 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradeFM: A Generative Foundation Model for Trade-flow and Market Microstructure
Feb 27, 2026Foundation models have transformed domains from language to genomics by learning general-purpose representations from large-scale, heterogeneous data. We introduce TradeFM, a 524M-parameter generative Transformer that brings this paradigm to market microstructure, learning directly from billions of trade events across >9K equities. To enable cross-asset generalization, we develop scale-invariant features and a universal tokenization scheme that map the heterogeneous, multi-modal event stream of order flow into a unified discrete sequence -- eliminating asset-specific calibration. Integrated with a deterministic market simulator, TradeFM-generated rollouts reproduce key stylized facts of financial returns, including heavy tails, volatility clustering, and absence of return autocorrelation. Quantitatively, TradeFM achieves 2-3x lower distributional error than Compound Hawkes baselines and generalizes zero-shot to geographically out-of-distribution APAC markets with moderate perplexity degradation. Together, these results suggest that scale-invariant trade representations capture transferable structure in market microstructure, opening a path toward synthetic data generation, stress testing, and learning-based trading agents.
In-Context Learning with Topological Information for Knowledge Graph Completion
Dec 11, 2024Knowledge graphs (KGs) are crucial for representing and reasoning over structured information, supporting a wide range of applications such as information retrieval, question answering, and decision-making. However, their effectiveness is often hindered by incompleteness, limiting their potential for real-world impact. While knowledge graph completion (KGC) has been extensively studied in the literature, recent advances in generative AI models, particularly large language models (LLMs), have introduced new opportunities for innovation. In-context learning has recently emerged as a promising approach for leveraging pretrained knowledge of LLMs across a range of natural language processing tasks and has been widely adopted in both academia and industry. However, how to utilize in-context learning for effective KGC remains relatively underexplored. We develop a novel method that incorporates topological information through in-context learning to enhance KGC performance. By integrating ontological knowledge and graph structure into the context of LLMs, our approach achieves strong performance in the transductive setting i.e., nodes in the test graph dataset are present in the training graph dataset. Furthermore, we apply our approach to KGC in the more challenging inductive setting, i.e., nodes in the training graph dataset and test graph dataset are disjoint, leveraging the ontology to infer useful information about missing nodes which serve as contextual cues for the LLM during inference. Our method demonstrates superior performance compared to baselines on the ILPC-small and ILPC-large datasets.
AI in Investment Analysis: LLMs for Equity Stock Ratings
Oct 30, 2024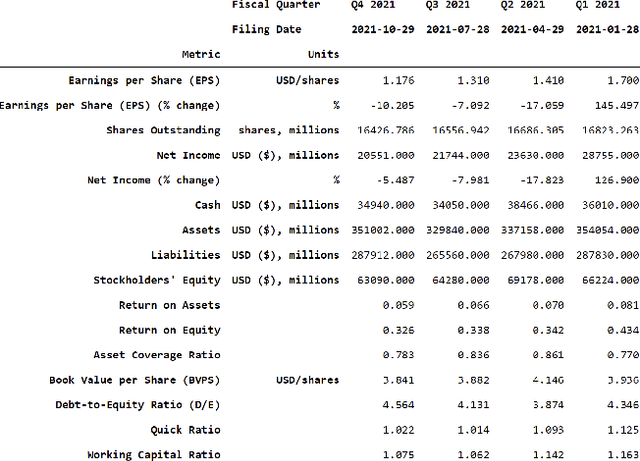
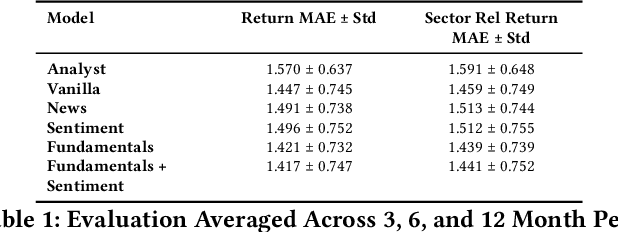
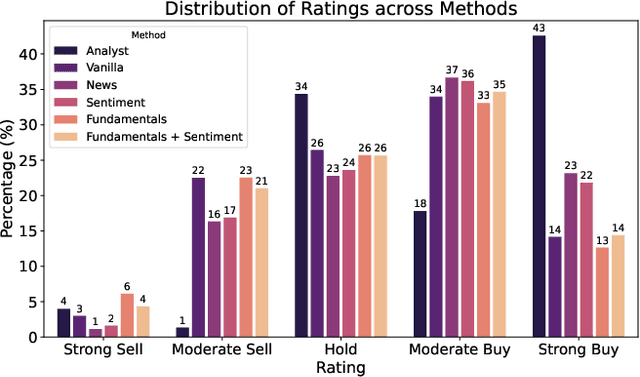
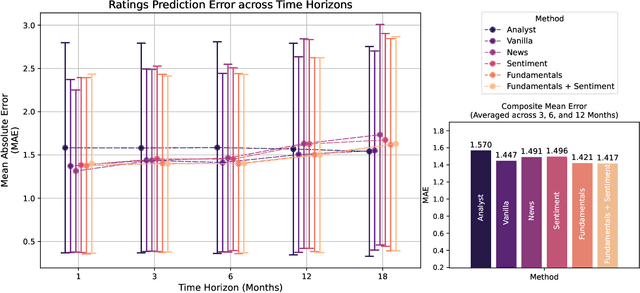
Investment Analysis is a cornerstone of the Financial Services industry. The rapid integration of advanced machine learning techniques, particularly Large Language Models (LLMs), offers opportunities to enhance the equity rating process. This paper explores the application of LLMs to generate multi-horizon stock ratings by ingesting diverse datasets. Traditional stock rating methods rely heavily on the expertise of financial analysts, and face several challenges such as data overload, inconsistencies in filings, and delayed reactions to market events. Our study addresses these issues by leveraging LLMs to improve the accuracy and consistency of stock ratings. Additionally, we assess the efficacy of using different data modalities with LLMs for the financial domain. We utilize varied datasets comprising fundamental financial, market, and news data from January 2022 to June 2024, along with GPT-4-32k (v0613) (with a training cutoff in Sep. 2021 to prevent information leakage). Our results show that our benchmark method outperforms traditional stock rating methods when assessed by forward returns, specially when incorporating financial fundamentals. While integrating news data improves short-term performance, substituting detailed news summaries with sentiment scores reduces token use without loss of performance. In many cases, omitting news data entirely enhances performance by reducing bias. Our research shows that LLMs can be leveraged to effectively utilize large amounts of multimodal financial data, as showcased by their effectiveness at the stock rating prediction task. Our work provides a reproducible and efficient framework for generating accurate stock ratings, serving as a cost-effective alternative to traditional methods. Future work will extend to longer timeframes, incorporate diverse data, and utilize newer models for enhanced insights.