 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Agent Behaviors from Videos via Motion GANs
Nov 21, 2017



A major bottleneck for developing general reinforcement learning agents is determining rewards that will yield desirable behaviors under various circumstances. We introduce a general mechanism for automatically specifying meaningful behaviors from raw pixels. In particular, we train a generative adversarial network to produce short sub-goals represented through motion templates. We demonstrate that this approach generates visually meaningful behaviors in unknown environments with novel agents and describe how these motions can be used to train reinforcement learning agents.
Cross-Domain Perceptual Reward Functions
Jul 25, 2017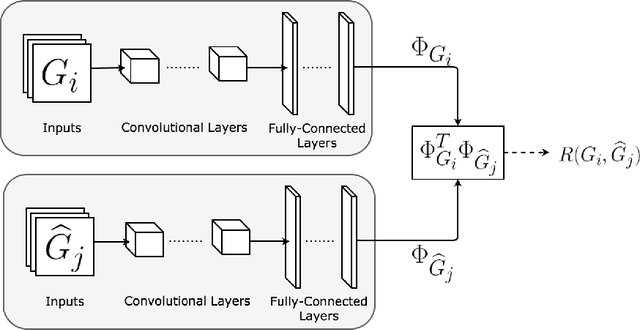

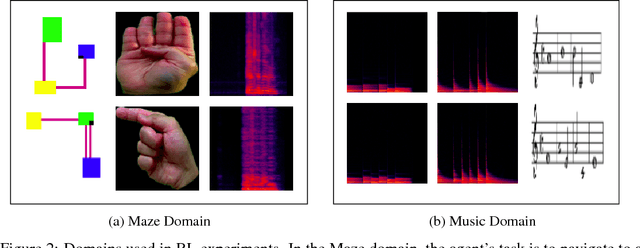
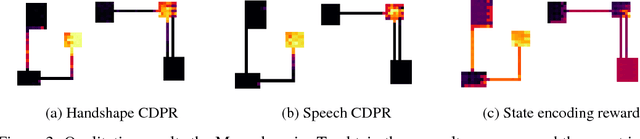
In reinforcement learning, we often define goals by specifying rewards within desirable states. One problem with this approach is that we typically need to redefine the rewards each time the goal changes, which often requires some understanding of the solution in the agents environment. When humans are learning to complete tasks, we regularly utilize alternative sources that guide our understanding of the problem. Such task representations allow one to specify goals on their own terms, thus providing specifications that can be appropriately interpreted across various environments. This motivates our own work, in which we represent goals in environments that are different from the agents. We introduce Cross-Domain Perceptual Reward (CDPR) functions, learned rewards that represent the visual similarity between an agents state and a cross-domain goal image. We report results for learning the CDPRs with a deep neural network and using them to solve two tasks with deep reinforcement learning.