 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Breaking Watermarks in Distortion-free Large Language Models
Feb 25, 2025In recent years, LLM watermarking has emerged as an attractive safeguard against AI-generated content, with promising applications in many real-world domains. However, there are growing concerns that the current LLM watermarking schemes are vulnerable to expert adversaries wishing to reverse-engineer the watermarking mechanisms. Prior work in "breaking" or "stealing" LLM watermarks mainly focuses on the distribution-modifying algorithm of Kirchenbauer et al. (2023), which perturbs the logit vector before sampling. In this work, we focus on reverse-engineering the other prominent LLM watermarking scheme, distortion-free watermarking (Kuditipudi et al. 2024), which preserves the underlying token distribution by using a hidden watermarking key sequence. We demonstrate that, even under a more sophisticated watermarking scheme, it is possible to "compromise" the LLM and carry out a "spoofing" attack. Specifically, we propose a mixed integer linear programming framework that accurately estimates the secret key used for watermarking using only a few samples of the watermarked dataset. Our initial findings challenge the current theoretical claims on the robustness and usability of existing LLM watermarking techniques.
AI in Investment Analysis: LLMs for Equity Stock Ratings
Oct 30, 2024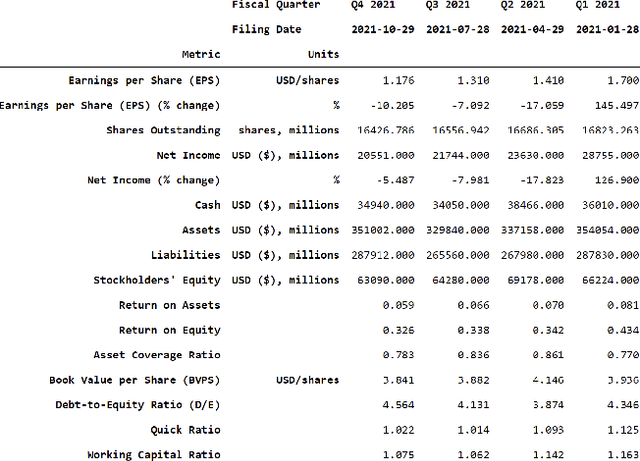
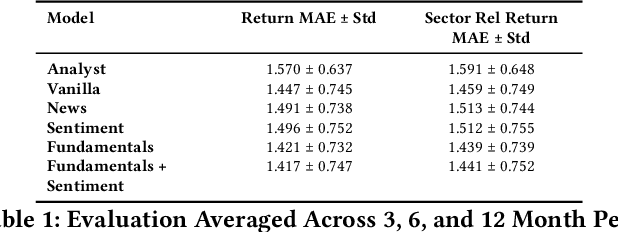
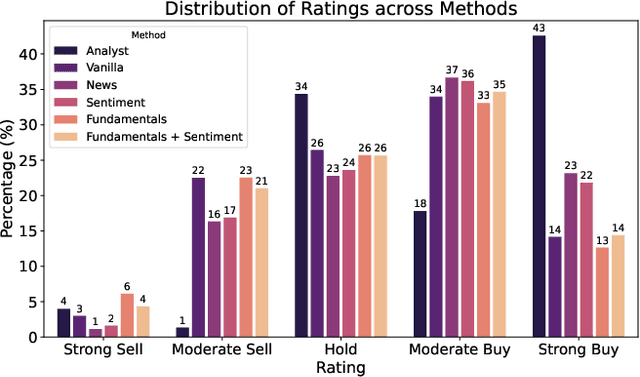
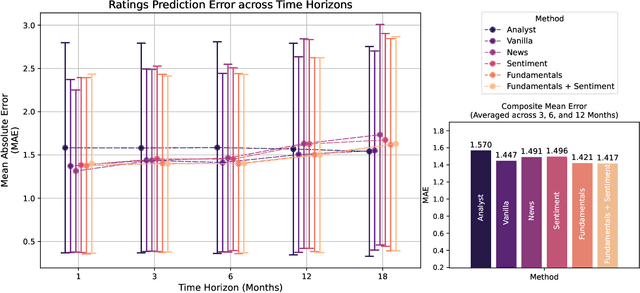
Investment Analysis is a cornerstone of the Financial Services industry. The rapid integration of advanced machine learning techniques, particularly Large Language Models (LLMs), offers opportunities to enhance the equity rating process. This paper explores the application of LLMs to generate multi-horizon stock ratings by ingesting diverse datasets. Traditional stock rating methods rely heavily on the expertise of financial analysts, and face several challenges such as data overload, inconsistencies in filings, and delayed reactions to market events. Our study addresses these issues by leveraging LLMs to improve the accuracy and consistency of stock ratings. Additionally, we assess the efficacy of using different data modalities with LLMs for the financial domain. We utilize varied datasets comprising fundamental financial, market, and news data from January 2022 to June 2024, along with GPT-4-32k (v0613) (with a training cutoff in Sep. 2021 to prevent information leakage). Our results show that our benchmark method outperforms traditional stock rating methods when assessed by forward returns, specially when incorporating financial fundamentals. While integrating news data improves short-term performance, substituting detailed news summaries with sentiment scores reduces token use without loss of performance. In many cases, omitting news data entirely enhances performance by reducing bias. Our research shows that LLMs can be leveraged to effectively utilize large amounts of multimodal financial data, as showcased by their effectiveness at the stock rating prediction task. Our work provides a reproducible and efficient framework for generating accurate stock ratings, serving as a cost-effective alternative to traditional methods. Future work will extend to longer timeframes, incorporate diverse data, and utilize newer models for enhanced insights.