 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFactX: Scalable Reasoning with Reliable Facts via Constrained Generation
Aug 23, 2025Knowledge gaps and hallucinations are persistent challenges for Large Language Models (LLMs), which generate unreliable responses when lacking the necessary information to fulfill user instructions. Existing approaches, such as Retrieval-Augmented Generation (RAG) and tool use, aim to address these issues by incorporating external knowledge. Yet, they rely on additional models or services, resulting in complex pipelines, potential error propagation, and often requiring the model to process a large number of tokens. In this paper, we present a scalable method that enables LLMs to access external knowledge without depending on retrievers or auxiliary models. Our approach uses constrained generation with a pre-built prefix-tree index. Triples from a Knowledge Graph are verbalized in textual facts, tokenized, and indexed in a prefix tree for efficient access. During inference, to acquire external knowledge, the LLM generates facts with constrained generation which allows only sequences of tokens that form an existing fact. We evaluate our proposal on Question Answering and show that it scales to large knowledge bases (800 million facts), adapts to domain-specific data, and achieves effective results. These gains come with minimal generation-time overhead. ReFactX code is available at https://github.com/rpo19/ReFactX.
SMART: Relation-Aware Learning of Geometric Representations for Knowledge Graphs
Jul 17, 2025Knowledge graph representation learning approaches provide a mapping between symbolic knowledge in the form of triples in a knowledge graph (KG) and their feature vectors. Knowledge graph embedding (KGE) models often represent relations in a KG as geometric transformations. Most state-of-the-art (SOTA) KGE models are derived from elementary geometric transformations (EGTs), such as translation, scaling, rotation, and reflection, or their combinations. These geometric transformations enable the models to effectively preserve specific structural and relational patterns of the KG. However, the current use of EGTs by KGEs remains insufficient without considering relation-specific transformations. Although recent models attempted to address this problem by ensembling SOTA baseline models in different ways, only a single or composite version of geometric transformations are used by such baselines to represent all the relations. In this paper, we propose a framework that evaluates how well each relation fits with different geometric transformations. Based on this ranking, the model can: (1) assign the best-matching transformation to each relation, or (2) use majority voting to choose one transformation type to apply across all relations. That is, the model learns a single relation-specific EGT in low dimensional vector space through an attention mechanism. Furthermore, we use the correlation between relations and EGTs, which are learned in a low dimension, for relation embeddings in a high dimensional vector space. The effectiveness of our models is demonstrated through comprehensive evaluations on three benchmark KGs as well as a real-world financial KG, witnessing a performance comparable to leading models
Privacy-Preserving Synthetically Augmented Knowledge Graphs with Semantic Utility
Oct 16, 2024



Knowledge Graphs (KGs) have recently gained relevant attention in many application domains, from healthcare to biotechnology, from logistics to finance. Financial organisations, central banks, economic research entities, and national supervision authorities apply ontological reasoning on KGs to address crucial business tasks, such as economic policymaking, banking supervision, anti-money laundering, and economic research. Reasoning allows for the generation of derived knowledge capturing complex business semantics and the set up of effective business processes. A major obstacle in KGs sharing is represented by privacy considerations since the identity of the data subjects and their sensitive or company-confidential information may be improperly exposed. In this paper, we propose a novel framework to enable KGs sharing while ensuring that information that should remain private is not directly released nor indirectly exposed via derived knowledge, while maintaining the embedded knowledge of the KGs to support business downstream tasks. Our approach produces a privacy-preserving synthetic KG as an augmentation of the input one via the introduction of structural anonymisation. We introduce a novel privacy measure for KGs, which considers derived knowledge and a new utility metric that captures the business semantics we want to preserve, and propose two novel anonymization algorithms. Our extensive experimental evaluation, with both synthetic graphs and real-world datasets, confirms the effectiveness of our approach achieving up to a 70% improvement in the privacy of entities compared to existing methods not specifically designed for KGs.
Ontological Reasoning over Shy and Warded Datalog$+/-$ for Streaming-based Architectures (technical report)
Nov 20, 2023



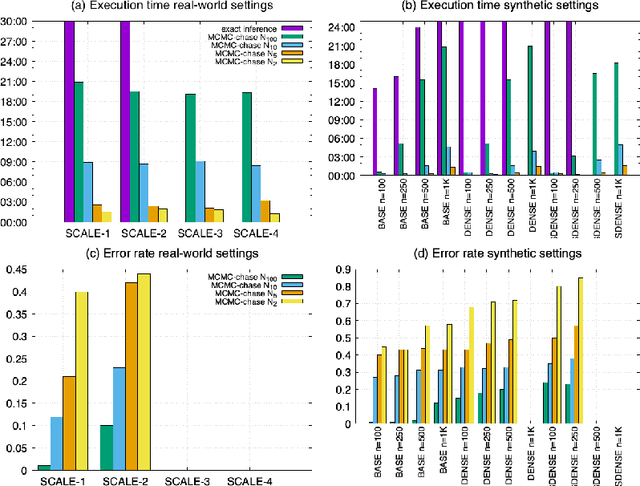
Recent years witnessed a rising interest towards Datalog-based ontological reasoning systems, both in academia and industry. These systems adopt languages, often shared under the collective name of Datalog$+/-$, that extend Datalog with the essential feature of existential quantification, while introducing syntactic limitations to sustain reasoning decidability and achieve a good trade-off between expressive power and computational complexity. From an implementation perspective, modern reasoners borrow the vast experience of the database community in developing streaming-based data processing systems, such as volcano-iterator architectures, that sustain a limited memory footprint and good scalability. In this paper, we focus on two extremely promising, expressive, and tractable languages, namely, Shy and Warded Datalog$+/-$. We leverage their theoretical underpinnings to introduce novel reasoning techniques, technically, "chase variants", that are particularly fit for efficient reasoning in streaming-based architectures. We then implement them in Vadalog, our reference streaming-based engine, to efficiently solve ontological reasoning tasks over real-world settings.
Fine-tuning Large Enterprise Language Models via Ontological Reasoning
Jun 19, 2023


Large Language Models (LLMs) exploit fine-tuning as a technique to adapt to diverse goals, thanks to task-specific training data. Task specificity should go hand in hand with domain orientation, that is, the specialization of an LLM to accurately address the tasks of a given realm of interest. However, models are usually fine-tuned over publicly available data or, at most, over ground data from databases, ignoring business-level definitions and domain experience. On the other hand, Enterprise Knowledge Graphs (EKGs) are able to capture and augment such domain knowledge via ontological reasoning. With the goal of combining LLM flexibility with the domain orientation of EKGs, we propose a novel neurosymbolic architecture that leverages the power of ontological reasoning to build task- and domain-specific corpora for LLM fine-tuning.
Swift Markov Logic for Probabilistic Reasoning on Knowledge Graphs
Oct 01, 2022
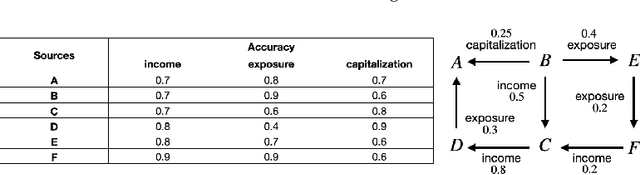

We provide a framework for probabilistic reasoning in Vadalog-based Knowledge Graphs (KGs), satisfying the requirements of ontological reasoning: full recursion, powerful existential quantification, expression of inductive definitions. Vadalog is a Knowledge Representation and Reasoning (KRR) language based on Warded Datalog+/-, a logical core language of existential rules, with a good balance between computational complexity and expressive power. Handling uncertainty is essential for reasoning with KGs. Yet Vadalog and Warded Datalog+/- are not covered by the existing probabilistic logic programming and statistical relational learning approaches for several reasons, including insufficient support for recursion with existential quantification, and the impossibility to express inductive definitions. In this work, we introduce Soft Vadalog, a probabilistic extension to Vadalog, satisfying these desiderata. A Soft Vadalog program induces what we call a Probabilistic Knowledge Graph (PKG), which consists of a probability distribution on a network of chase instances, structures obtained by grounding the rules over a database using the chase procedure. We exploit PKGs for probabilistic marginal inference. We discuss the theory and present MCMC-chase, a Monte Carlo method to use Soft Vadalog in practice. We apply our framework to solve data management and industrial problems, and experimentally evaluate it in the Vadalog system. Under consideration in Theory and Practice of Logic Programming (TPLP).
On the Relationship between Shy and Warded Datalog+/-
Feb 13, 2022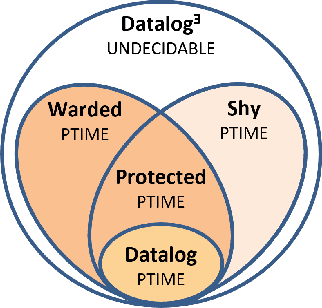
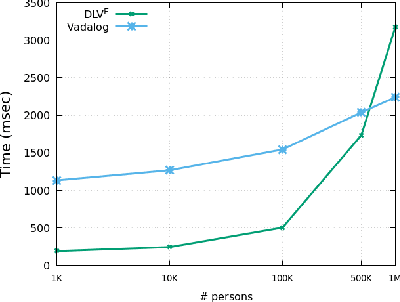
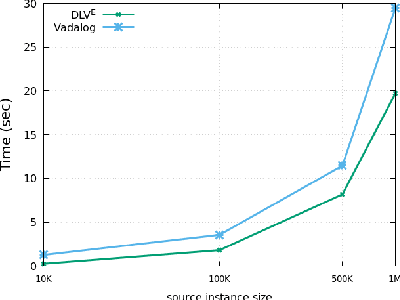
Datalog^E is the extension of Datalog with existential quantification. While its high expressive power, underpinned by a simple syntax and the support for full recursion, renders it particularly suitable for modern applications on knowledge graphs, query answering (QA) over such language is known to be undecidable in general. For this reason, different fragments have emerged, introducing syntactic limitations to Datalog^E that strike a balance between its expressive power and the computational complexity of QA, to achieve decidability. In this short paper, we focus on two promising tractable candidates, namely Shy and Warded Datalog+/-. Reacting to an explicit interest from the community, we shed light on the relationship between these fragments. Moreover, we carry out an experimental analysis of the systems implementing Shy and Warded, respectively DLV^E and Vadalog.
Query Evaluation in DatalogMTL -- Taming Infinite Query Results
Sep 21, 2021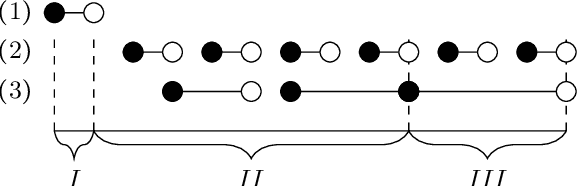
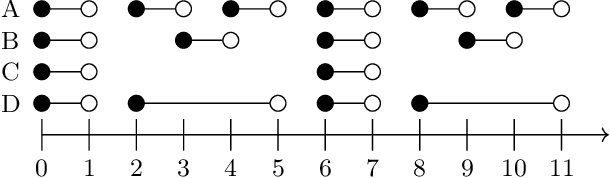
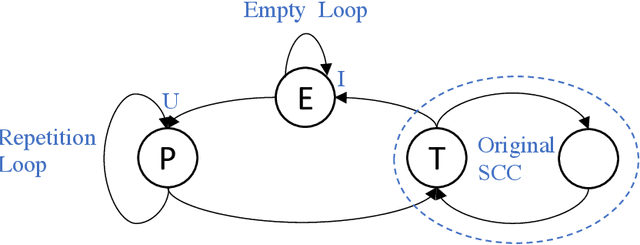
In this paper, we investigate finite representations of DatalogMTL. First, we introduce programs that have finite models and propose a toolkit for structuring the execution of DatalogMTL rules into sequential phases. Then, we study infinite models that eventually become constant and introduce sufficient criteria for programs that allow for such representation. We proceed by considering infinite models that are eventually periodic and show that such a representation encompasses all DatalogMTLFP programs, a widely discussed fragment. Finally, we provide a novel algorithm for reasoning over finite representable DatalogMTL programs that incorporates all of the previously discussed representations.
Harmless but Useful: Beyond Separable Equality Constraints in Datalog+/-
May 24, 2021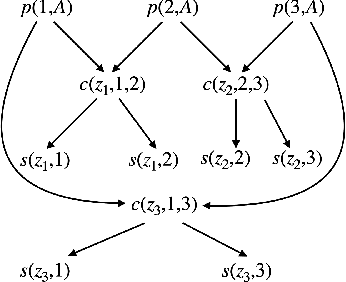
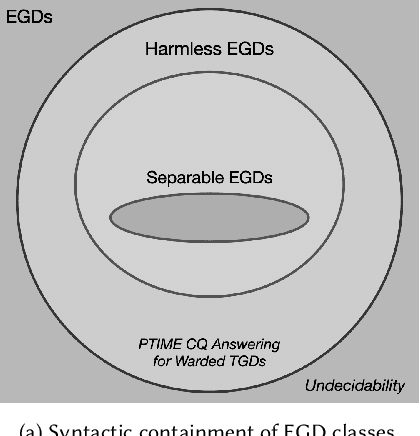
Ontological query answering is the problem of answering queries in the presence of schema constraints representing the domain of interest. Datalog+/- is a common family of languages for schema constraints, including tuple-generating dependencies (TGDs) and equality-generating dependencies (EGDs). The interplay of TGDs and EGDs leads to undecidability or intractability of query answering when adding EGDs to tractable Datalog+/- fragments, like Warded Datalog+/-, for which, in the sole presence of TGDs, query answering is PTIME in data complexity. There have been attempts to limit the interaction of TGDs and EGDs and guarantee tractability, in particular with the introduction of separable EGDs, to make EGDs irrelevant for query answering as long as the set of constraints is satisfied. While being tractable, separable EGDs have limited expressive power. We propose a more general class of EGDs, which we call ``harmless'', that subsume separable EGDs and allow to model a much broader class of problems. Unlike separable EGDs, harmless EGDs, besides enforcing ground equality constraints, specialize the query answer by grounding or renaming the labelled nulls introduced by existential quantification in the TGDs. Harmless EGDs capture the cases when the answer obtained in the presence of EGDs is less general than the one obtained with TGDs only. We conclude that the theoretical problem of deciding whether a set of constraints contains harmless EGDs is undecidable. We contribute a sufficient syntactic condition characterizing harmless EGDs, broad and useful in practice. We focus on Warded Datalog+/- with harmless EGDs and argue that, in such fragment, query answering is decidable and PTIME in data complexity. We study chase-based techniques for query answering in Warded Datalog+/- with harmless EGDs, conducive to an efficient algorithm to be implemented in state-of-the-art reasoners.
iWarded: A System for Benchmarking Datalog+/- Reasoning (technical report)
Mar 15, 2021
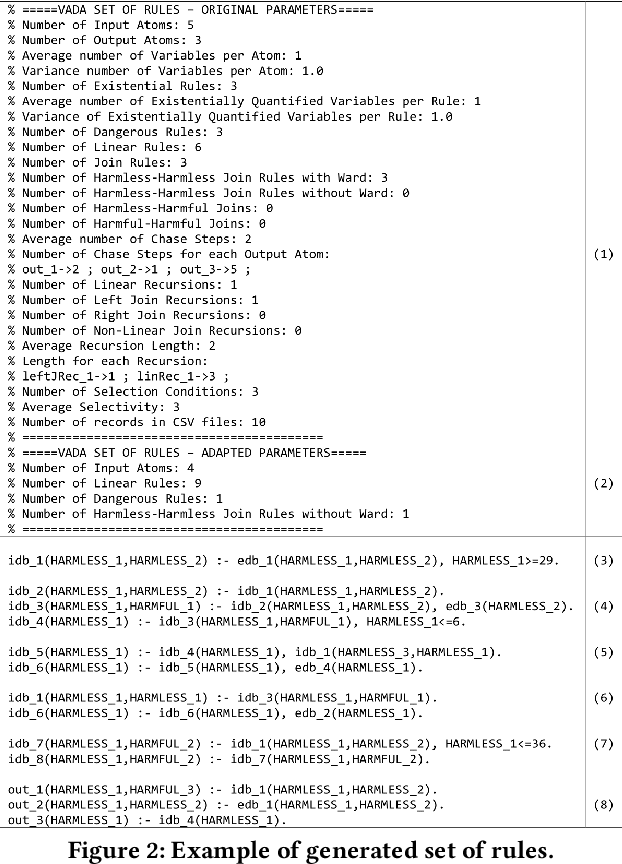


Recent years have seen increasing popularity of logic-based reasoning systems, with research and industrial interest as well as many flourishing applications in the area of Knowledge Graphs. Despite that, one can observe a substantial lack of specific tools able to generate nontrivial reasoning settings and benchmark scenarios. As a consequence, evaluating, analysing and comparing reasoning systems is a complex task, especially when they embody sophisticated optimizations and execution techniques that leverage the theoretical underpinnings of the adopted logic fragment. In this paper, we aim at filling this gap by introducing iWarded, a system that can generate very large, complex, realistic reasoning settings to be used for the benchmarking of logic-based reasoning systems adopting Datalog+/-, a family of extensions of Datalog that has seen a resurgence in the last few years. In particular, iWarded generates reasoning settings for Warded Datalog+/-, a language with a very good tradeoff between computational complexity and expressive power. In the paper, we present the iWarded system and a set of novel theoretical results adopted to generate effective scenarios. As Datalog-based languages are of general interest and see increasing adoption, we believe that iWarded is a step forward in the empirical evaluation of current and future systems.