 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning with Topological Information for Knowledge Graph Completion
Dec 11, 2024Knowledge graphs (KGs) are crucial for representing and reasoning over structured information, supporting a wide range of applications such as information retrieval, question answering, and decision-making. However, their effectiveness is often hindered by incompleteness, limiting their potential for real-world impact. While knowledge graph completion (KGC) has been extensively studied in the literature, recent advances in generative AI models, particularly large language models (LLMs), have introduced new opportunities for innovation. In-context learning has recently emerged as a promising approach for leveraging pretrained knowledge of LLMs across a range of natural language processing tasks and has been widely adopted in both academia and industry. However, how to utilize in-context learning for effective KGC remains relatively underexplored. We develop a novel method that incorporates topological information through in-context learning to enhance KGC performance. By integrating ontological knowledge and graph structure into the context of LLMs, our approach achieves strong performance in the transductive setting i.e., nodes in the test graph dataset are present in the training graph dataset. Furthermore, we apply our approach to KGC in the more challenging inductive setting, i.e., nodes in the training graph dataset and test graph dataset are disjoint, leveraging the ontology to infer useful information about missing nodes which serve as contextual cues for the LLM during inference. Our method demonstrates superior performance compared to baselines on the ILPC-small and ILPC-large datasets.
O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
Oct 22, 2023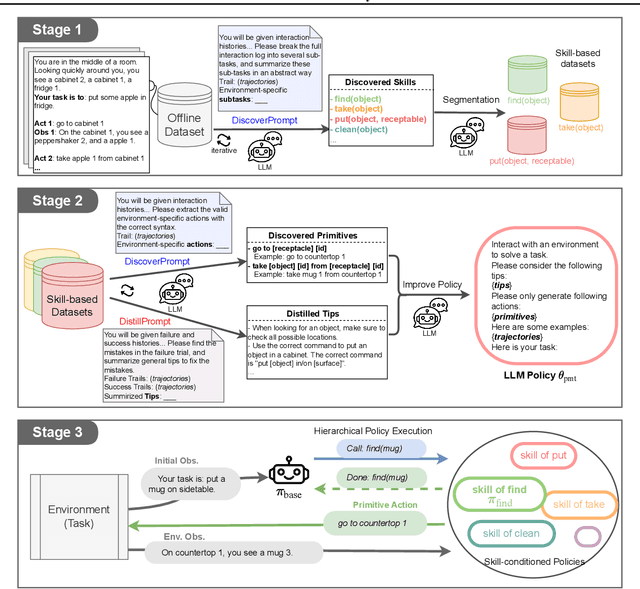
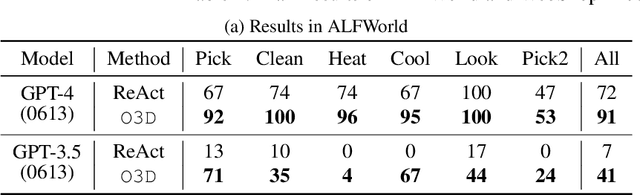
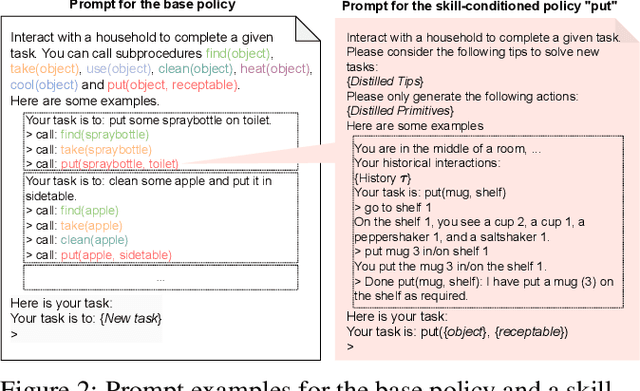

Recent advancements in large language models (LLMs) have exhibited promising performance in solving sequential decision-making problems. By imitating few-shot examples provided in the prompts (i.e., in-context learning), an LLM agent can interact with an external environment and complete given tasks without additional training. However, such few-shot examples are often insufficient to generate high-quality solutions for complex and long-horizon tasks, while the limited context length cannot consume larger-scale demonstrations. To this end, we propose an offline learning framework that utilizes offline data at scale (e.g, logs of human interactions) to facilitate the in-context learning performance of LLM agents. We formally define LLM-powered policies with both text-based approaches and code-based approaches. We then introduce an Offline Data-driven Discovery and Distillation (O3D) framework to improve LLM-powered policies without finetuning. O3D automatically discovers reusable skills and distills generalizable knowledge across multiple tasks based on offline interaction data, advancing the capability of solving downstream tasks. Empirical results under two interactive decision-making benchmarks (ALFWorld and WebShop) demonstrate that O3D can notably enhance the decision-making capabilities of LLMs through the offline discovery and distillation process, and consistently outperform baselines across various LLMs with both text-based-policy and code-based-policy.
Towards Multi-Agent Reinforcement Learning driven Over-The-Counter Market Simulations
Oct 13, 2022

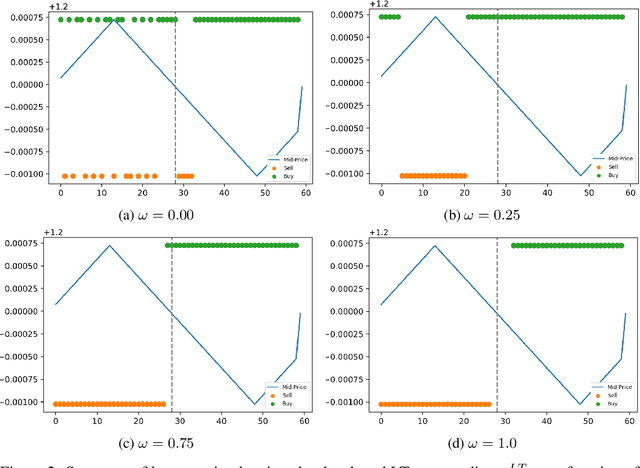

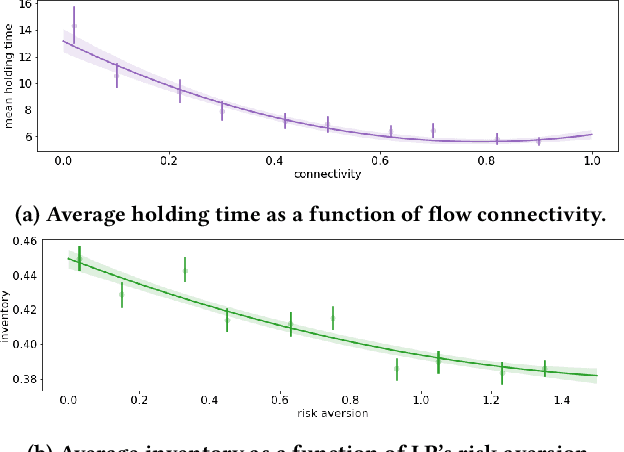
We study a game between liquidity provider and liquidity taker agents interacting in an over-the-counter market, for which the typical example is foreign exchange. We show how a suitable design of parameterized families of reward functions coupled with associated shared policy learning constitutes an efficient solution to this problem. Precisely, we show that our deep-reinforcement-learning-driven agents learn emergent behaviors relative to a wide spectrum of incentives encompassing profit-and-loss, optimal execution and market share, by playing against each other. In particular, we find that liquidity providers naturally learn to balance hedging and skewing as a function of their incentives, where the latter refers to setting their buy and sell prices asymmetrically as a function of their inventory. We further introduce a novel RL-based calibration algorithm which we found performed well at imposing constraints on the game equilibrium, both on toy and real market data.
Phantom -- An RL-driven framework for agent-based modeling of complex economic systems and markets
Oct 12, 2022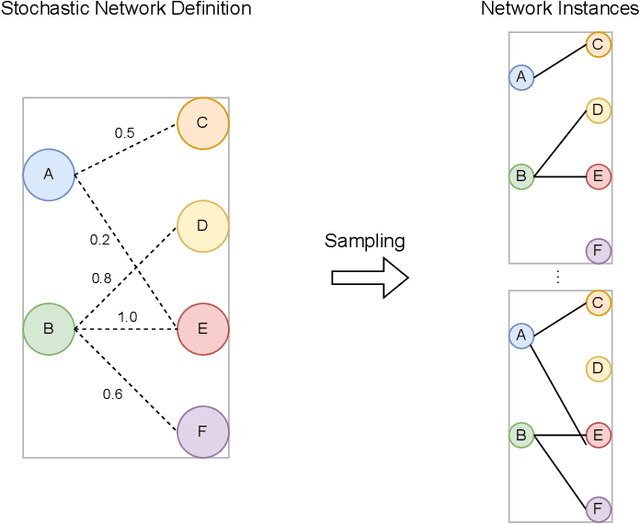
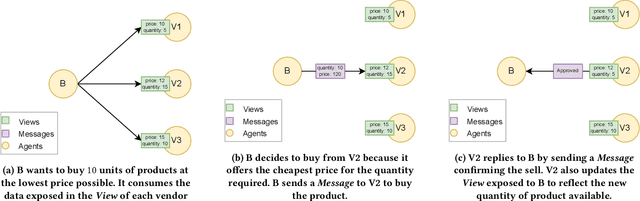
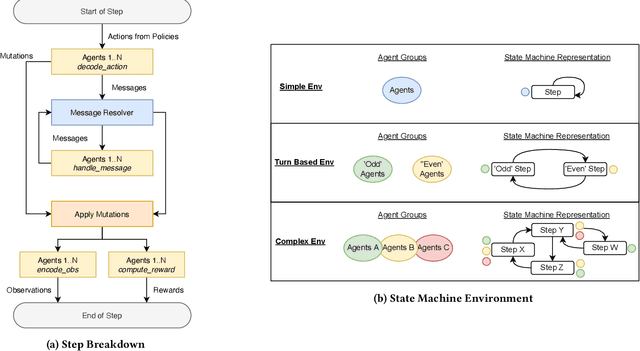
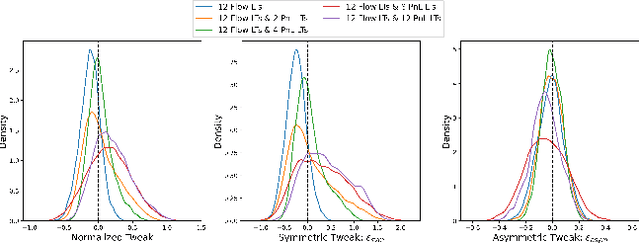
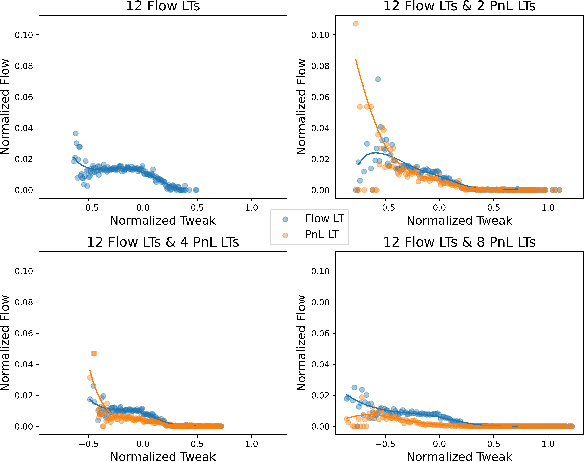
Agent based modeling (ABM) is a computational approach to modeling complex systems by specifying the behavior of autonomous decision-making components or agents in the system and allowing the system dynamics to emerge from their interactions. Recent advances in the field of Multi-agent reinforcement learning (MARL) have made it feasible to learn the equilibrium of complex environments where multiple agents learn at the same time - opening up the possibility of building ABMs where agent behaviors are learned and system dynamics can be analyzed. However, most ABM frameworks are not RL-native, in that they do not offer concepts and interfaces that are compatible with the use of MARL to learn agent behaviors. In this paper, we introduce a new framework, Phantom, to bridge the gap between ABM and MARL. Phantom is an RL-driven framework for agent-based modeling of complex multi-agent systems such as economic systems and markets. To enable this, the framework provides tools to specify the ABM in MARL-compatible terms - including features to encode dynamic partial observability, agent utility / reward functions, heterogeneity in agent preferences or types, and constraints on the order in which agents can act (e.g. Stackelberg games, or complex turn-taking environments). In this paper, we present these features, their design rationale and show how they were used to model and simulate Over-The-Counter (OTC) markets.
Towards a fully RL-based Market Simulator
Nov 08, 2021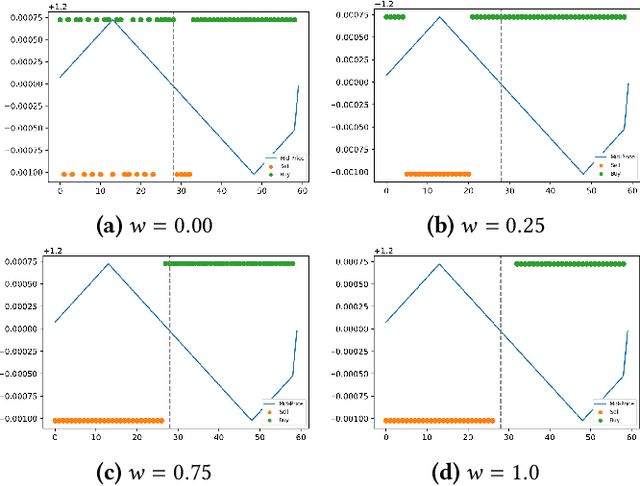
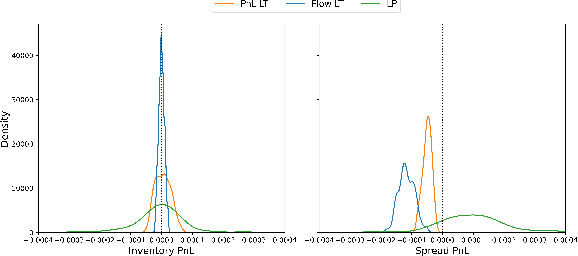
We present a new financial framework where two families of RL-based agents representing the Liquidity Providers and Liquidity Takers learn simultaneously to satisfy their objective. Thanks to a parametrized reward formulation and the use of Deep RL, each group learns a shared policy able to generalize and interpolate over a wide range of behaviors. This is a step towards a fully RL-based market simulator replicating complex market conditions particularly suited to study the dynamics of the financial market under various scenarios.
ABIDES-Gym: Gym Environments for Multi-Agent Discrete Event Simulation and Application to Financial Markets
Oct 27, 2021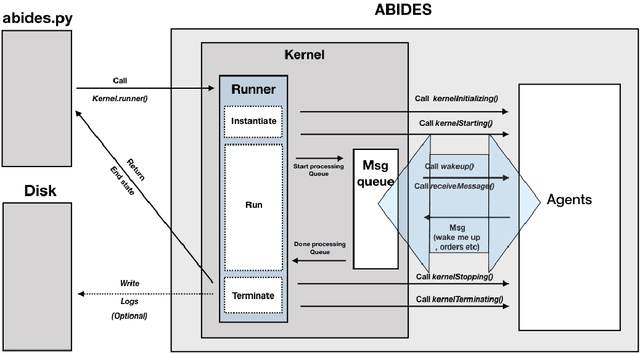
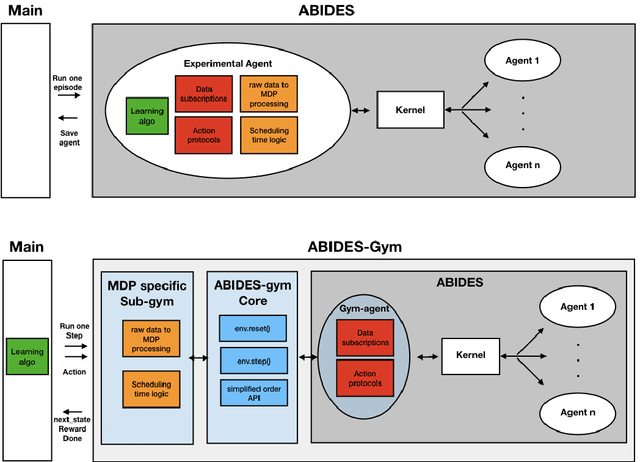
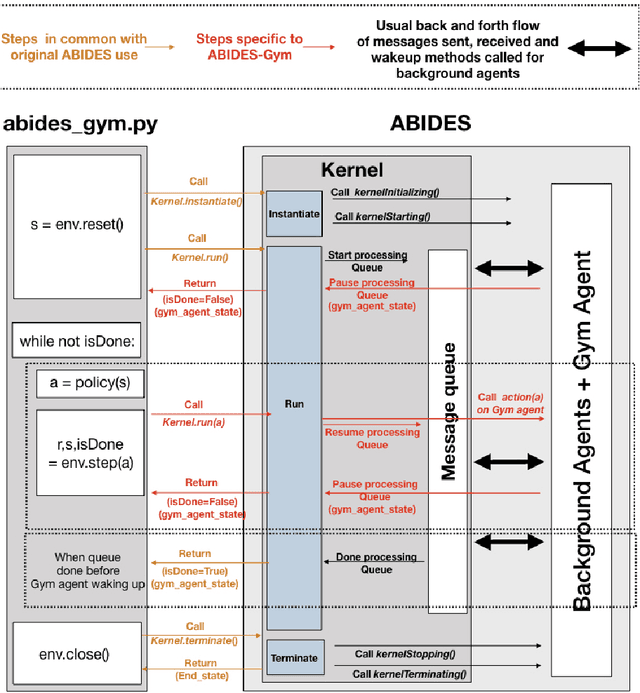
Model-free Reinforcement Learning (RL) requires the ability to sample trajectories by taking actions in the original problem environment or a simulated version of it. Breakthroughs in the field of RL have been largely facilitated by the development of dedicated open source simulators with easy to use frameworks such as OpenAI Gym and its Atari environments. In this paper we propose to use the OpenAI Gym framework on discrete event time based Discrete Event Multi-Agent Simulation (DEMAS). We introduce a general technique to wrap a DEMAS simulator into the Gym framework. We expose the technique in detail and implement it using the simulator ABIDES as a base. We apply this work by specifically using the markets extension of ABIDES, ABIDES-Markets, and develop two benchmark financial markets OpenAI Gym environments for training daily investor and execution agents. As a result, these two environments describe classic financial problems with a complex interactive market behavior response to the experimental agent's action.