 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
Paper and Code
Oct 22, 2023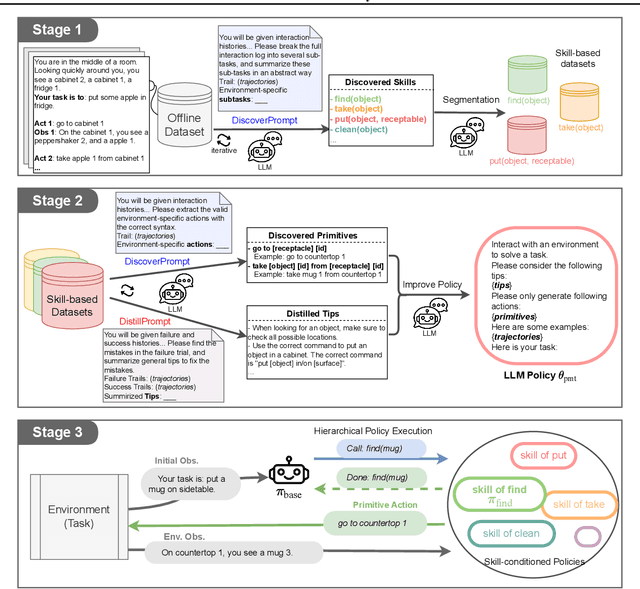
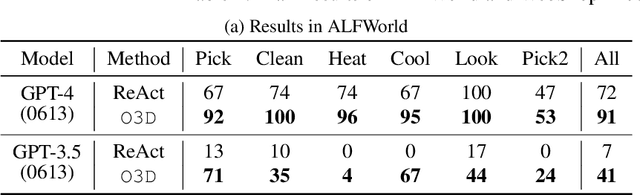
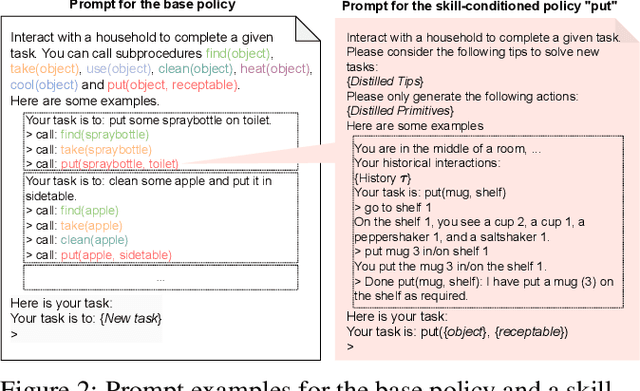

Recent advancements in large language models (LLMs) have exhibited promising performance in solving sequential decision-making problems. By imitating few-shot examples provided in the prompts (i.e., in-context learning), an LLM agent can interact with an external environment and complete given tasks without additional training. However, such few-shot examples are often insufficient to generate high-quality solutions for complex and long-horizon tasks, while the limited context length cannot consume larger-scale demonstrations. To this end, we propose an offline learning framework that utilizes offline data at scale (e.g, logs of human interactions) to facilitate the in-context learning performance of LLM agents. We formally define LLM-powered policies with both text-based approaches and code-based approaches. We then introduce an Offline Data-driven Discovery and Distillation (O3D) framework to improve LLM-powered policies without finetuning. O3D automatically discovers reusable skills and distills generalizable knowledge across multiple tasks based on offline interaction data, advancing the capability of solving downstream tasks. Empirical results under two interactive decision-making benchmarks (ALFWorld and WebShop) demonstrate that O3D can notably enhance the decision-making capabilities of LLMs through the offline discovery and distillation process, and consistently outperform baselines across various LLMs with both text-based-policy and code-based-policy.