 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFactX: Scalable Reasoning with Reliable Facts via Constrained Generation
Aug 23, 2025Knowledge gaps and hallucinations are persistent challenges for Large Language Models (LLMs), which generate unreliable responses when lacking the necessary information to fulfill user instructions. Existing approaches, such as Retrieval-Augmented Generation (RAG) and tool use, aim to address these issues by incorporating external knowledge. Yet, they rely on additional models or services, resulting in complex pipelines, potential error propagation, and often requiring the model to process a large number of tokens. In this paper, we present a scalable method that enables LLMs to access external knowledge without depending on retrievers or auxiliary models. Our approach uses constrained generation with a pre-built prefix-tree index. Triples from a Knowledge Graph are verbalized in textual facts, tokenized, and indexed in a prefix tree for efficient access. During inference, to acquire external knowledge, the LLM generates facts with constrained generation which allows only sequences of tokens that form an existing fact. We evaluate our proposal on Question Answering and show that it scales to large knowledge bases (800 million facts), adapts to domain-specific data, and achieves effective results. These gains come with minimal generation-time overhead. ReFactX code is available at https://github.com/rpo19/ReFactX.
SMART: Relation-Aware Learning of Geometric Representations for Knowledge Graphs
Jul 17, 2025Knowledge graph representation learning approaches provide a mapping between symbolic knowledge in the form of triples in a knowledge graph (KG) and their feature vectors. Knowledge graph embedding (KGE) models often represent relations in a KG as geometric transformations. Most state-of-the-art (SOTA) KGE models are derived from elementary geometric transformations (EGTs), such as translation, scaling, rotation, and reflection, or their combinations. These geometric transformations enable the models to effectively preserve specific structural and relational patterns of the KG. However, the current use of EGTs by KGEs remains insufficient without considering relation-specific transformations. Although recent models attempted to address this problem by ensembling SOTA baseline models in different ways, only a single or composite version of geometric transformations are used by such baselines to represent all the relations. In this paper, we propose a framework that evaluates how well each relation fits with different geometric transformations. Based on this ranking, the model can: (1) assign the best-matching transformation to each relation, or (2) use majority voting to choose one transformation type to apply across all relations. That is, the model learns a single relation-specific EGT in low dimensional vector space through an attention mechanism. Furthermore, we use the correlation between relations and EGTs, which are learned in a low dimension, for relation embeddings in a high dimensional vector space. The effectiveness of our models is demonstrated through comprehensive evaluations on three benchmark KGs as well as a real-world financial KG, witnessing a performance comparable to leading models
Robust Causal Discovery in Real-World Time Series with Power-Laws
Jul 16, 2025Exploring causal relationships in stochastic time series is a challenging yet crucial task with a vast range of applications, including finance, economics, neuroscience, and climate science. Many algorithms for Causal Discovery (CD) have been proposed, but they often exhibit a high sensitivity to noise, resulting in misleading causal inferences when applied to real data. In this paper, we observe that the frequency spectra of typical real-world time series follow a power-law distribution, notably due to an inherent self-organizing behavior. Leveraging this insight, we build a robust CD method based on the extraction of power -law spectral features that amplify genuine causal signals. Our method consistently outperforms state-of-the-art alternatives on both synthetic benchmarks and real-world datasets with known causal structures, demonstrating its robustness and practical relevance.
Privacy-Preserving Synthetically Augmented Knowledge Graphs with Semantic Utility
Oct 16, 2024



Knowledge Graphs (KGs) have recently gained relevant attention in many application domains, from healthcare to biotechnology, from logistics to finance. Financial organisations, central banks, economic research entities, and national supervision authorities apply ontological reasoning on KGs to address crucial business tasks, such as economic policymaking, banking supervision, anti-money laundering, and economic research. Reasoning allows for the generation of derived knowledge capturing complex business semantics and the set up of effective business processes. A major obstacle in KGs sharing is represented by privacy considerations since the identity of the data subjects and their sensitive or company-confidential information may be improperly exposed. In this paper, we propose a novel framework to enable KGs sharing while ensuring that information that should remain private is not directly released nor indirectly exposed via derived knowledge, while maintaining the embedded knowledge of the KGs to support business downstream tasks. Our approach produces a privacy-preserving synthetic KG as an augmentation of the input one via the introduction of structural anonymisation. We introduce a novel privacy measure for KGs, which considers derived knowledge and a new utility metric that captures the business semantics we want to preserve, and propose two novel anonymization algorithms. Our extensive experimental evaluation, with both synthetic graphs and real-world datasets, confirms the effectiveness of our approach achieving up to a 70% improvement in the privacy of entities compared to existing methods not specifically designed for KGs.
Simulating the economic impact of rationality through reinforcement learning and agent-based modelling
May 03, 2024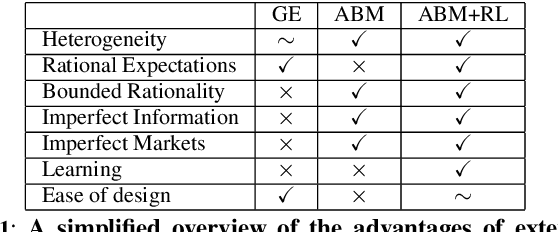
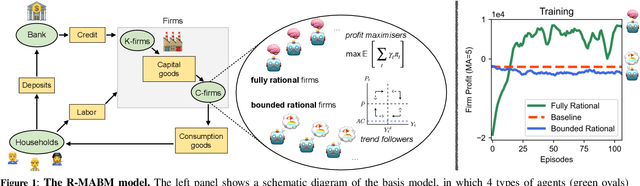
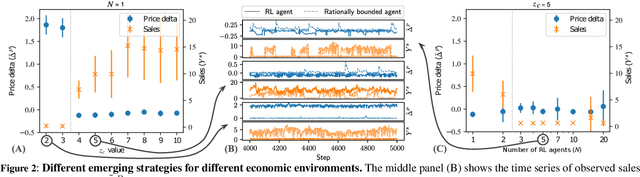
Agent-based models (ABMs) are simulation models used in economics to overcome some of the limitations of traditional frameworks based on general equilibrium assumptions. However, agents within an ABM follow predetermined, not fully rational, behavioural rules which can be cumbersome to design and difficult to justify. Here we leverage multi-agent reinforcement learning (RL) to expand the capabilities of ABMs with the introduction of fully rational agents that learn their policy by interacting with the environment and maximising a reward function. Specifically, we propose a 'Rational macro ABM' (R-MABM) framework by extending a paradigmatic macro ABM from the economic literature. We show that gradually substituting ABM firms in the model with RL agents, trained to maximise profits, allows for a thorough study of the impact of rationality on the economy. We find that RL agents spontaneously learn three distinct strategies for maximising profits, with the optimal strategy depending on the level of market competition and rationality. We also find that RL agents with independent policies, and without the ability to communicate with each other, spontaneously learn to segregate into different strategic groups, thus increasing market power and overall profits. Finally, we find that a higher degree of rationality in the economy always improves the macroeconomic environment as measured by total output, depending on the specific rational policy, this can come at the cost of higher instability. Our R-MABM framework is general, it allows for stable multi-agent learning, and represents a principled and robust direction to extend existing economic simulators.
LLM-driven Imitation of Subrational Behavior : Illusion or Reality?
Feb 13, 2024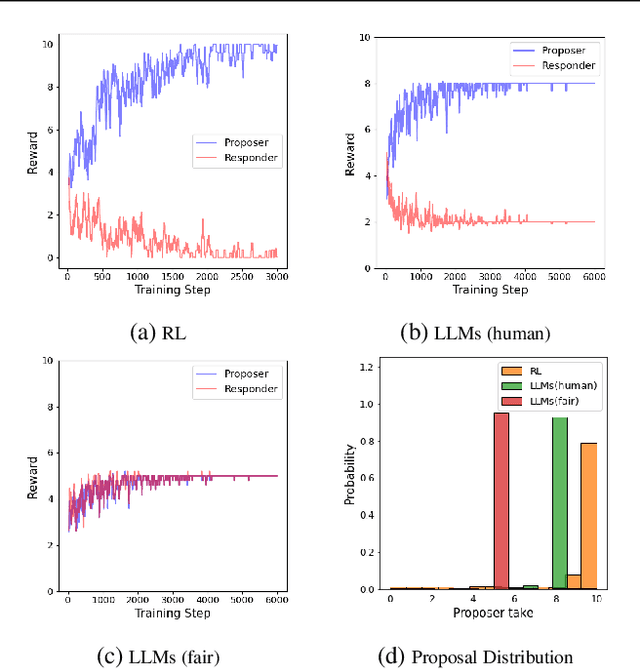

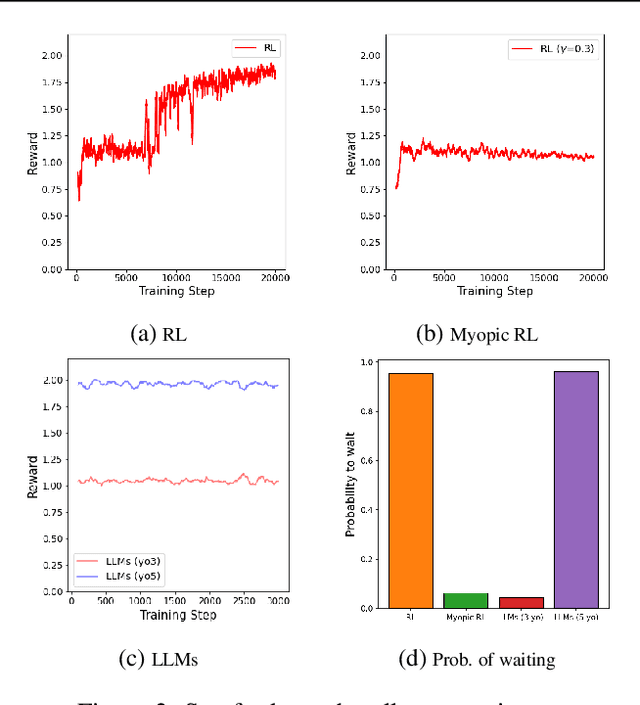

Modeling subrational agents, such as humans or economic households, is inherently challenging due to the difficulty in calibrating reinforcement learning models or collecting data that involves human subjects. Existing work highlights the ability of Large Language Models (LLMs) to address complex reasoning tasks and mimic human communication, while simulation using LLMs as agents shows emergent social behaviors, potentially improving our comprehension of human conduct. In this paper, we propose to investigate the use of LLMs to generate synthetic human demonstrations, which are then used to learn subrational agent policies though Imitation Learning. We make an assumption that LLMs can be used as implicit computational models of humans, and propose a framework to use synthetic demonstrations derived from LLMs to model subrational behaviors that are characteristic of humans (e.g., myopic behavior or preference for risk aversion). We experimentally evaluate the ability of our framework to model sub-rationality through four simple scenarios, including the well-researched ultimatum game and marshmallow experiment. To gain confidence in our framework, we are able to replicate well-established findings from prior human studies associated with the above scenarios. We conclude by discussing the potential benefits, challenges and limitations of our framework.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Multi-Modal Financial Time-Series Retrieval Through Latent Space Projections
Sep 28, 2023Financial firms commonly process and store billions of time-series data, generated continuously and at a high frequency. To support efficient data storage and retrieval, specialized time-series databases and systems have emerged. These databases support indexing and querying of time-series by a constrained Structured Query Language(SQL)-like format to enable queries like "Stocks with monthly price returns greater than 5%", and expressed in rigid formats. However, such queries do not capture the intrinsic complexity of high dimensional time-series data, which can often be better described by images or language (e.g., "A stock in low volatility regime"). Moreover, the required storage, computational time, and retrieval complexity to search in the time-series space are often non-trivial. In this paper, we propose and demonstrate a framework to store multi-modal data for financial time-series in a lower-dimensional latent space using deep encoders, such that the latent space projections capture not only the time series trends but also other desirable information or properties of the financial time-series data (such as price volatility). Moreover, our approach allows user-friendly query interfaces, enabling natural language text or sketches of time-series, for which we have developed intuitive interfaces. We demonstrate the advantages of our method in terms of computational efficiency and accuracy on real historical data as well as synthetic data, and highlight the utility of latent-space projections in the storage and retrieval of financial time-series data with intuitive query modalities.
ATMS: Algorithmic Trading-Guided Market Simulation
Sep 04, 2023



The effective construction of an Algorithmic Trading (AT) strategy often relies on market simulators, which remains challenging due to existing methods' inability to adapt to the sequential and dynamic nature of trading activities. This work fills this gap by proposing a metric to quantify market discrepancy. This metric measures the difference between a causal effect from underlying market unique characteristics and it is evaluated through the interaction between the AT agent and the market. Most importantly, we introduce Algorithmic Trading-guided Market Simulation (ATMS) by optimizing our proposed metric. Inspired by SeqGAN, ATMS formulates the simulator as a stochastic policy in reinforcement learning (RL) to account for the sequential nature of trading. Moreover, ATMS utilizes the policy gradient update to bypass differentiating the proposed metric, which involves non-differentiable operations such as order deletion from the market. Through extensive experiments on semi-real market data, we demonstrate the effectiveness of our metric and show that ATMS generates market data with improved similarity to reality compared to the state-of-the-art conditional Wasserstein Generative Adversarial Network (cWGAN) approach. Furthermore, ATMS produces market data with more balanced BUY and SELL volumes, mitigating the bias of the cWGAN baseline approach, where a simple strategy can exploit the BUY/SELL imbalance for profit.
On the Constrained Time-Series Generation Problem
Jul 04, 2023



Synthetic time series are often used in practical applications to augment the historical time series dataset for better performance of machine learning algorithms, amplify the occurrence of rare events, and also create counterfactual scenarios described by the time series. Distributional-similarity (which we refer to as realism) as well as the satisfaction of certain numerical constraints are common requirements in counterfactual time series scenario generation requests. For instance, the US Federal Reserve publishes synthetic market stress scenarios given by the constrained time series for financial institutions to assess their performance in hypothetical recessions. Existing approaches for generating constrained time series usually penalize training loss to enforce constraints, and reject non-conforming samples. However, these approaches would require re-training if we change constraints, and rejection sampling can be computationally expensive, or impractical for complex constraints. In this paper, we propose a novel set of methods to tackle the constrained time series generation problem and provide efficient sampling while ensuring the realism of generated time series. In particular, we frame the problem using a constrained optimization framework and then we propose a set of generative methods including ``GuidedDiffTime'', a guided diffusion model to generate realistic time series. Empirically, we evaluate our work on several datasets for financial and energy data, where incorporating constraints is critical. We show that our approaches outperform existing work both qualitatively and quantitatively. Most importantly, we show that our ``GuidedDiffTime'' model is the only solution where re-training is not necessary for new constraints, resulting in a significant carbon footprint reduction.