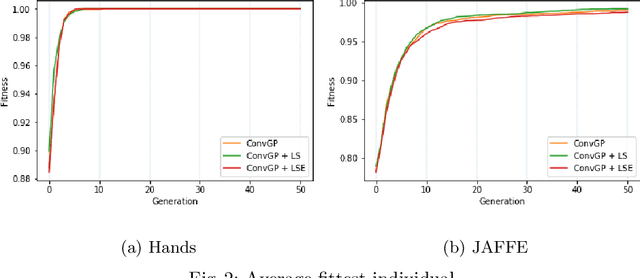
Image classification is an essential task in computer vision, which aims to categorise a set of images into different groups based on some visual criteria. Existing methods, such as convolutional neural networks, have been successfully utilised to perform image classification. However, such methods often require human intervention to design a model. Furthermore, such models are difficult to interpret and it is challenging to analyse the patterns of different classes. This paper presents a hybrid (memetic) approach combining genetic programming (GP) and Gradient-based optimisation for image classification to overcome the limitations mentioned. The performance of the proposed method is compared to a baseline version (without local search) on four binary classification image datasets to provide an insight into the usefulness of local search mechanisms for enhancing the performance of GP.