 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching COVID-19 clinical research using graphical abstracts
Oct 06, 2023



Objective. Graphical abstracts are small graphs of concepts that visually summarize the main findings of scientific articles. While graphical abstracts are customarily used in scientific publications to anticipate and summarize their main results, we propose them as a means for expressing graph searches over existing literature. Materials and methods. We consider the COVID-19 Open Research Dataset (CORD-19), a corpus of more than one million abstracts; each of them is described as a graph of co-occurring ontological terms, selected from the Unified Medical Language System (UMLS) and the Ontology of Coronavirus Infectious Disease (CIDO). Graphical abstracts are also expressed as graphs of ontological terms, possibly augmented by utility terms describing their interactions (e.g., "associated with", "increases", "induces"). We build a co-occurrence network of concepts mentioned in the corpus; we then identify the best matches of graphical abstracts on the network. We exploit graph database technology and shortest-path queries. Results. We build a large co-occurrence network, consisting of 128,249 entities and 47,198,965 relationships. A well-designed interface allows users to explore the network by formulating or adapting queries in the form of an abstract; it produces a bibliography of publications, globally ranked; each publication is further associated with the specific parts of the abstract that it explains, thereby allowing the user to understand each aspect of the matching. Discussion and Conclusion. Our approach supports the process of scientific hypothesis formulation and evidence search; it can be reapplied to any scientific domain, although our mastering of UMLS makes it most suited to clinical domains.
Exploring the evolution of research topics during the COVID-19 pandemic
Oct 05, 2023
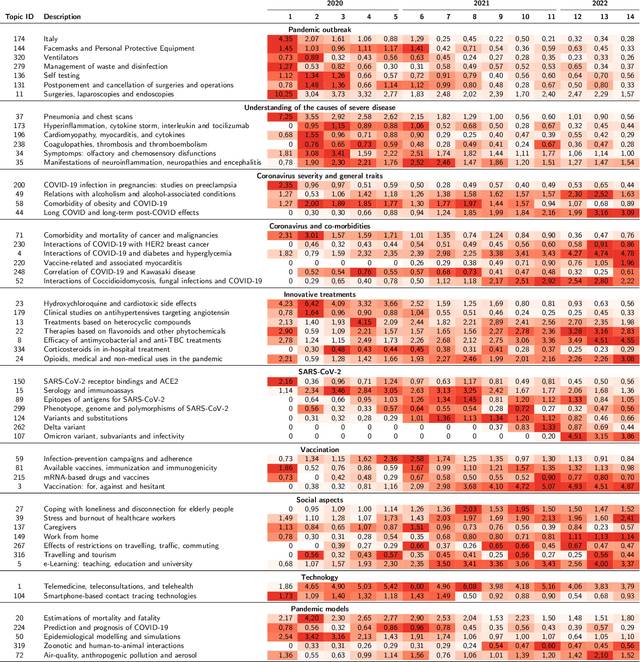


The COVID-19 pandemic has changed the research agendas of most scientific communities, resulting in an overwhelming production of research articles in a variety of domains, including medicine, virology, epidemiology, economy, psychology, and so on. Several open-access corpora and literature hubs were established; among them, the COVID-19 Open Research Dataset (CORD-19) has systematically gathered scientific contributions for 2.5 years, by collecting and indexing over one million articles. Here, we present the CORD-19 Topic Visualizer (CORToViz), a method and associated visualization tool for inspecting the CORD-19 textual corpus of scientific abstracts. Our method is based upon a careful selection of up-to-date technologies (including large language models), resulting in an architecture for clustering articles along orthogonal dimensions and extraction techniques for temporal topic mining. Topic inspection is supported by an interactive dashboard, providing fast, one-click visualization of topic contents as word clouds and topic trends as time series, equipped with easy-to-drive statistical testing for analyzing the significance of topic emergence along arbitrarily selected time windows. The processes of data preparation and results visualization are completely general and virtually applicable to any corpus of textual documents - thus suited for effective adaptation to other contexts.
Fine-tuning Large Enterprise Language Models via Ontological Reasoning
Jun 19, 2023


Large Language Models (LLMs) exploit fine-tuning as a technique to adapt to diverse goals, thanks to task-specific training data. Task specificity should go hand in hand with domain orientation, that is, the specialization of an LLM to accurately address the tasks of a given realm of interest. However, models are usually fine-tuned over publicly available data or, at most, over ground data from databases, ignoring business-level definitions and domain experience. On the other hand, Enterprise Knowledge Graphs (EKGs) are able to capture and augment such domain knowledge via ontological reasoning. With the goal of combining LLM flexibility with the domain orientation of EKGs, we propose a novel neurosymbolic architecture that leverages the power of ontological reasoning to build task- and domain-specific corpora for LLM fine-tuning.
A multi-layer approach to disinformation detection on Twitter
Feb 28, 2020



We tackle the problem of classifying news articles pertaining to disinformation vs mainstream news by solely inspecting their diffusion mechanisms on Twitter. Our technique is inherently simple compared to existing text-based approaches, as it allows to by-pass the multiple levels of complexity which are found in news content (e.g. grammar, syntax, style). We employ a multi-layer representation of Twitter diffusion networks, and we compute for each layer a set of global network features which quantify different aspects of the sharing process. Experimental results with two large-scale datasets, corresponding to diffusion cascades of news shared respectively in the United States and Italy, show that a simple Logistic Regression model is able to classify disinformation vs mainstream networks with high accuracy (AUROC up to 94%), also when considering the political bias of different sources in the classification task. We also highlight differences in the sharing patterns of the two news domains which appear to be country-independent. We believe that our network-based approach provides useful insights which pave the way to the future development of a system to detect misleading and harmful information spreading on social media.