 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradeFM: A Generative Foundation Model for Trade-flow and Market Microstructure
Feb 27, 2026Foundation models have transformed domains from language to genomics by learning general-purpose representations from large-scale, heterogeneous data. We introduce TradeFM, a 524M-parameter generative Transformer that brings this paradigm to market microstructure, learning directly from billions of trade events across >9K equities. To enable cross-asset generalization, we develop scale-invariant features and a universal tokenization scheme that map the heterogeneous, multi-modal event stream of order flow into a unified discrete sequence -- eliminating asset-specific calibration. Integrated with a deterministic market simulator, TradeFM-generated rollouts reproduce key stylized facts of financial returns, including heavy tails, volatility clustering, and absence of return autocorrelation. Quantitatively, TradeFM achieves 2-3x lower distributional error than Compound Hawkes baselines and generalizes zero-shot to geographically out-of-distribution APAC markets with moderate perplexity degradation. Together, these results suggest that scale-invariant trade representations capture transferable structure in market microstructure, opening a path toward synthetic data generation, stress testing, and learning-based trading agents.
Behavioral Sequence Modeling with Ensemble Learning
Nov 04, 2024



We investigate the use of sequence analysis for behavior modeling, emphasizing that sequential context often outweighs the value of aggregate features in understanding human behavior. We discuss framing common problems in fields like healthcare, finance, and e-commerce as sequence modeling tasks, and address challenges related to constructing coherent sequences from fragmented data and disentangling complex behavior patterns. We present a framework for sequence modeling using Ensembles of Hidden Markov Models, which are lightweight, interpretable, and efficient. Our ensemble-based scoring method enables robust comparison across sequences of different lengths and enhances performance in scenarios with imbalanced or scarce data. The framework scales in real-world scenarios, is compatible with downstream feature-based modeling, and is applicable in both supervised and unsupervised learning settings. We demonstrate the effectiveness of our method with results on a longitudinal human behavior dataset.
AI in Investment Analysis: LLMs for Equity Stock Ratings
Oct 30, 2024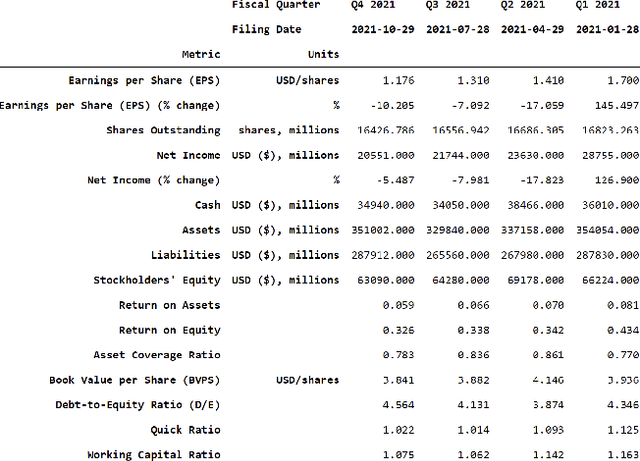
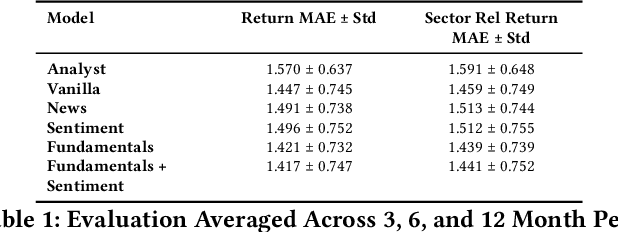
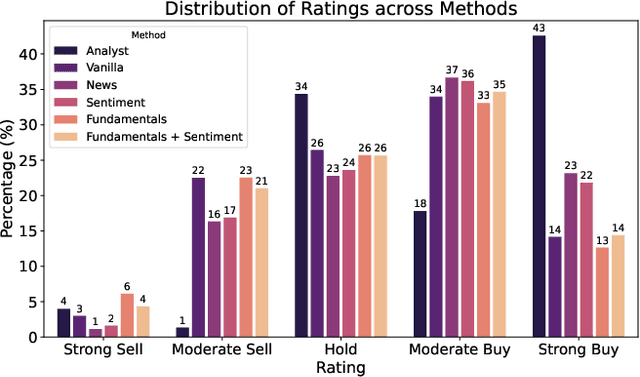
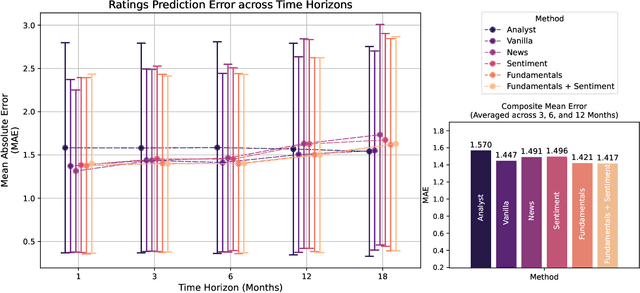
Investment Analysis is a cornerstone of the Financial Services industry. The rapid integration of advanced machine learning techniques, particularly Large Language Models (LLMs), offers opportunities to enhance the equity rating process. This paper explores the application of LLMs to generate multi-horizon stock ratings by ingesting diverse datasets. Traditional stock rating methods rely heavily on the expertise of financial analysts, and face several challenges such as data overload, inconsistencies in filings, and delayed reactions to market events. Our study addresses these issues by leveraging LLMs to improve the accuracy and consistency of stock ratings. Additionally, we assess the efficacy of using different data modalities with LLMs for the financial domain. We utilize varied datasets comprising fundamental financial, market, and news data from January 2022 to June 2024, along with GPT-4-32k (v0613) (with a training cutoff in Sep. 2021 to prevent information leakage). Our results show that our benchmark method outperforms traditional stock rating methods when assessed by forward returns, specially when incorporating financial fundamentals. While integrating news data improves short-term performance, substituting detailed news summaries with sentiment scores reduces token use without loss of performance. In many cases, omitting news data entirely enhances performance by reducing bias. Our research shows that LLMs can be leveraged to effectively utilize large amounts of multimodal financial data, as showcased by their effectiveness at the stock rating prediction task. Our work provides a reproducible and efficient framework for generating accurate stock ratings, serving as a cost-effective alternative to traditional methods. Future work will extend to longer timeframes, incorporate diverse data, and utilize newer models for enhanced insights.
Ensemble Methods for Sequence Classification with Hidden Markov Models
Sep 11, 2024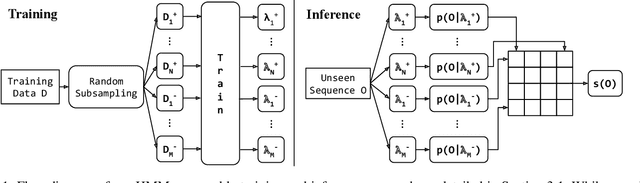


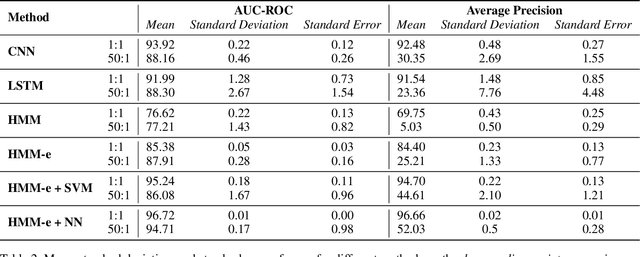
We present a lightweight approach to sequence classification using Ensemble Methods for Hidden Markov Models (HMMs). HMMs offer significant advantages in scenarios with imbalanced or smaller datasets due to their simplicity, interpretability, and efficiency. These models are particularly effective in domains such as finance and biology, where traditional methods struggle with high feature dimensionality and varied sequence lengths. Our ensemble-based scoring method enables the comparison of sequences of any length and improves performance on imbalanced datasets. This study focuses on the binary classification problem, particularly in scenarios with data imbalance, where the negative class is the majority (e.g., normal data) and the positive class is the minority (e.g., anomalous data), often with extreme distribution skews. We propose a novel training approach for HMM Ensembles that generalizes to multi-class problems and supports classification and anomaly detection. Our method fits class-specific groups of diverse models using random data subsets, and compares likelihoods across classes to produce composite scores, achieving high average precisions and AUCs. In addition, we compare our approach with neural network-based methods such as Convolutional Neural Networks (CNNs) and Long Short-Term Memory networks (LSTMs), highlighting the efficiency and robustness of HMMs in data-scarce environments. Motivated by real-world use cases, our method demonstrates robust performance across various benchmarks, offering a flexible framework for diverse applications.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Visual Time Series Forecasting: An Image-driven Approach
Jul 02, 2021



In this work, we address time-series forecasting as a computer vision task. We capture input data as an image and train a model to produce the subsequent image. This approach results in predicting distributions as opposed to pointwise values. To assess the robustness and quality of our approach, we examine various datasets and multiple evaluation metrics. Our experiments show that our forecasting tool is effective for cyclic data but somewhat less for irregular data such as stock prices. Importantly, when using image-based evaluation metrics, we find our method to outperform various baselines, including ARIMA, and a numerical variation of our deep learning approach.
Visual Forecasting of Time Series with Image-to-Image Regression
Nov 18, 2020



Time series forecasting is essential for agents to make decisions in many domains. Existing models rely on classical statistical methods to predict future values based on previously observed numerical information. Yet, practitioners often rely on visualizations such as charts and plots to reason about their predictions. Inspired by the end-users, we re-imagine the topic by creating a framework to produce visual forecasts, similar to the way humans intuitively do. In this work, we take a novel approach by leveraging advances in deep learning to extend the field of time series forecasting to a visual setting. We do this by transforming the numerical analysis problem into the computer vision domain. Using visualizations of time series data as input, we train a convolutional autoencoder to produce corresponding visual forecasts. We examine various synthetic and real datasets with diverse degrees of complexity. Our experiments show that visual forecasting is effective for cyclic data but somewhat less for irregular data such as stock price. Importantly, we find the proposed visual forecasting method to outperform numerical baselines. We attribute the success of the visual forecasting approach to the fact that we convert the continuous numerical regression problem into a discrete domain with quantization of the continuous target signal into pixel space.
Debiasing classifiers: is reality at variance with expectation?
Nov 04, 2020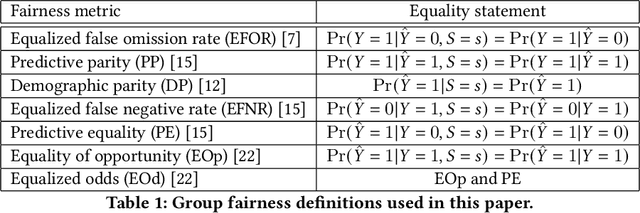

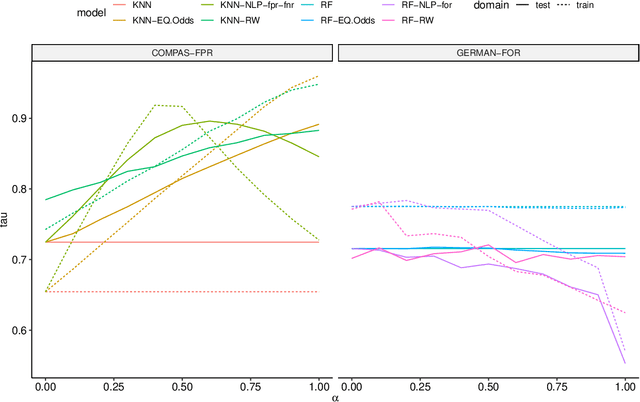
Many methods for debiasing classifiers have been proposed, but their effectiveness in practice remains unclear. We evaluate the performance of pre-processing and post-processing debiasers for improving fairness in random forest classifiers trained on a suite of data sets. Specifically, we study how these debiasers generalize with respect to both out-of-sample test error for computing fairness -- performance and fairness -- fairness trade-offs, and on the change in other fairness metrics that were not explicitly optimised. Our results demonstrate that out-of-sample performance on fairness and performance can vary substantially and unexpectedly. Moreover, the variance in estimation arises from class imbalances with respect to both the outcome and the protected classes. Our results highlight the importance of evaluating out-of-sample performance in practical usage.
Cross-Domain Perceptual Reward Functions
Jul 25, 2017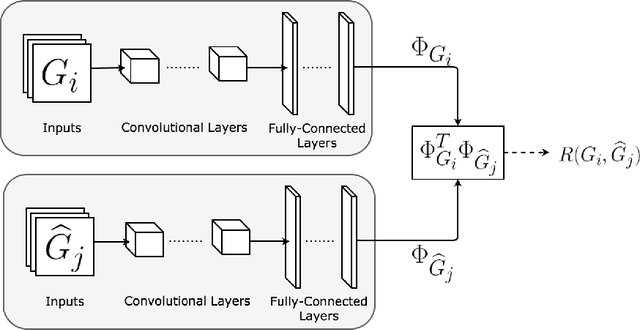

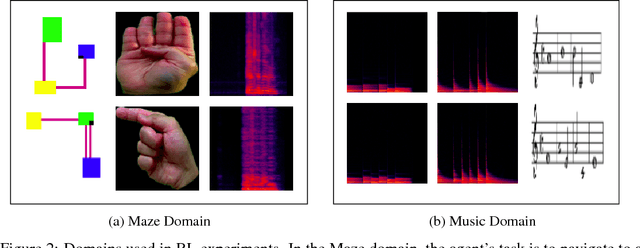
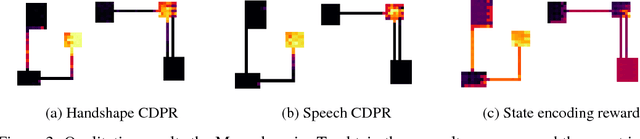
In reinforcement learning, we often define goals by specifying rewards within desirable states. One problem with this approach is that we typically need to redefine the rewards each time the goal changes, which often requires some understanding of the solution in the agents environment. When humans are learning to complete tasks, we regularly utilize alternative sources that guide our understanding of the problem. Such task representations allow one to specify goals on their own terms, thus providing specifications that can be appropriately interpreted across various environments. This motivates our own work, in which we represent goals in environments that are different from the agents. We introduce Cross-Domain Perceptual Reward (CDPR) functions, learned rewards that represent the visual similarity between an agents state and a cross-domain goal image. We report results for learning the CDPRs with a deep neural network and using them to solve two tasks with deep reinforcement learning.