 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving generalisation of AutoML systems with dynamic fitness evaluations
Paper and Code
Jan 23, 2020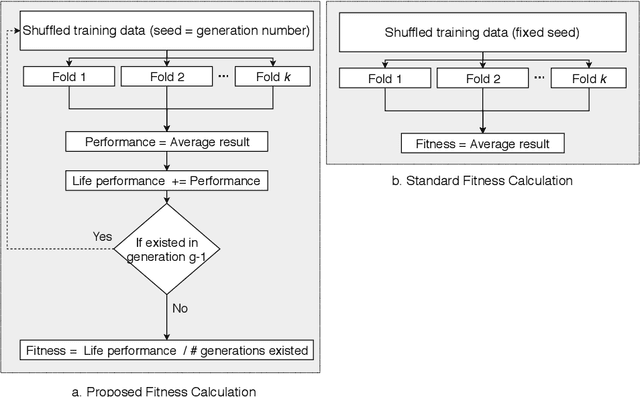


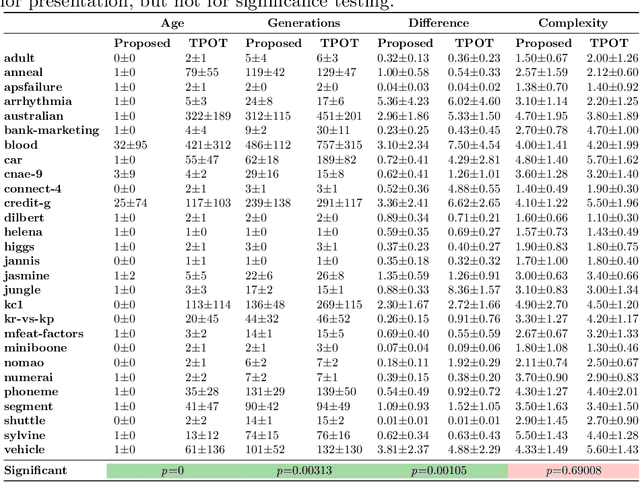
A common problem machine learning developers are faced with is overfitting, that is, fitting a pipeline too closely to the training data that the performance degrades for unseen data. Automated machine learning aims to free (or at least ease) the developer from the burden of pipeline creation, but this overfitting problem can persist. In fact, this can become more of a problem as we look to iteratively optimise the performance of an internal cross-validation (most often \textit{k}-fold). While this internal cross-validation hopes to reduce this overfitting, we show we can still risk overfitting to the particular folds used. In this work, we aim to remedy this problem by introducing dynamic fitness evaluations which approximate repeated \textit{k}-fold cross-validation, at little extra cost over single \textit{k}-fold, and far lower cost than typical repeated \textit{k}-fold. The results show that when time equated, the proposed fitness function results in significant improvement over the current state-of-the-art baseline method which uses an internal single \textit{k}-fold. Furthermore, the proposed extension is very simple to implement on top of existing evolutionary computation methods, and can provide essentially a free boost in generalisation/testing performance.