 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulate and Optimise: A two-layer mortgage simulator for designing novel mortgage assistance products
Nov 01, 2024



We develop a novel two-layer approach for optimising mortgage relief products through a simulated multi-agent mortgage environment. While the approach is generic, here the environment is calibrated to the US mortgage market based on publicly available census data and regulatory guidelines. Through the simulation layer, we assess the resilience of households to exogenous income shocks, while the optimisation layer explores strategies to improve the robustness of households to these shocks by making novel mortgage assistance products available to households. Households in the simulation are adaptive, learning to make mortgage-related decisions (such as product enrolment or strategic foreclosures) that maximize their utility, balancing their available liquidity and equity. We show how this novel two-layer simulation approach can successfully design novel mortgage assistance products to improve household resilience to exogenous shocks, and balance the costs of providing such products through post-hoc analysis. Previously, such analysis could only be conducted through expensive pilot studies involving real participants, demonstrating the benefit of the approach for designing and evaluating financial products.
O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
Oct 22, 2023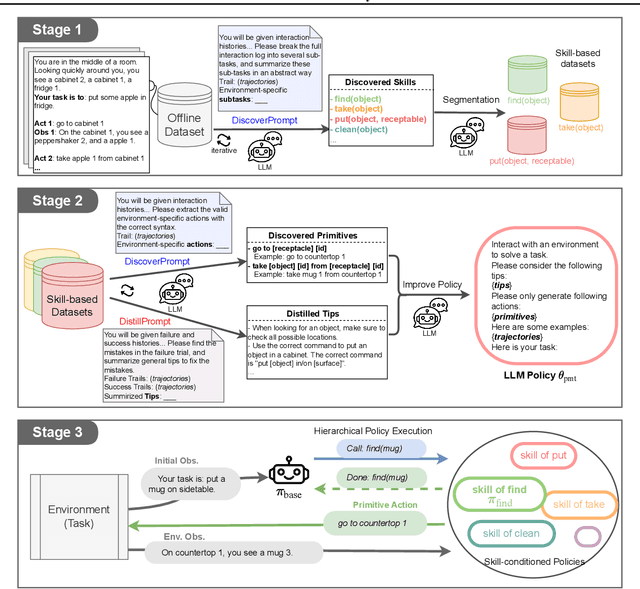
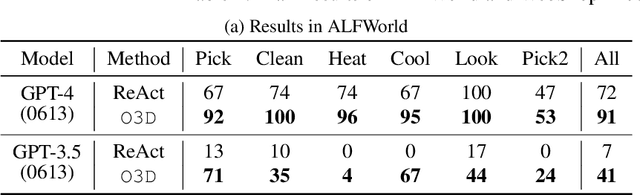
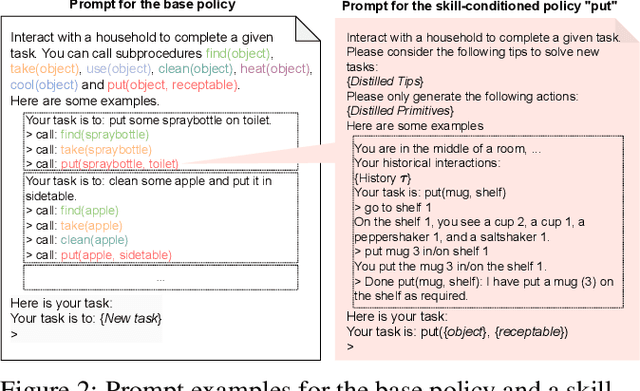

Recent advancements in large language models (LLMs) have exhibited promising performance in solving sequential decision-making problems. By imitating few-shot examples provided in the prompts (i.e., in-context learning), an LLM agent can interact with an external environment and complete given tasks without additional training. However, such few-shot examples are often insufficient to generate high-quality solutions for complex and long-horizon tasks, while the limited context length cannot consume larger-scale demonstrations. To this end, we propose an offline learning framework that utilizes offline data at scale (e.g, logs of human interactions) to facilitate the in-context learning performance of LLM agents. We formally define LLM-powered policies with both text-based approaches and code-based approaches. We then introduce an Offline Data-driven Discovery and Distillation (O3D) framework to improve LLM-powered policies without finetuning. O3D automatically discovers reusable skills and distills generalizable knowledge across multiple tasks based on offline interaction data, advancing the capability of solving downstream tasks. Empirical results under two interactive decision-making benchmarks (ALFWorld and WebShop) demonstrate that O3D can notably enhance the decision-making capabilities of LLMs through the offline discovery and distillation process, and consistently outperform baselines across various LLMs with both text-based-policy and code-based-policy.
Phantom -- An RL-driven framework for agent-based modeling of complex economic systems and markets
Oct 12, 2022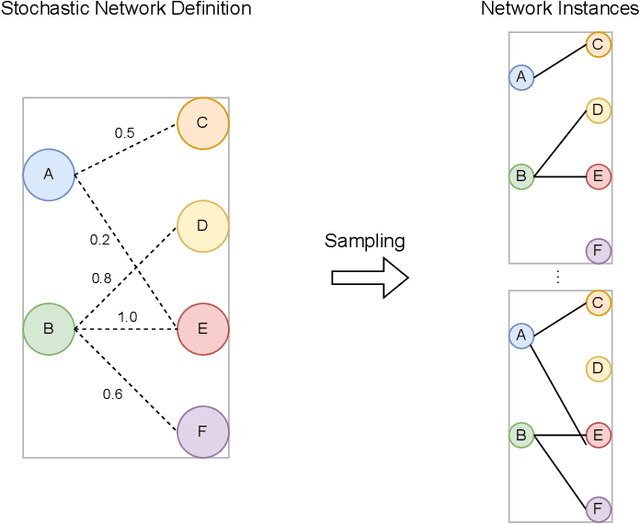
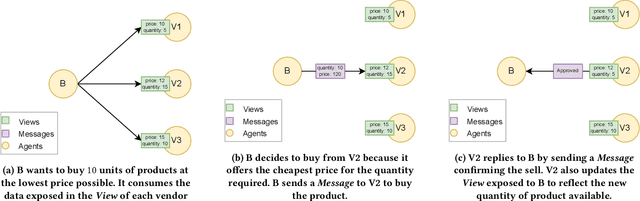
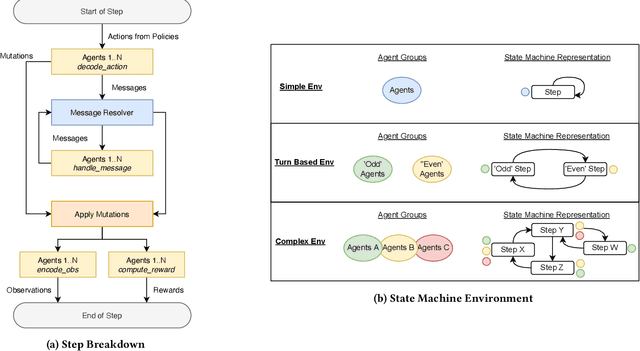
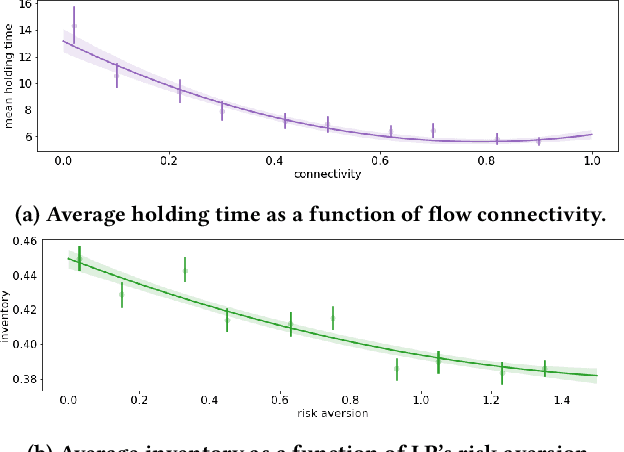
Agent based modeling (ABM) is a computational approach to modeling complex systems by specifying the behavior of autonomous decision-making components or agents in the system and allowing the system dynamics to emerge from their interactions. Recent advances in the field of Multi-agent reinforcement learning (MARL) have made it feasible to learn the equilibrium of complex environments where multiple agents learn at the same time - opening up the possibility of building ABMs where agent behaviors are learned and system dynamics can be analyzed. However, most ABM frameworks are not RL-native, in that they do not offer concepts and interfaces that are compatible with the use of MARL to learn agent behaviors. In this paper, we introduce a new framework, Phantom, to bridge the gap between ABM and MARL. Phantom is an RL-driven framework for agent-based modeling of complex multi-agent systems such as economic systems and markets. To enable this, the framework provides tools to specify the ABM in MARL-compatible terms - including features to encode dynamic partial observability, agent utility / reward functions, heterogeneity in agent preferences or types, and constraints on the order in which agents can act (e.g. Stackelberg games, or complex turn-taking environments). In this paper, we present these features, their design rationale and show how they were used to model and simulate Over-The-Counter (OTC) markets.